

Tech trends only matter if they materially improve delivery speed, reliability, security, or unit cost within 12 months.
The risk isn’t missing the “next big thing,” but funding too many parallel initiatives that sound good in meetings but quietly increase coordination overhead and change-fail rates.
You don’t need perfect forecasts; you need disciplined adoption:
- Controllable bets with a single accountable owner
- A constrained blast radius to minimize systemic risk
- Measurable impact on DORA metrics and MTTR
- Clear cost implications
At a Glance: 2026 Trends and First Moves
Use this lens to decide what to scale, what to constrain, and what to defer until your organization is ready.
| Trend | Why It Matters | First 30–60 Day Move |
| Generative AI in the SDLC | Un-governed usage increases review noise, coordination tax, and change-fail risk | Constrain to 1–2 bounded workflows, baseline DORA metrics, measure impact before scaling |
| Agentic AI for defined workflows | ROI appears only when actions, permissions, and outcomes are tightly scoped | Standardize a single agent runtime with allow-listed actions and least-privilege identities |
| Enforceable AI governance | PDF governance fails; risk increases when AI usage becomes invisible | Define technical boundaries (where AI can run, what data it can access) and enforce in tooling |
| Platform-native productivity | Delivery risk lives between teams, not inside services | Ship one golden path from new service to production that’s faster than DIY |
| Kubernetes simplification | Flexibility directly increases incident load and MTTR | Standardize ingress, secrets, observability baseline, and GitOps deployment path |
| Observability standards | Inconsistent telemetry slows incident response and inflates cost | Enforce org-wide instrumentation contract and define SLOs for 3–5 critical journeys |
| Security automation | Manual security can’t scale with release volume and cloud surface area | Fully automate one security loop (e.g., credential leakage response) with clear ownership |
The Prioritization Lens
Try to keep prioritization simple. You need a repeatable triage model to evaluate emerging technologies before they become operational debt.
Rolling out AI-assisted code changes across a multi-team monorepo can feel like a speed win. But what happens next? Two sprints later, you’re untangling review fatigue, security exceptions, and noisy regressions.
Yes, everyone knows LLM adoption is picking up. But inevitability doesn’t equal urgency. Don’t fall for FOMO or hype.
The Five Filters for Funding a Trend
Use this lens to pressure-test any proposed initiative before it becomes operational debt.
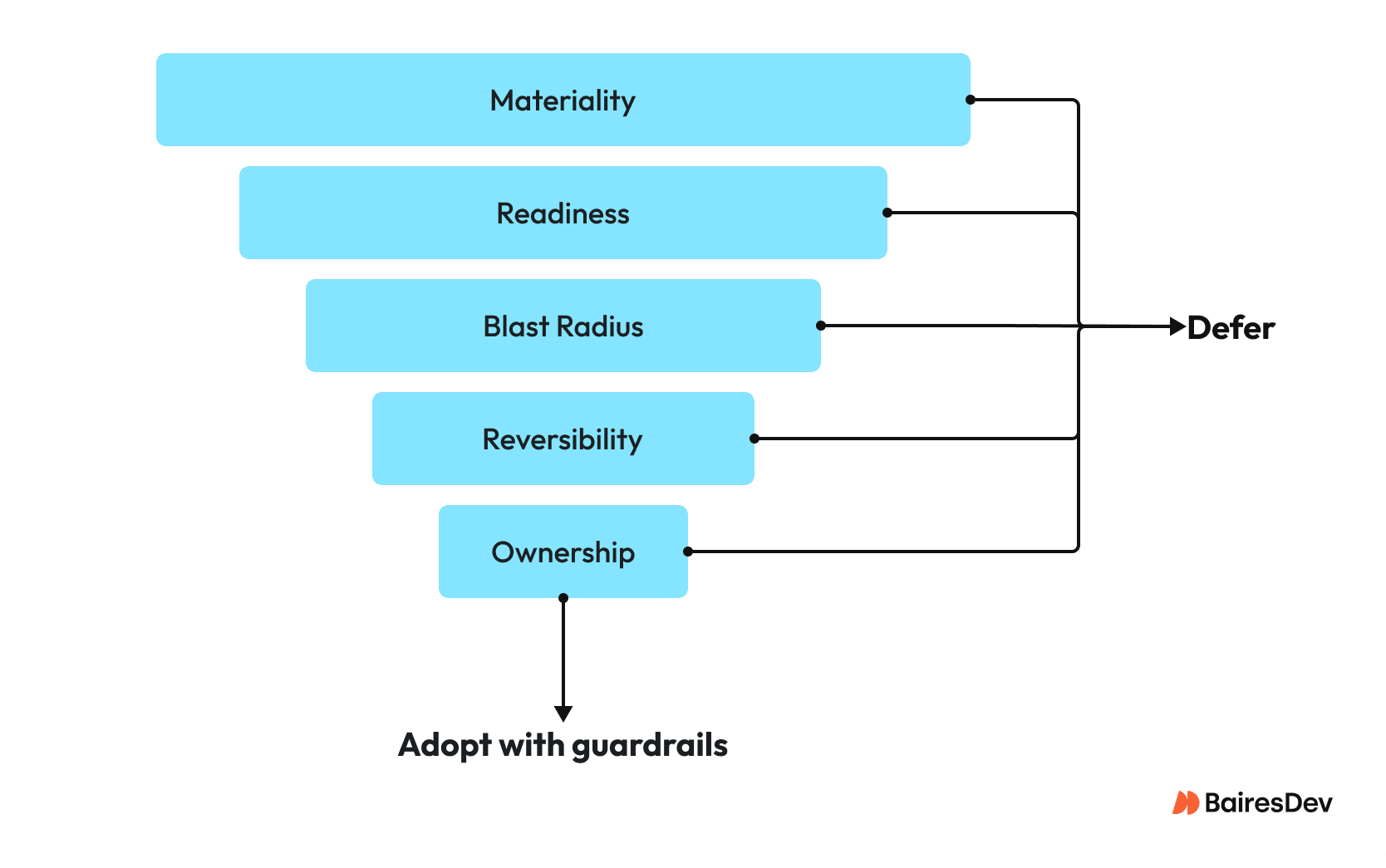
- Materiality: Will this move delivery speed, reliability, security, or unit cost?
- Readiness: Do you have the data, interfaces, and operational maturity to run it safely?
- Blast Radius: If it fails, what breaks and how quickly can you contain it? How big’s the rollback?
- Reversibility: Can you unwind this in days, or are you committing to months of migration debt?
- Ownership: Who’s accountable for both build and run?
This is why it’s a good idea to force a 30–60 day decision per trend. Adopt with guardrails, constrain to a bounded workflow, or defer.
Generative AI in the SDLC
Generative AI is no longer experimental. Gartner projects that by 2028, 75% of enterprise engineers will be leveraging AI code assistants.
Generative AI is already embedded in IDEs, CI pipelines, and documentation workflows. This means adoption isn’t optional, but organizations still need to do their best to avoid fragmentation.
The strategic choice isn’t whether to use AI, as that is already a done deal. The question is whether you standardize usage or allow unmanaged behavior and shadow AI to spread.
Where It Helps and Where It Hurts
Generative AI accelerates a lot of local tasks: scaffolding, summaries, documentation, and first-draft tests. Many organizations report productivity gains, though skeptics are quick to point out issues with such claims.
Either way, higher AI adoption often correlates with delivery instability. Basically, more output doesn’t guarantee better outcomes.
In multi-team environments, AI increases PR volume while lowering signal-to-noise ratio. The code may not be worse, but review fatigue, rework, and security exceptions increase. And that’s the best-case scenario, as it assumes the code is genuinely good.
For instance, in a platform organization shipping into a shared Kubernetes baseline, GenAI can increase PR output while lowering review quality. The resulting code isn’t necessarily bad, but the boost spawns a need for more coordination, rework, security exceptions, and flaky tests.
AI amplifies strengths and weaknesses. If your platform and governance foundations are shaky, AI will expose those cracks faster.
Guardrails That Protect Stability
Treat generative AI as an instrumented productivity feature:
- Constrain AI to bounded creation workflows (test generation, migrations, runbooks)
- Require explicit human ownership of all outputs
- Gate outputs through deterministic CI controls (unit tests, SAST, secret scanning)
- Measure impact on DORA metrics, not anecdotal productivity
If the change-fail rate rises, local gains don’t matter. You could end up shifting more work to another team.
Agentic AI for Bounded Workflows
Treat agentic AI as an automated teammate inside observable loops, not like a smarter chatbot.
If you don’t have stable CI, clear ownership, and reliable rollback paths, you’re not ready for autonomous agents.
ROI appears when inputs, actions, and outcomes are tightly defined and auditable.
Where AI Agents Create Value
The cleanest wins occur in machine-checkable workflows:
- Dependency upgrade PRs across services
- Helm updates validated by CI
- Draft incident summaries from logs
For example: an agent opens dependency PRs across services, runs CI, and flags only failures for review. Another drafts incident summaries strictly within the existing on-call workflow, thus summarizing history, not inventing remediation.
Agents should operate with:
- Short allow-listed actions
- Auditable tool calls
- Deterministic acceptance criteria
- Least-privilege identities
Before funding an agent program, assign a single team accountable for both build and run. Ensure actions are bounded (a short allow-list, not “do whatever it takes”), every tool call is auditable, and CI can deterministically accept or reject outputs.
Avoiding Tool Sprawl is Harder Than it Seems
Agent initiatives fail when teams wire up custom prompts, credentials, and infrastructure. This shadow platform creates hidden risk. Standardize one runtime, one execution path, tight identity controls, and rate limits.
If an agent needs broad access “just this once,” you’ve likely found your next postmortem.
This is easier said than done, as many teams are likely to chase quick wins and cut corners. Discipline and standardization are the way to go, even if they slow things down initially.
AI Governance Engineers Will Actually Use
Governance fails when it lives in PDFs. Invisible AI usage increases risk, especially around sensitive data and data sovereignty.
Security improves when the safe path is the fastest path.
Start With Enforceable Boundaries
Define non-negotiables:
- Where AI models can run
- What data sets they can access
- What outputs can ship
Enforce in IDE configs, network egress, and repo-level policies.
If your organization operates in regulated industries or handles customer-sensitive data, those guardrails aren’t optional.
For example, if your distributed teams work on customer-specific integrations, you need an explicit boundary for regulated data and customer code. Decide which repos can use external AI models, which must use an approved internal endpoint, and which can’t use GenAI at all. Put the boundary where engineers live, such as IDE configuration, network egress, and repo-level policy checks.
Make Risk Measurable
Treat AI like production infrastructure:
- Require lightweight evals for standardized workflows
- Gate outputs with deterministic checks
- Add AI-specific controls (no credential leakage, no regulated data exposure)
Log only what matters: model endpoint, identity, repo context, tools invoked, and whether output shipped.
If a behavior isn’t measurable, governance slows decision-making.
Developer Productivity Goes Platform-Native
Developer productivity isn’t a tooling shopping list.
Without paved roads, organizations accumulate fragmented pipelines, logging conventions, and deployment paths. During rapid growth, the cost shows up in MTTR and coordination drag.
An IDP becomes the control plane for how software is built and deployed.
When teams ship into shared infrastructure with inconsistent Helm charts, secrets handling, or alerting conventions, incident triage slows and change-fail rate rises.
The IDP as Control Plane
Golden paths should include:
- Standard CI workflows
- Policy-as-code gates
- Default OpenTelemetry instrumentation
- Embedded cost controls (quotas, instance families, right-sizing nudges)
Ship one high-volume path—“new service to production”—and make it measurably easier than DIY.
Track outcomes:
- Percent of services on golden path
- Platform ticket volume
- Change-fail rate
- Time to first production deploy
If teams ship faster but incidents rise, you’ve optimized locally and damaged the system.
Failure Mode: Paved Roads That Nobody Uses
IDPs fail when teams keep bespoke pipelines. If Platform builds a portal but product teams bypass it because the golden path is slower or missing critical integrations, standardization becomes optional.
The fix is not more documentation. It’s better design: make the golden path objectively better than the alternative.
Ship one high-volume path (“new service to production”) with CI, security scanning, deployment, dashboards, and a minimum reliability contract baked in (SLIs, alerts, runbook stub).
Track adoption through behavior metrics like percent of services on the paved path, platform ticket volume, and change fail rate.
Kubernetes, But With Fewer Foot-Guns
Kubernetes remains foundational infrastructure. Advantage now comes from reducing optionality. Every custom chart, add-on, or hand-rolled cluster increases operational load.
Rethink the idea that flexibility is free; it’s often just unmanaged debt.
The Case for Boring Defaults
Standardize managed defaults that make drift harder. Enforce:
- One ingress pattern
- One secrets flow
- One observability baseline
- One GitOps deployment path
Reduced choice buys reliability, simpler upgrades, and a smaller failure domain.
You get leverage from today’s cloud-native reality: Kubernetes adoption is mainstream, but teams are pushing back on the resulting complexity. An IDP simplifies what developers touch—even if the underlying stack remains complex.
What to Stop Doing
Avoid complexity that doesn’t materially improve reliability:
- Stop running service meshes everywhere by default: many organizations are reassessing the overhead versus the actual reliability gain.
- Don’t maintain hand-rolled clusters without regulatory necessity: move to managed services unless you have a unique regulatory requirement.
- Prevent teams defining cluster conventions independently: this creates a massive, splintered failure scope.
Fragmented infrastructure creates fragmented failure domains.
Observability Shifts From Tools to Standards
New tools won’t fix MTTR if instrumentation varies across teams.
Leverage comes from consistent telemetry:
- Service naming conventions
- Trace propagation standards
- Log correlation
- Shared SLO definitions
Define consistent signal shapes (service naming, HTTP and DB attributes, trace propagation, log correlation) so incident workflows behave predictably. Page only on violated SLOs. Use error budgets to force tradeoffs between shipping and stability.
Security Automation Becomes Mandatory
Manual security doesn’t scale with cloud growth or release velocity. If reviews depend on ticket queues, change velocity will outrun enforcement.
If security teams manually approve access requests or review every dependency bump, they’re adding drag instead of reducing risk.
You won’t audit your way to safety. Machines must enforce controls across infrastructure, identity, and supply chain.
Industry research shows materially lower breach costs in organizations with mature automation; IBM reports a global average breach cost at $4.88M, with roughly $2.2M lower costs where strong security AI and automation are in place.
Where Manual Security Fails
If controls depend on ticket queues, change velocity will outrun enforcement.
The pattern is consistent across identity, detection, response, and supply chain: Define expected state. Automate enforcement. Escalate exceptions only.
Where Automation Pays Off First
Start where loops close automatically:
- Credential leakage detection and revocation
- Dependency enforcement in CI
- Identity expiration workflows
- Supply chain validation
Where To Focus In 2026
Here’s how the trends break down by priority.

- Adopt with guardrails: IDP golden paths + Kubernetes simplification (fewer knobs, fewer bespoke pipelines).
- Adopt and standardize: OpenTelemetry-style observability standards tied to SLOs and cost controls.
- Govern tightly: Generative and agentic AI inside bounded, auditable workflows with least-privilege identities.
- Automate aggressively: Security response and supply chain controls in CI—not in ticket systems.
Before funding any initiative, require clear answers to four questions:
- What concrete problem are we solving?
- Which team is accountable end-to-end?
- What budget and time horizon are committed?
- What is the rollback and risk containment plan?
If all four questions can’t be answered in one meeting, defer.
Final Thoughts
Innovation is not about adopting more trends. It’s about discipline.
The organizations that win in 2026 won’t be the ones chasing every emerging tool. They’ll be the ones reducing variance, standardizing execution, and funding only the initiatives that measurably improve system outcomes.
Speed without stability is noise.
Modern without discipline is debt.




