

Containers address a stubborn enterprise problem: moving code from a developer’s laptop to production without last-minute surprises. Anyone asking what are containers receives a direct answer—they package application code, its runtime, and every required library into a self-contained image. That image behaves identically in any environment, so the nightly build runs the same way on a senior engineer’s workstation, a staging cluster, and a production node.
In enterprise software development, the certainty provided by containerized applications turns release cadence into a business advantage. The predictability of container technology keeps incident counts low, lets compliance teams sign off once instead of three times, and frees development teams to focus on features rather than environment drift.
In short, containers enable developers to deliver faster with fewer rollback meetings.
From Monoliths to Microservices: The Architectural Shift
A decade ago, many platforms shipped as monoliths. One change triggered a full build, hours of regression testing, and a risky midnight cut-over.
Containers encouraged a break-up into microservices: smaller components travel with their own dependencies, so faults stay local and teams work in parallel. An authentication service can run one language and framework, a billing service another, without conflict. This flexibility removes the “lowest-common-denominator” effect and accelerates refactoring of legacy codebases into modern, maintainable slices.
Scaling Delivery Across Teams and Environments
Consistency, not speed alone, defines elite delivery. An enterprise pipeline now spans laptops, shared test clusters, and globally distributed production nodes: vastly different computing environments with increasingly divergent underlying hardware.
With containerization, each stage consumes the exact same image, signed by the build server and verified by automated scans. Governance improves because leadership can audit a single artifact through its entire life cycle. Onboarding a new engineer or replicating a full-stack environment for disaster drills takes minutes instead of days, and unexpected configuration drift virtually disappears.
Containers and Virtual Machines: Understanding the Trade-offs
Both containers and virtual machines create isolation, but they solve different layers of the problem. The choice hinges on how much of the operating system must be reproduced and how hard the security boundary needs to be.
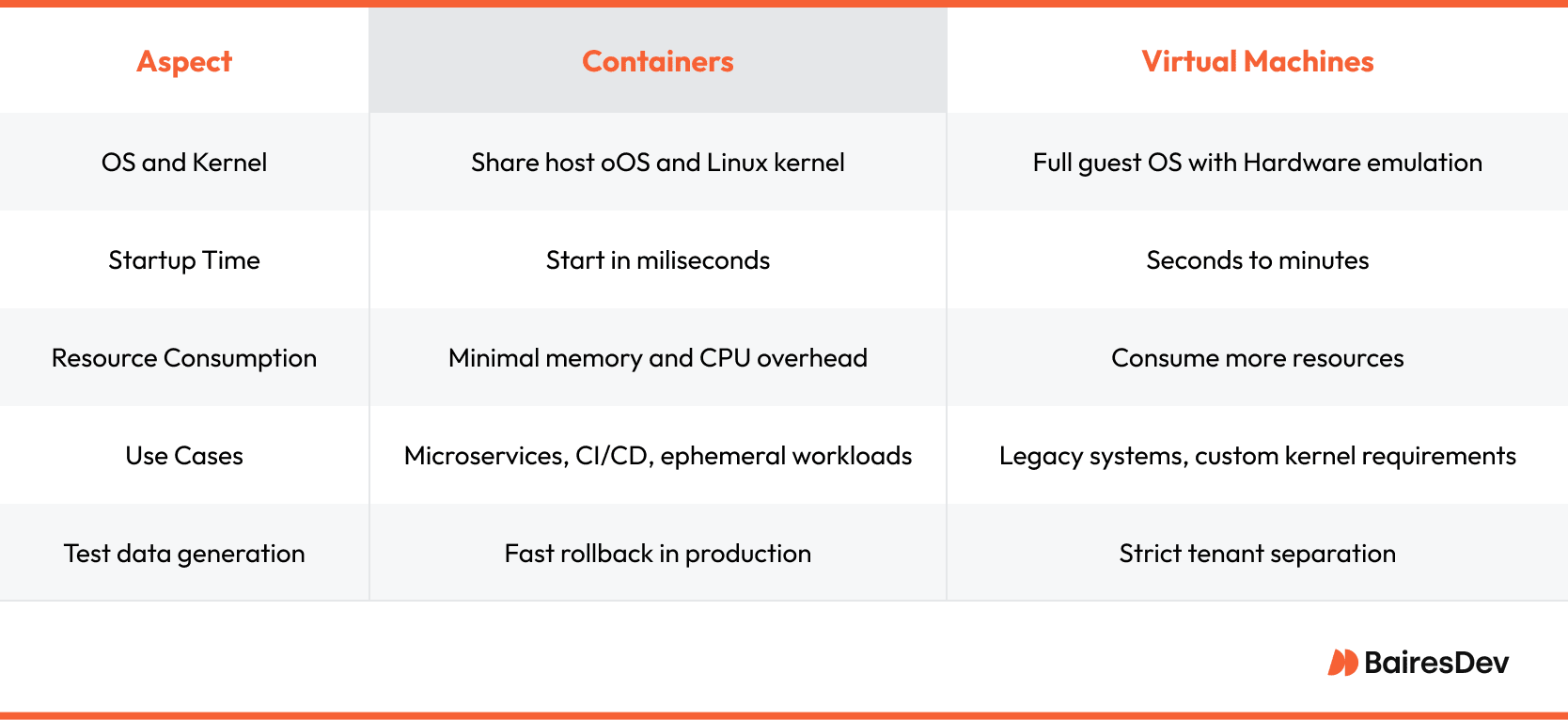
Virtual Environments Without the Overhead
A container shares the host OS and even the Linux kernel with its neighbors. Namespaces and control groups carve out process boundaries while adding only a thin veneer above the physical machine. Startup time is measured in milliseconds, memory footprints stay small, and thousands of containers can launch on a mid-range node.
This agility supports canary releases, granular auto-scaling, and blue-green style rollouts with minimal excess capacity. Security questions arise because the kernel is shared, yet hardened node pools, user namespaces, and mandatory access controls keep the operational blast radius narrow.
Where VMs Still Win
Virtual machines (VMs) emulate hardware, ship with a full guest operating system, and run on a hypervisor. Boot time and resource cost rise, but so does isolation. Workloads that need custom kernel modules, legacy operating systems, or firmware access still belong inside a VM. Certain compliance frameworks demand kernel-level segregation that containers cannot offer.
Many enterprises blend both layers: a small fleet of shielded VMs establishes tenancy boundaries, and each VM hosts multiple containers for the application tier. The result balances strong isolation with container density and release velocity.
Real-World Use: How Teams Deploy and Manage Containers
Success in production begins with an immutable artifact: the container image. It bundles binary code, configuration files, system libraries, and environment settings into a versioned snapshot that can be deployed easily on any compliant runtime. Build pipelines treat that image as the single source of truth, and every downstream tool respects its digest.
CI/CD, Batch Jobs, and Stateful Workloads
During continuous integration, a runner compiles the service, executes unit tests, and assembles the image. Static and dynamic scans check dependencies, and a registry signs the digest. Promotion through staging and production follows the same pattern, eliminating “but it works on my machine” issues
Batch processing benefits as well. A scheduler cam spin up multiple containers to execute overnight data transformations, then tear them down to avoid idle cost. Even stateful services survive in containers when matched with cloud-native storage classes. One policy engine governs stateless APIs, cron-driven analytics, and persistent databases, reducing cognitive load on the operations staff.
Supporting Multiple Environments: Cloud, On-Premises, Hybrid
Portability shows its value when an enterprise spans regions or providers. A retail platform pushes the same Docker image to an on-premises cluster for low-latency inventory checks and to two public clouds for burst capacity during seasonal spikes. Policy controllers define replica counts per zone, and container orchestration tools reschedule workloads when capacity fluctuates.
Hybrid flow works in reverse: if a cloud outage threatens service-level objectives, automation drains the public nodes and relocates workloads to spare on-site hardware until stability returns. Risk becomes a routing decision rather than a weekend migration project.
Docker Engine, Podman, and the Role of Container Images
The Docker Engine popularized modern workflows, yet alternatives such as Podman and containerd honor the same Open Container Initiative specification. Engineers build locally, tag the result, and push to a private registry; cached layers mean incremental edits complete in seconds. Image signing and digest locks guarantee provenance, and scanners flag outdated libraries before deployment.
Effective container management treats the registry as the source of truth, the orchestrator as the runtime, and the pipeline as the traffic cop in between. Each domain expert—developer, platform engineer, security analyst—owns a clear slice of responsibility while the platform stays coherent and secure.
Orchestrating Containers in Complex Environments
Container orchestration is the discipline that keeps hundreds, sometimes thousands, of running containers healthy while new versions roll through the pipeline. At scale, scheduling decisions, rolling updates, and self-healing must run on autopilot; otherwise, platform engineers spend their nights managing servers instead of improving the product.
An effective orchestration platform sits at the center of the container ecosystem, routing compute, storage, and policy without human intervention. Leaders who choose wisely gain predictable uptime and cost control; those who patch tools together invite configuration drift and fragile deployments.
Kubernetes and Beyond: Istio, Helm, ArgoCD
Kubernetes owns the mindshare for container orchestration, yet it is only the foundation. The open-source core handles pod scheduling and service discovery, but mature teams layer additional orchestration tools to simplify daily operations.
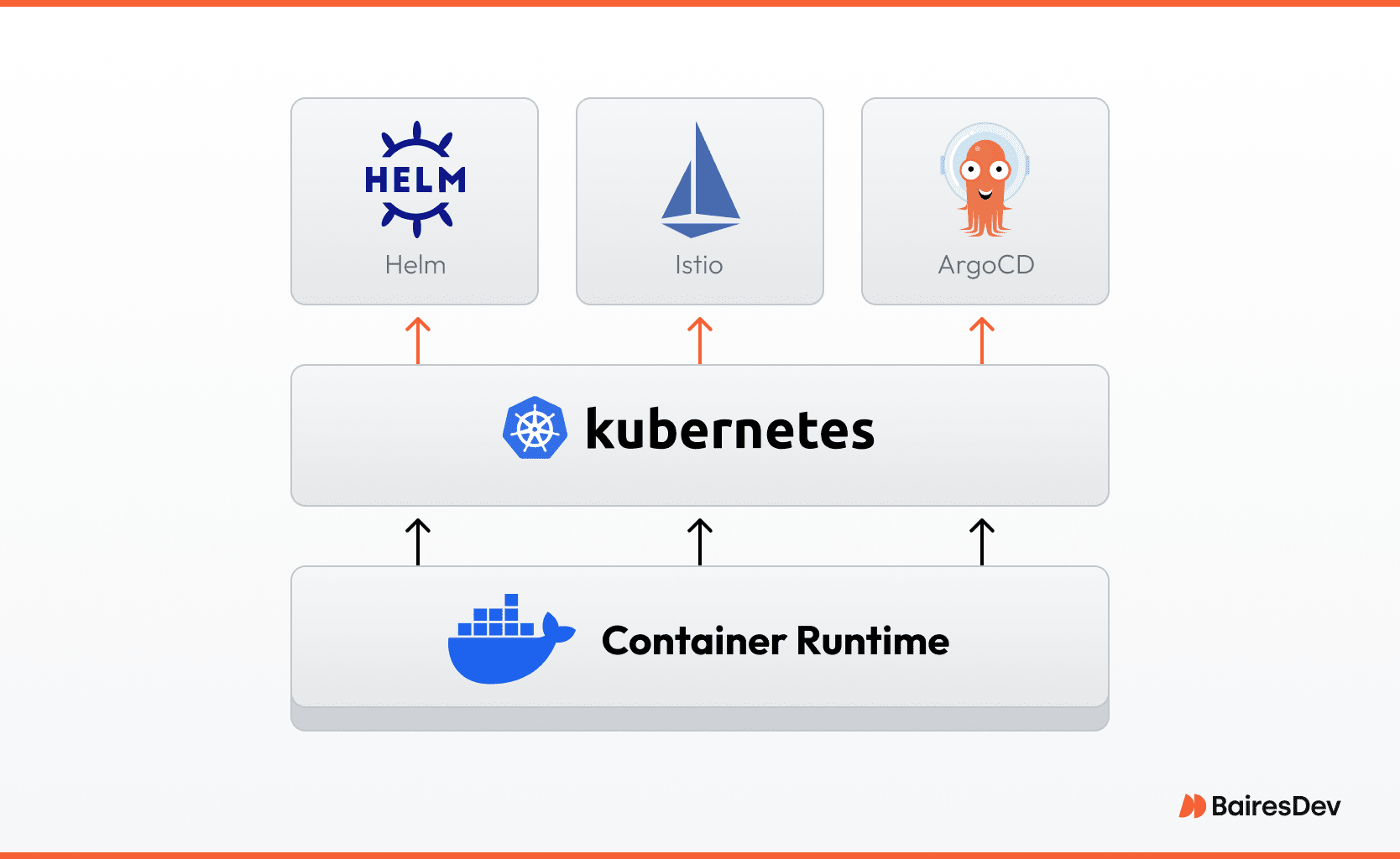
Helm packages complex applications into reusable charts, turning sprawling YAML into a single, versioned artifact. Istio delivers zero-trust traffic management, injecting mutual TLS and fine-grained policy without code changes. ArgoCD brings declarative continuous deployment, watching the Git repository for divergence and reconciling the cluster to the committed state.
Together, these underlying technologies form an open source platform that abstracts away repetitive automation and lets engineering focus on customer value rather than YAML gymnastics.
Declarative Deployments and GitOps at Scale
Declarative workflow flips the traditional mindset. Instead of pushing changes through ad-hoc scripts, the team writes the desired state into Git, signs the commit, and lets the controller pull the change into the cluster.
This pattern satisfies audit requirements because every environment mutation leaves a traceable commit hash. When multiple business units share a platform, Git branches and automated validations provide natural guardrails that prevent one team from misconfiguring another’s namespace. Rollbacks become trivial: revert the commit, and the controller prunes the failed release in seconds.
By aligning orchestration platform behavior with the same tooling developers use daily, the organization turns infrastructure into code, lowers cognitive load, and accelerates delivery across regions, clouds, and on-premises data centers.
Container Security
Shipping fast matters little if the platform leaks data. Container security starts with the same principle as any control plane: reduce the attack surface, isolate workloads, and monitor relentlessly. Standards bodies such as the Open Container Initiative and the Cloud Native Computing Foundation set baseline expectations, yet real protection emerges from day-to-day discipline.
Proper defaults for file permissions, minimal base images, and signed artifacts cut the window of exposure before the first pod even starts. Once workloads run, defense shifts to runtime controls that align with modern Linux containers and the shared host operating system kernel.
Vulnerability Isolation and Runtime Protection
Unlike virtual machines, containers share an OS kernel, so a breakout can compromise every service on that node. Namespaces, seccomp filters, and mandatory access controls isolate processes, but isolation requires rigorous policy. Image scanners in the pipeline block deployments with known CVEs, while runtime sensors detect drift and kill aberrant processes in milliseconds.
Network segmentation at the service mesh layer blocks east-west traffic that should never exist, and sidecar proxies insert mutual TLS so attackers cannot snoop unencrypted payloads. Telemetry feeds centralized analytics that correlate file changes, system calls, and packet flow in near real time, giving security teams the visibility they need to respond before customers notice anything amiss.
RBAC, Secrets, and Network Security Controls
Fine-grained Role Based Access Control ties every action (e.g., create, delete, scale) to a service account with least privilege. Cluster admins rotate credentials through an external vault, ensuring secrets never rest unencrypted on disk. Tokens expire quickly, and short-lived certificates reduce the impact if a key leaks.
Admission controllers enforce policy at deploy time, rejecting images that violate compliance or attempt to mount sensitive system resources. At runtime, ingress controllers terminate TLS, apply Web Application Firewall filters, and forward traffic only to vetted destinations. These controls, layered and automated, deliver an environment where rapid releases do not undermine resilience, allowing leadership to advance digital initiatives without inviting unnecessary risk.
Resource Efficiency Across Hardware Platforms
Container-based workloads run lean because containers share the host kernel and avoid duplicating guest operating systems. A single rack can serve a mix of CPU-bound microservices, GPU-accelerated analytics, and low-latency edge functions without wasting RAM on dozens of idle kernels.
The same principle scales down as well: branch offices or retail sites can host container-based applications on modest hardware, yet still meet central security standards. By limiting overhead, containers provide more useful work per watt, and that efficiency lands directly on the bottom line.
Supporting Diverse Teams with Standardized Infrastructure
Large organizations seldom operate on one stack. Finance depends on .NET, data science favors Python, an internal tool might still live in Ruby. By deploying containerized applications, organizations can insulate these differences. They wrap each runtime so teams commit to an image that works on any node, even when those nodes run different operating systems.
A common registry, a shared policy engine, related configuration files, and a unified dashboard replace ad hoc scripts scattered across teams. Developers keep their preferred toolchains while platform engineers enforce network policy, resource quotas, and vulnerability scanning from a single pane of glass. The result is predictable, secure, and flexible delivery that keeps autonomy high without splintering the platform.
What Engineering Leaders Should Take Away
A modern container environment is less about the buzz around Kubernetes and more about measurable business value. The primary benefits of containers, such as portability, repeatability, and fast recovery, map directly to the objectives of digital transformation.
When an upgrade can ship in minutes instead of days, new revenue experiments reach production faster. Whether the workload lands on Google Cloud, an on-prem cluster, or a partner’s data center, the same manifest applies, as if everything is running on one computing environment. Tool choice should follow this strategy: pick solutions that strengthen the loop from idea to production, not the other way around.
Enabling Developer Autonomy Without Losing Control
Governance need not slow application development. Policy as code, signed images, and automated rollout gates maintain a clear boundary between creative freedom and platform stability. Developers push features at will; the pipeline confirms linting, tests, and compliance before a single packet reaches the cluster.
Central teams sleep better because every containerized workload carries its own bill of materials, traceable back to a commit in Git. Once leadership sees this audit trail in action, the value of cloud native applications moves from theory to board level metric.
Frequently Asked Questions
How do containers affect compliance audits in regulated sectors?
Containers leave an immutable record from build to runtime. Auditors trace the digest back to a signed commit, verify that required scans passed, and confirm that runtime policies block privilege escalation. This chain of custody simplifies evidence gathering compared with traditional servers that drift over time.
Can legacy applications be containerized or should they be rewritten?
Many legacy services run fine inside a container, provided dependencies are bundled and persistent data is externalized. Rewriting offers deeper modernization, but wrapping the existing binary buys time and reduces migration risk while teams plan a full refactor.
What is the total cost of ownership compared with a VM fleet?
Per-workload cost drops because containers share the host kernel, allowing higher density. That translates to fewer cores, lower licensing fees, and diminished cooling demand. Savings scale with workload count, though orchestration expertise and observability tooling must be factored into the budget.
Does adopting Kubernetes lock the organization into one cloud provider?
No. Kubernetes abstracts compute and network primitives; manifests that deploy on-premises also deploy to Google Cloud or any major provider. Some managed services differ, but the control plane and workloads remain portable when built on open standards.
How does container networking impact east-to-west latency?
A service mesh introduces additional hops for encryption and policy, yet modern data planes process in microseconds. Locality-aware routing keeps traffic within the node or rack whenever possible, so most applications remain well inside performance targets.
Which skills should the operations team develop first?
Start with container fundamentals and move to orchestration, observability, and policy as code. A solid grounding in Git and continuous integration shortens the learning curve for everything that follows.




