

Every executive eventually faces the same Monday-morning surprise: a flawlessly demoed product collapses the moment real customers hit “Buy.” The post-mortem always sounds familiar. Logs show thread pools starved, queues ballooned, and database locks rippling through the stack. What’s missing is never a feature. It is an honest rehearsal of production traffic, which is exactly where structured software QA and testing services play a critical role in preventing these failures before they reach users.
Load testing turns that gap into a measurable discipline. Done well, it shifts conversations from guesswork to probabilities, from “we hope it holds” to “we can survive three times last quarter’s peak before we reach the first latency alarm.”
Well-publicized meltdowns reinforce the point. Healthcare.gov froze on launch day because concurrency models hadn’t met reality. A decade later, ticketing sites still stumble when concerts go on sale. These events aren’t edge cases; they are marketing victories turned operational failures. Load testing, embedded in the delivery pipeline, is how mature teams insure against that outcome. It complements functional testing, which answers whether a feature behaves, stress testing, which searches for a breaking point, and performance testing, which monitors system responsiveness and stability under expected conditions.
A good load testing process asks the more pragmatic question: will the entire service stay fast enough, long enough, for the business to make money while it’s under pressure?
Why Load Testing Matters for Enterprise Software
Downtime is rarely measured only in minutes. It shows up as financial penalties written into SLAs, as refunds issued to angry customers, and as engineering morale drained by emergency calls. For a high-traffic SaaS platform, even a short brownout can erase a month of revenue. Public-facing brands suffer double damage: lost transactions and a headline that climbs the search results faster than the outage page disappears.
Scale complicates the equation. Modern architectures spread work across microservices, cloud regions, and vendors. Performance issues in the payment gateway or identity provider can drag the entire user journey. Traffic no longer arrives in predictable waves either. A social-media mention from the right influencer or an unexpected API integration can triple load in minutes. Without realistic performance baselines, those spikes expose the weakest join in the chain.
There is also a competitive edge to consider. Users don’t consciously celebrate good performance; they simply stay. Fast response time, consistent application performance, and rock-solid stability form the quiet contract that keeps customers from clicking to the next tab. Engineering leaders who treat load testing as a first-class practice secure that advantage while cutting the risk budget for every release.
Core Concepts: What Load Testing Actually Measures
Effective load tests translate engineering data into business signals. Response time speaks to user patience and search-ranking weight. Throughput answers whether today’s infrastructure can handle tomorrow’s marketing plan. Concurrency reveals session handling and thread-pool limits that only emerge when hundreds or thousands of requests arrive at once.
Resource utilization links code to cost. Watching CPU, memory, and I/O patterns during a test tells you whether you need more nodes or a configuration change. A service that pegs a single database shard at 90 percent while the others coast at 40 percent isn’t ready for peak traffic. It is waiting to fail unevenly.
Load shape matters too. A gradual ramp over several hours (the classic soak test) exposes memory leaks and slow-burn connection exhaustion. A sudden peak load condition that simulates a push notification or flash sale validates autoscaling and back-pressure logic. Both patterns belong in a mature test suite because each surfaces different failure modes.
Types of Load Testing: A Business-Focused View
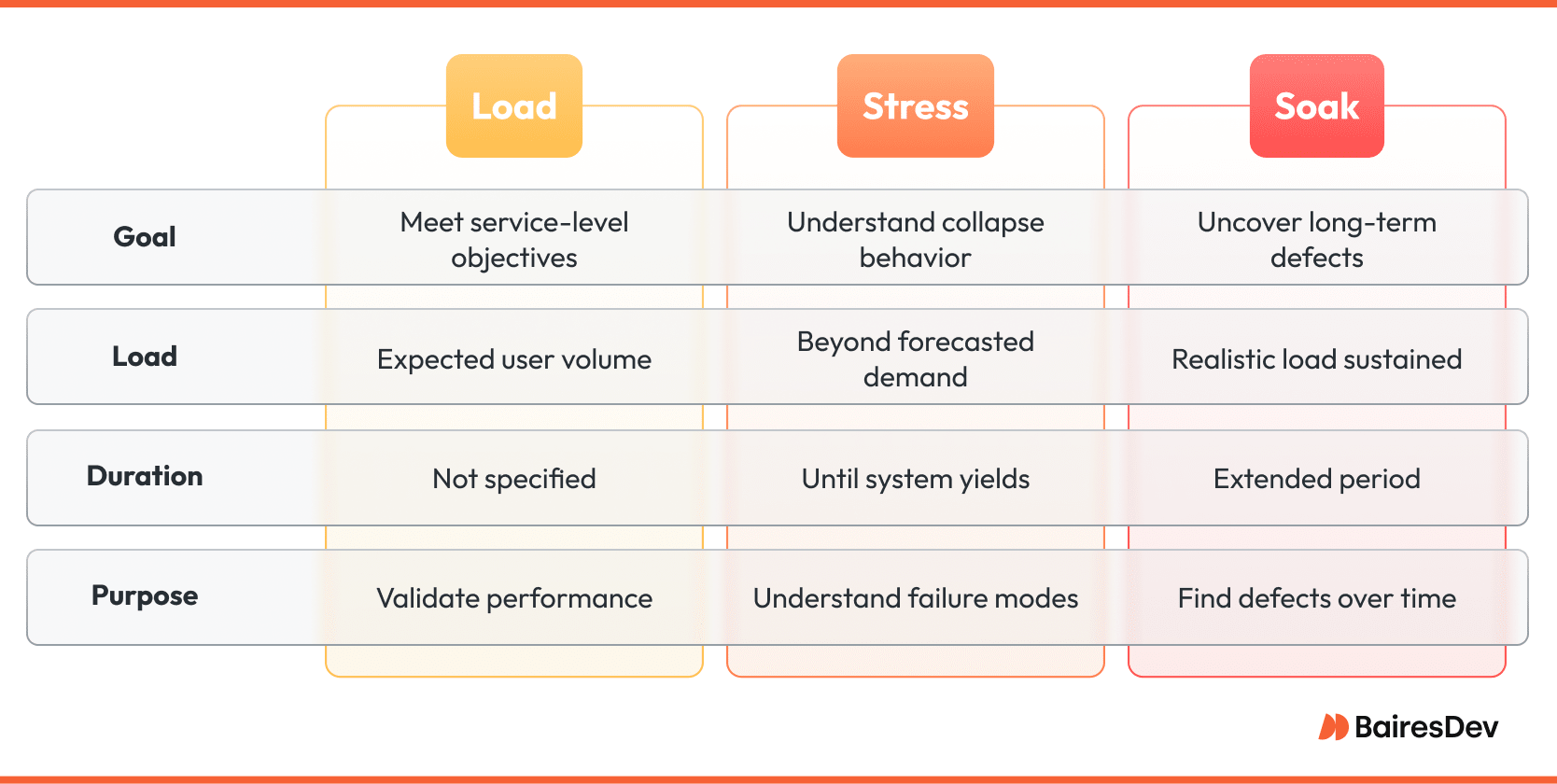
Load testing itself models expected concurrent user volumes: the Black Friday checkout wave, the Monday payroll run, the nightly data import. Success means meeting predefined service-level objectives without manual intervention.
Stress testing pushes well beyond forecasted demand until the system yields. The objective isn’t survival; it is understanding how collapse unfolds and whether recovery scripts, circuit breakers, and observability alerts work as advertised.
Soak testing sustains a realistic load for an extended period. It uncovers defects that only emerge after hours of operation: memory leaks, log file growth, or connection pool creep.
Finally, there is a strategic split between component and end-to-end tests. Component tests isolate a microservice early in the CI pipeline, catching regressions in minutes. End-to-end test scripts exercise the full production path, inclusive of third-party APIs, edge caches, and data stores. Skipping either view leaves a blind spot: code-level efficiency without architectural context, or vice versa. Experienced teams weave both perspectives into the release cadence.
When and Where to Load-Test
A performance budget loses its power if it is consulted only at the eleventh hour. Mature teams inject load tests into the same pipeline that compiles code, runs unit suites, and ships containers. A microservice can be exercised in a lightweight performance harness with every pull request; the test runs in minutes, flags obvious regressions, and blocks the merge before bad code spreads. Larger, production-shaped scenarios belong later in the delivery chain, usually in a staging cluster that mirrors topology, data volumes, and security policies.
Running load tests in staging is necessary but no longer sufficient. Traffic patterns change in ways marketing and product teams cannot always predict, so many organisations schedule controlled production probes. A dark-launch strategy, for example, routes a small percentage of live traffic to a new service instance while dashboards track latency deltas in real time. If numbers stay flat, the cut-over proceeds. If they drift, the flag flips back, and engineers iterate in daylight hours rather than fire-fight at midnight.
Timing matters as much as the test environment. Load profiles should precede events that amplify demand: major feature releases, new region rollouts, planned promotions. Executives rarely remove items from the roadmap to make room for performance testing, so the discipline must run on autopilot, triggered by pipelines, guarded by thresholds, and surfaced in a dashboard the leadership team already watches.
Choosing an Enterprise-Grade Load-Testing Tool
The tooling market splits along two axes: ownership cost and ecosystem reach. Open-source load testing tools such as JMeter or Locust offer deep scriptability and zero license fees. They shine in teams with engineers comfortable writing test logic in code and wiring the tool into bespoke CI runners. Commercial tools layer visual scripting, protocol recorders, and detailed analytics on top of the core engine. They reduce setup time and provide vendor support, which can be worth the invoice when a failed test stalls a regulatory launch.
Another filter is how comfortably a product slides into cloud-native workflows. Gatling, for instance, outputs results in a format that slots into Grafana dashboards and pushes alerts through Prometheus. JMeter relies on a plugin ecosystem that has, over the years, grown to cover MQTT brokers, gRPC endpoints, and even bespoke mainframe protocols. Popular load testing tools aimed at web traffic alone are no longer sufficient; APIs, message queues, and server-sent events all share the same latency budget in a distributed architecture.
Scalability remains the final gate. A modern load generator must fan out across regions, spin up hundreds of virtual workers per container, and report metrics without becoming the performance bottleneck it is trying to expose. Teams should prove a tool’s scale claims in a small spike test against a non-critical endpoint before they commit the platform to long-term contracts or deep automation.
Best Practices for Exercising Complex Systems Under Load
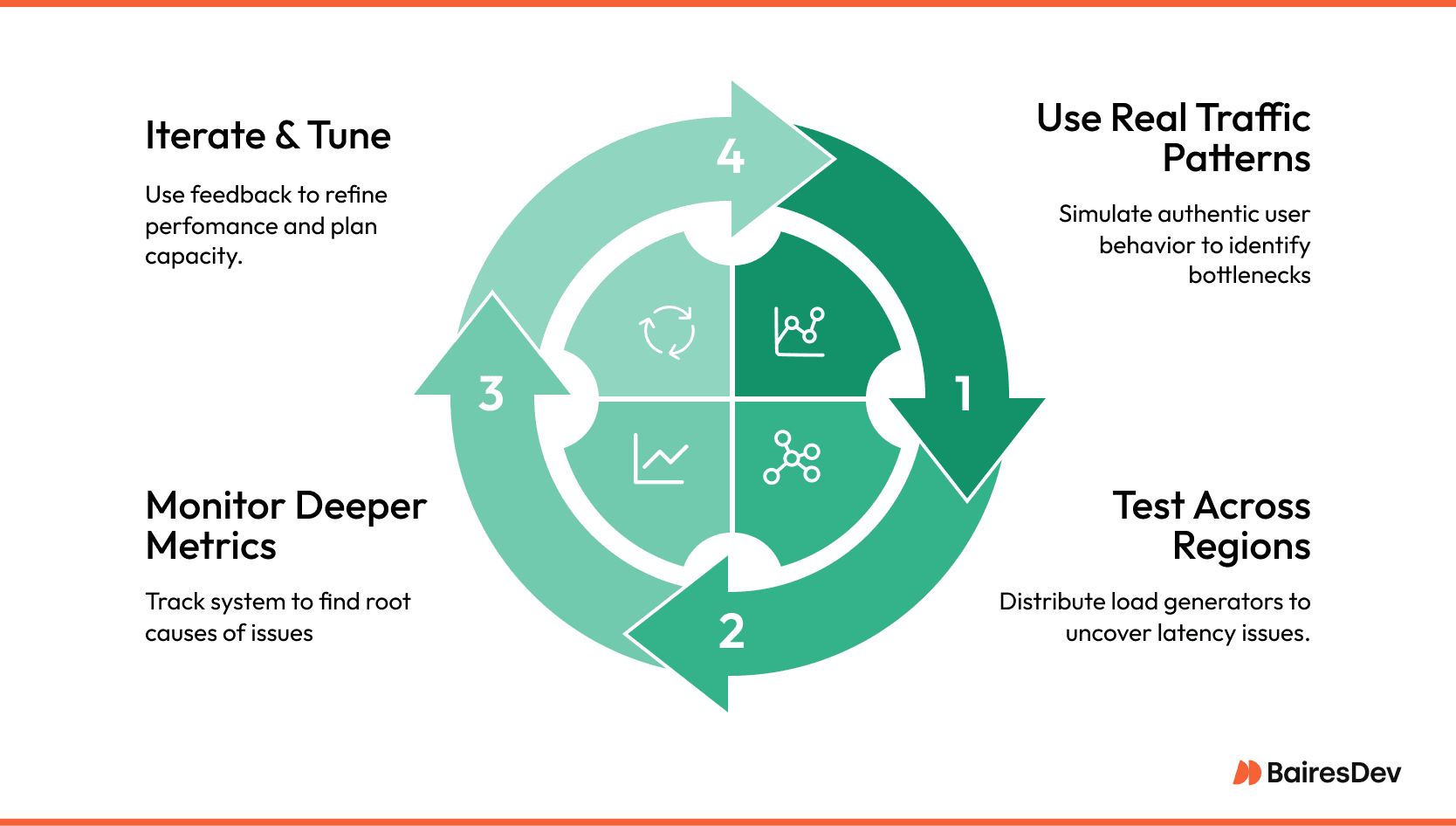
Realistic data trumps synthetic symmetry. Production analytics often reveal that ninety percent of users follow three happy-path flows, while the remaining ten percent bounce erratically across the UI. Mirroring that imbalance uncovers hotspots that a mathematically even distribution would hide. Engineers should capture live request traces, anonymise sensitive fields, and replay those payloads at scale.
Geography adds another wrinkle. A service that appears healthy when hammered from a single region can deteriorate once latency and edge-cache variability enter the equation. Spreading load generators across two or three continents surfaces DNS routing quirks, TLS handshake costs, and unexpected queuing inside cloud load balancers.
Instrumentation must watch more than P95 latency. Thread counts, garbage-collection pauses, database wait states, and disk I/O queues expose root causes rather than symptoms. When metrics move, alerts should fan out—first to the on-call engineer, then to a shared channel where developers, SREs, and even product owners can see the trend and discuss trade-offs in real time.
Finally, treat every run as a feedback loop. The test produces numbers, engineers adjust code or configuration, and the suite runs again. Over successive iterations, a service earns its performance envelope, and leadership gains a reliable forecast: how much traffic the platform can absorb today, and how much budget remains before the next marketing push.
Continuous, evidence-driven tuning replaces the old pattern of heroic midnight patches followed by anxious monitoring. That shift is the real payoff of disciplined load testing: fewer surprises, calmer launches, and a reputation for reliability that marketing departments cannot buy but customers reward with loyalty.
Common Pitfalls and How Seasoned Teams Avoid Them
The first mistake is deceptively simple: load-testing the wrong thing. Engineering groups sometimes point every concurrent virtual user at the home page because it is easy to script. Meanwhile the real choke point is an inventory API that hides behind a thin caching layer. Data from production observability tools should drive test design; scripts must mimic the paths customers follow, not the paths testers find convenient.
Another frequent misstep is trusting perfect laboratory conditions. Running a test from the same subnet as the application removes the messy variables that come with the public internet. Latency disappears, TLS handshakes feel instantaneous, and the test results paint a future that never arrives. Moving at least part of the generator fleet into different regions and subjecting them to normal network drag produces more accurate numbers.
Teams also trip when they treat test results as a verdict rather than a conversation. A failing metric should prompt a walkthrough that ends with a code change, a configuration tweak, or a revised capacity plan. If the graph lands in an archived folder and nobody acts, the next test will fail the same way. Load testing is diagnostic, not decorative.
Collaboration and the Continuous Feedback Loop
Performance work lives at the intersection of development, operations, and product strategy. When those groups share metrics in real time, the feedback loop tightens. A developer pushes a change, the pipeline runs a focused test scenario, and alerts are posted to the same channel where the feature discussion started. Everyone sees the latency bump. Everyone can weigh cost, schedule, and risk in the same five-minute window.
That transparency uncovers trade-offs early. Product owners learn the true cost of a new personalised dashboard. SREs see where autoscaling policies need a wider margin. Developers gain instant context for tuning queries or refactoring a chatty endpoint. The loop replaces finger-pointing with shared evidence, and outages become rarer because surprises become rarer.
Where Load Testing Is Headed
Three trends are reshaping the craft. First, machine learning is sneaking into test scenario creation. By mining historical traffic, new performance testing tools suggest realistic user journeys, complete with the odd edge case human testers forget to script.
Second, cloud providers are turning their global footprints into distributed load labs on demand. A team can spin up generators in São Paulo, Frankfurt, and Sydney, run a ten-minute surge, then tear everything down for pennies.
Third, real-user monitoring is merging with synthetic tests. Live telemetry feeds baseline numbers into the next scheduled run, ensuring that test data evolves as the customer base evolves.
These shifts do more than add knobs and gauges. They democratise performance engineering. A modest team can now achieve the kind of geographic reach and analytic depth that once required a room full of hardware and a six-figure licence. As the barriers drop, expectations rise. Customers will not accept a portal that slows to a crawl when a campaign goes viral, because competing services will have done their homework.
Closing Thoughts
Load testing used to sit at the end of the schedule, right before the go-live meeting, and often after the catering order had been placed. The modern software development lifecycle refuses that gamble. Teams run performance probes next to unit tests and security scans, feeding metrics to the same dashboards executives check over coffee. The practice is no longer a late-stage hurdle; it is a continuous barometer of release readiness.
Leaders who invest in realistic, automated, and collaborative load testing buy more than uptime. They purchase quiet launches, predictable capacity bills, and the freedom to let marketing dream big without fearing that the infrastructure will blush and faint. In an economy where attention is fickle and patience is microscopic, reliability is not a luxury. It is table stakes.




