

Production failures are inevitable in distributed systems, and most engineering teams have accepted that reality. What changes the cost is how fast the team can recover, which depends on whether failure modes were practiced before they appeared. This guide explains where chaos testing earns its place and what foundations need to be in place before it pays off.
Key Points
- Fast recovery often matters more than rare failures: Twenty 20-second outages are often less damaging than a single multi-hour outage.
- Chaos testing only works after observability and rollback discipline are in place; otherwise it adds noise without insight.
- Start with controlled outages in staging before scaling toward production, even though Netflix-style production chaos gets the headlines.
- MTTR is the metric that proves chaos engineering is working, since outage frequency alone doesn’t capture business impact.
Distributed systems fail in ways that traditional testing methods rarely capture. A deployment collides with a dependency timeout. A network partition interrupts writes mid-transaction. A storage layer behaves differently under real production load than it did in staging.
The most expensive system failures often come from interactions no one explicitly modeled ahead of time, especially during unexpected events in production environments.
That’s where chaos testing earns its place. Instead of assuming systems will behave predictably under stress, teams deliberately introduce controlled experiments and simulate failures to measure resilience, recovery speed, and operational readiness before customers experience the problem first.
The Power of Recovery Time
This is where MTTR (mean time to recovery) comes into play. Instead of asking, how do we prevent every failure, engineering teams must ask, how quickly can we recover when something inevitably goes wrong?
Imagine two companies:
- Company A experiences 20 outages per day, but each lasts only 20 seconds.
- Company B has a single outage that lasts 6 hours.
On paper, Company A appears less reliable. But in reality, their total downtime is under 7 minutes, while Company B loses nearly a full day. Fast recovery often matters more than low outage frequency in large-scale distributed systems.
How do you get better at recovering? You practice by inducing failure on purpose.
Controlled Failure Exercises
Start with a simple idea: schedule a known failure window, keep the specific fault hidden, and ask the team to restore the service as quickly as possible. These exercises simulate failures in a controlled environment that behaves much closer to a real production environment than controlled unit tests, while still protecting customers from unnecessary risk.
These controlled experiments surface gaps you won’t find with traditional testing methods:
- Alerts that fire late or don’t fire at all.
- Dashboards that show symptoms but not cause.
- Runbooks that exist but don’t work under pressure.
- Ownership confusion when multiple services degrade at once.
- Data integrity risks when retries collide with partial writes.
- Unexpected behavior caused by network latency, dependency failures, or hardware failures.
Controlled failure exercises also create experimental data you can use in in-depth analysis of system behavior and potential failure points. Once they stop producing surprises, chaos engineering becomes the next step.
Chaos Engineering in Practice
Chaos testing and chaos engineering go beyond “break something once.” The discipline focuses on running chaos experiments repeatedly, often in a production environment, to validate system quality under turbulent conditions and real-world scenarios.
Netflix popularized the approach with Chaos Monkey, built to randomly terminate instances in production so engineers can build services that tolerate instance loss. Random instance death happens in cloud infrastructure. Chaos Monkey turns that reality into a habit.
Netflix expanded the idea into broader failure simulations as well, including chaos experiments like Chaos Gorilla and Chaos Kong that test availability-zone and region-level impact across cloud infrastructure, proving the system’s capability to withstand turbulent conditions and major failures before customers experience them.
Chaos engineering follows a few core principles worth adopting even if you never run experiments in production environments immediately:
- Define the system’s steady state and establish what normal behavior looks like under stable conditions.
- Vary real-world events such as network delays, network outages, server crashes, dependency failures, and hardware failures.
- Run controlled experiments to validate system quality and measure how the system responds under stress.
- Minimize blast radius so learning doesn’t become an outage.
- Keep the program continuous so resilient systems improve through continuous improvement and reliability engineering practices.
Is Chaos Testing Right for You?
Chaos testing isn’t for everyone, at least not on day one.
If you’re still building basic CI/CD, lack reliable dashboards, or don’t have clear ownership for production incidents, start there first. Chaos testing will only add noise without observability, rollback discipline, careful planning, and documented recovery paths.
For complex, distributed systems with strict SLAs or regulatory exposure, though, chaos testing is quickly becoming standard practice. The more moving parts you have, services, regions, third-party dependencies, the more you need a deliberate way to identify weaknesses and discover system failure modes before customers do.
If your business can’t absorb unexpected downtime on critical workflows, chaos testing belongs on your near-term roadmap.
Building a Chaos Testing Program
You don’t need to dive in with full-blown chaos infrastructure on day one. Here’s a phased approach:
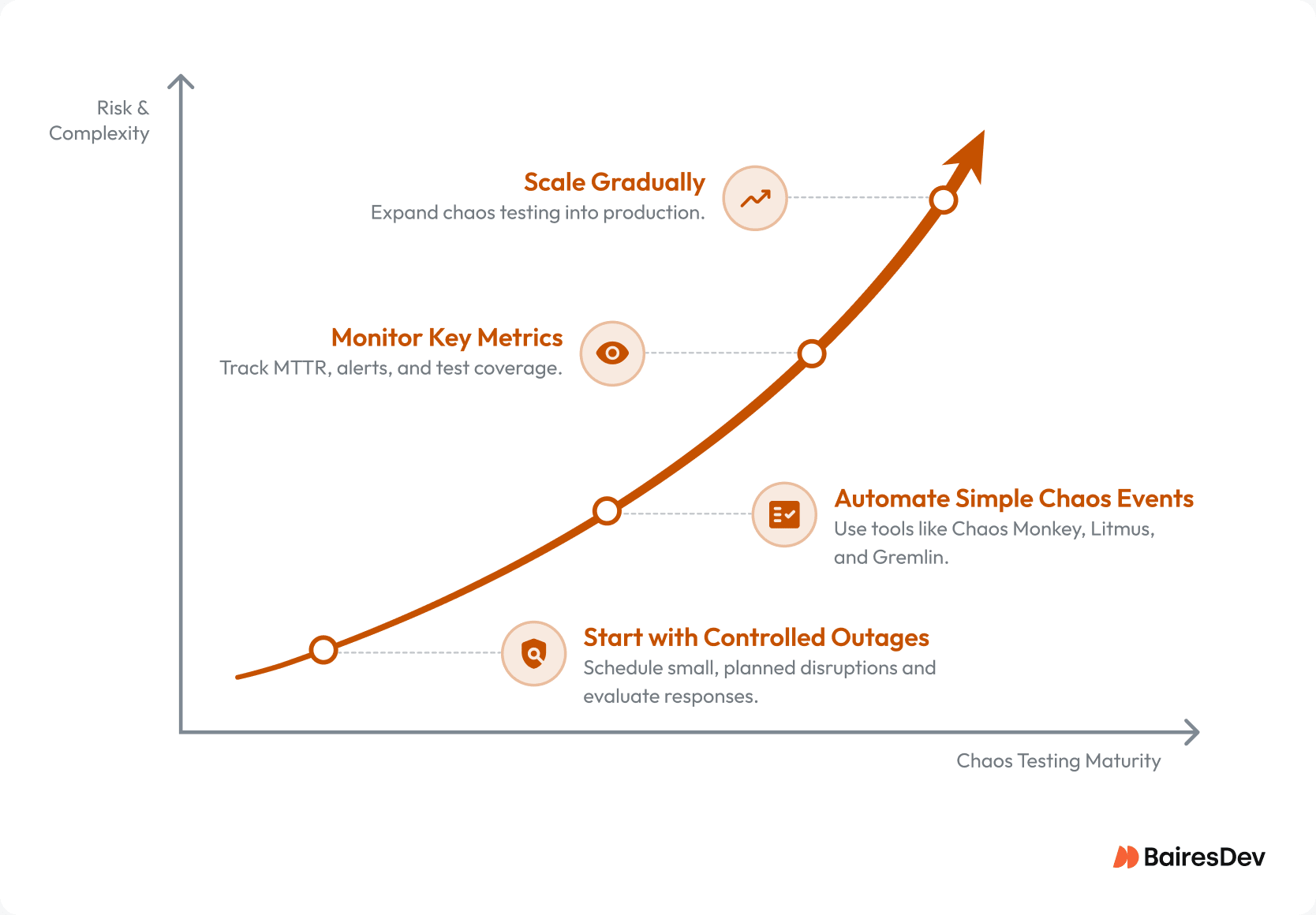
Start small with controlled, planned outages to see how your systems and teams respond. Then automate simple chaos events in staging, using tools like Chaos Mesh, Chaos Monkey, Litmus, or Gremlin—to build repeatable resilience tests. Measure operational outcomes such as MTTR, alert quality, automated recovery rates, and postmortem quality.
As confidence grows, scale into production carefully with clear guardrails, safe windows, notified stakeholders, and rollback plans. Automated rollback paths and verified recovery procedures should exist before expanding chaos experiments into customer-facing production systems.
Operational Resilience as a Capability
Modern businesses are software businesses. And when software breaks, revenue, customer trust, and operational continuity are at risk.
Chaos testing is all about exposing weaknesses before they reach customers. By training systems and teams to expect the unexpected, organizations can reduce operational risk while improving service reliability.
At BairesDev, we see chaos testing succeed when it’s treated as a continuous operational program rather than isolated experiments: defining steady-state metrics, choosing tools, implementing guardrails in staging and production, and integrating experiments into existing incident management and compliance processes.
Failure is inevitable. Outages are unpredictable. But with chaos testing, recovery is repeatable, and that might be the most valuable capability your business can build.




