

Machine learning once lived in prototype notebooks and internal demos. Today it drives credit-risk engines, supply-chain forecasts, and customer sentiment analysis across entire enterprises. As machine learning models mature, leadership faces a familiar but sharper challenge: turn promising research into governed, resilient, and continuously improving production services. That discipline is MLOps.
In practical terms, what is MLOps? It is a set of machine learning operations that links research teams to production infrastructure so ideas move from experiment to revenue without stalling. By treating the machine learning lifecycle as an engineering problem rather than an art project, MLOps gives data scientists a route to ship ML models quickly, re-train them safely, and prove their impact.
For VPs of Engineering and CTOs, it shortens feedback loops, controls risk, and exposes clear metrics instead of black-box promises. For engineers and data scientists, it replaces fragile hand-offs with reproducible workflows, enabling faster iterations, clearer ownership, and fewer late-stage firefights in production.
Why MLOps Exists
Early machine learning projects followed a “throw it over the wall” pattern. A data science group would train and retrain models, export weights, and asked operations to “make it run.” The hand-off often failed. Dependencies changed, data pipelines drifted, and nobody owned ongoing model training once the first version shipped.
DevOps development services practices solved many of these issues for application code, yet they fell short for statistical products that learn continuously. A neural network can degrade simply because user behavior evolves, not because the binary changed. Regulators also now demand lineage: leaders must show which dataset, feature set, and hyper-parameters produced every customer-facing prediction.
MLOps answers these pressures through automated testing of data as well as code, policy-driven model monitoring, and versioned artifacts that can be rolled back or reproduced on demand. By embedding these controls into everyday pipelines, engineering and data science teams replace ad-hoc interventions with repeatable workflows that match enterprise expectations for uptime, auditability, and speed.
Core Components of the MLOps Lifecycle
The MLOps lifecycle mirrors classic software delivery while honoring the probabilistic nature of machine learning systems.
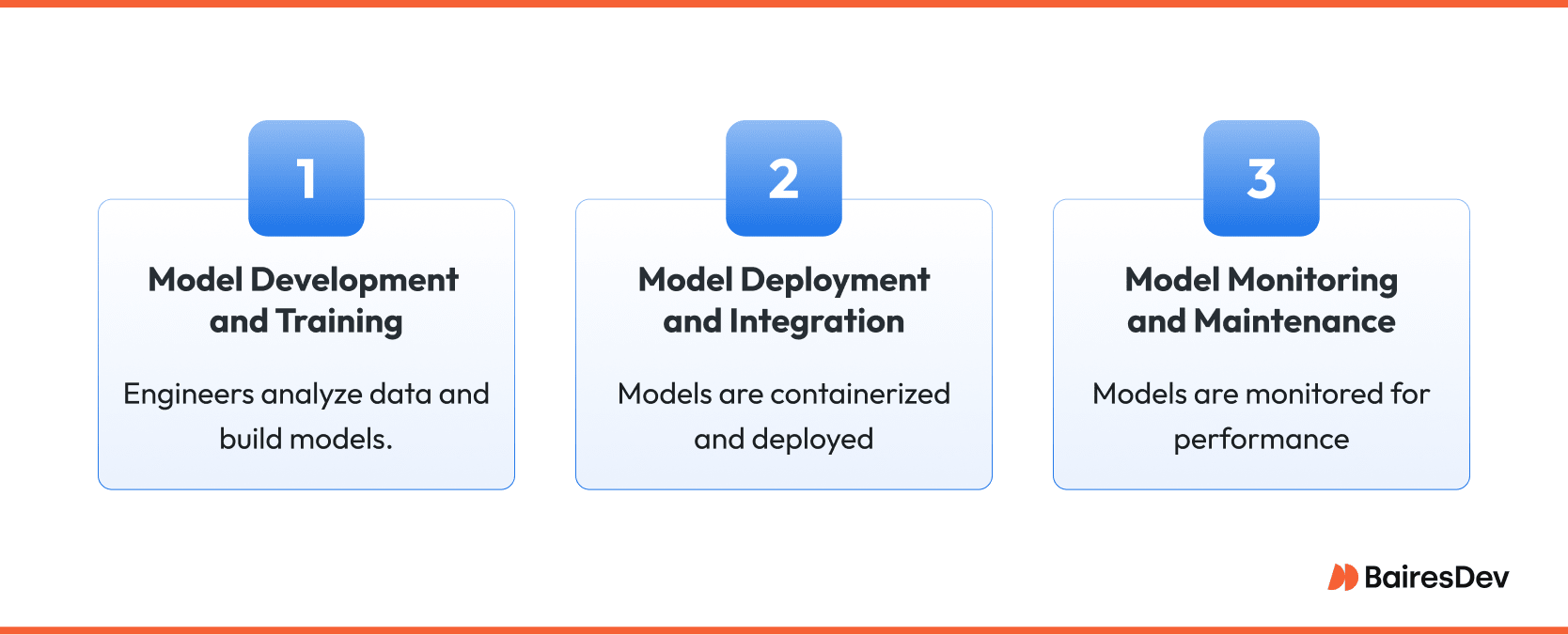
Model Development and Training
Work starts with raw data. Machine learning engineers perform exploratory analysis, extract reliable features, and build candidate architectures. Every step is logged to support experiment tracking: source dataset snapshots, code revisions, hardware configurations, and metrics.
Reproducibility is crucial, yet creativity must remain unblocked, so successful teams automate boilerplate, such as data validation, environment build scripts, and baseline benchmarks, while allowing researchers to iterate rapidly. Once model performance hits the target, it passes into a staging area that mirrors production network rules and security controls.
Model Deployment and Integration
Deployment extends continuous integration to statistical artifacts. A versioned model is containerized, packaged with its feature schema, and promoted through gated environments by the same CI/CD engine that ships application code. Hooks run canary tests against live traffic, measure latency, and verify prediction ranges before full release.
Because many enterprises operate hybrid clouds, deployment workflows treat infrastructure as code, selecting the correct GPU fleet or serverless endpoint via configuration rather than manual tickets. This approach keeps rollout time predictable and rollback immediate.
Model Monitoring and Maintenance
After release, real-world data becomes the test. Streaming dashboards watch for data drift, concept drift, and out-of-bounds confidence scores. When degradation surfaces, the machine learning pipeline triggers automated retraining or alerts owners to refresh feature logic.
Crucially, monitoring spans business KPIs, not only technical metrics: false-positive rates in fraud detection, revenue impact of recommendation quality, or compliance thresholds for fairness. Each retrain produces a new, immutable model version that flows back through development and deployment checkpoints, closing the loop without disrupting service.
Organizational Impact and Best Practices
To operationalize machine learning at scale, organizations must rethink team structures, governance models, and the cultural mechanics that sustain delivery.
Aligning Teams and Roles
MLOps changes who owns what, and it forces clarity that traditional silos often obscure. Data scientists still explore algorithms and craft features, yet their work lands inside a delivery pipeline run by ML engineers who treat models as deployable artifacts. Software engineers contribute service code and reusable libraries, while operations teams maintain the runtime stack and observability tools.
Success comes when these groups share the same backlog, the same sprint cadences, and a single definition of done that includes performance metrics in production. Leadership fosters this alignment by standardising processes: a common repository for code and data artefacts, a uniform set of quality gates, and mandatory peer reviews that cross team boundaries.
Clear lanes reduce hand-offs, and shared metrics, such as deployment frequency, mean time to detect model drift, or retraining lead time, turn collaboration into measurable outcomes. The result is faster delivery of reliable machine learning models and fewer late-stage surprises for business stakeholders.
MLOps as a Compliance and Governance Layer
The regulatory lens on AI is sharpening. Financial regulators ask for lineage reports that trace every prediction back to the raw dataset and the commit hash of the model code. Privacy statutes require deletion or re-masking of sensitive features when customer consent changes. Ethical review boards expect bias audits and proof of mitigation steps.
MLOps satisfies these demands by embedding governance directly into the ML pipeline. Each trained model receives a unique identifier, versioned metadata, and immutable links to the data snapshot used for training. Audit logs capture who triggered a retrain, why thresholds changed, and whether validation tests passed. When an investigation arises, teams can recover previous versions in minutes instead of days.
Governance also extends to automated rollbacks if a new model degrades performance or violates fairness constraints in live traffic. By treating compliance as a first-class requirement, engineering leaders protect revenue, reputation, and customer trust while still moving at the pace modern markets demand.
Tooling and Platform Considerations
Enterprises have two strategic paths: roll their own MLOps stack or adopt a managed platform. A custom pipeline offers fine-grained control and can integrate deeply with existing DevOps tooling, yet it demands significant upkeep and specialised talent.
Managed platforms such as MLflow, SageMaker, Dataiku, or Run:ai bundle experiment tracking, automated testing, model tuning, and one-click deployment into a coherent interface. They also abstract away GPU orchestration and storage management, which frees scarce engineers for higher-value work. The choice hinges on scale, compliance posture, and available skills.
Regardless of path, leaders should evaluate tools against a short set of enterprise-grade criteria: native support for CI/CD, granular role-based access control, seamless hand-off between development and production clusters, and extensible hooks for custom validation logic. Strong integration with existing AI infrastructure and logging systems avoids shadow pipelines that erode transparency. Cost models matter too; some cloud services charge by idle notebook hours or inferencing time, fees that can balloon without rigorous monitoring.
Finally, remember that no platform is bulletproof. Even with best-in-class software, sustainable MLOps depends on disciplined engineering practices, consistent data contracts, and a culture that values observable, repeatable workflows over one-off heroics. A tool merely accelerates what the organisation already does well. Invest accordingly.
Enterprise-Level Implementation Strategy
Rolling MLOps into a large organization is less about purchasing a platform and more about reshaping how work flows from whiteboard to production. Leaders who succeed approach the rollout in deliberate stages rather than a single big-bang migration.
From Proof of Concept to Production
Most enterprises already have scattered notebooks that forecast demand or rank leads. The first task is to surface those experiments, catalogue the valuable ones, and retire the rest. A small enablement squad then hardens the surviving models by wrapping them in APIs, containerising the code, and wiring automated data validation into the intake path. Version control applies not only to the source code but to the training data and the feature schemas. Legal and security stakeholders join early to approve encryption settings, retention periods, and audit logging.
Once a reproducible training pipeline exists, the squad templates it so other teams can press a button and spin up identical scaffolding. Governance is embedded from day one, so no team can bypass lineage tracking or model registration. The organisation now has a repeatable pattern rather than a collection of artisanal heroes.
Metrics That Matter
After the first few production launches, enthusiasm tends to outpace clarity. A dashboard that shows nothing but prediction accuracy is no help when a finance model spikes cloud costs or a recommendation engine drifts into bias territory.
Mature MLOps programmes track three metric families:
- Operational health: build success rate, deployment frequency, and mean time to roll back.
- Data and model fidelity: drift scores, outlier rates, and percentage of predictions inside approved confidence bands.
- Business impact: incremental revenue, cost avoidance, or risk reduction attributed to a model version.
Each metric ties back to a single source of truth in the pipeline, so executives can drill down from a quarterly key result to the feature that shifted it. When a new metric becomes mission-critical, engineers add it to the validation suite as code rather than relying on wikis or memory.
Conclusion
Machine learning can no longer live in prototype mode. The moment model predictions affect credit limits, pricing decisions, or patient outcomes, they must obey the same rigor that has long governed application software. MLOps provides that rigor without choking experimentation. It aligns data scientists, ML engineers, and operations staff under a single delivery rhythm, backed by reproducible pipelines, automated tests, and real-time monitoring.
The payoff is measurable: faster deployment of new models, shorter recovery when metrics drift, and a provable line between algorithmic decisions and business objectives. Companies that invest early in MLOps maturity turn research speed into competitive leverage while reducing the compliance headaches that sink late adopters.




