

Key Points
- Framework choice is not a tooling popularity contest.
- Training, development, and production ops need separate standards because they fail in different ways.
- Most AI stack problems occur at handoffs.
- The best stack is the one your team can support, govern, and roll back under real production pressure.
A common assumption is that picking a popular framework with strong community support buys you safety. That’s not always the case. Popularity won’t solve your hardest problems: upgrade churn across dozens of services, inconsistent prompt and retrieval logic, GPU cost controls, or proving what ran on what data under what approvals.
In a large organization, framework choice is really an operating contract. If you don’t separate concerns up front, you’ll standardize the wrong layer and sign your platform team up for permanent integration work.
Avoid the Popularity Contest Trap
If you treat AI framework choice like a popularity contest, you run the risk of standardizing the wrong thing.
Let’s get out of the weeds. You’re standardizing a contract across teams, like an MSA that governs APIs and runtime. It also defines pager duty and audit controls. Imagine one product team picks a fast-moving GenAI library, another team trains in PyTorch, and your platform ends up on-call for a brittle chain of dependencies you never agreed to own.
You need to challenge the idea that open source guarantees flexibility and lowers risk. In practice, flexibility without a contract just moves complexity into integration, upgrades, incident response, and so on.
Before you pick winners, answer four questions: What interfaces will you support and version? Who owns on-call for each layer? What security gates are non-negotiable? How will you handle upstream churn? The framework choice comes after.
The Three-Layer Stack to Fund
You’re not picking “an AI framework.” You’re funding three different things that fail in different ways:
| Stack layer | What you’re really standardizing | What to lock down as the “contract” |
| Training & model development | How models are expressed, trained, and reproduced across compute | Reproducible environments, distributed training approach, artifact formats + lineage metadata |
| Generative AI application development | How teams implement prompts, retrieval, tools, routing, and orchestration in product code | Supported orchestration patterns, prompt/retrieval conventions, tracing interface, shared eval harness |
| Production ops & governance plane | How models are served, monitored, evaluated, and governed in production | Serving targets + rollback path, observability schema, evaluation gates, audit controls (who/what/when/why) |
If you think standardizing on PyTorch or TensorFlow settles the stack, you’re kidding yourself. Martin Fowler would tell you the burn is in the boundaries: the app and ops layers on top. For example, a team can use PyTorch and still ship an unstable RAG service because their orchestration library churns weekly, their eval harness is ad hoc, and nobody owns regression gates.
Treat the layers as separate contracts: decide what your platform team supports for each layer, what app teams can change freely, and what must meet SLOs and audit requirements before it reaches production. Then you can evaluate tools in the category they truly belong to instead of arguing past each other.
Your Selection Rubric (Reliability, Cost, Risk)
You don’t win by picking the most popular AI framework at any given moment. If standardize on vibes, you’ll discover too late that the real constraint was on-call load or upgrade churn.
Start With Your SLO and Ops Reality
Begin with the failure modes you can’t tolerate. For example, if you’re supporting a customer-facing RAG endpoint, a framework choice that complicates latency budgets or rollback procedures turns into platform pager duty. Treat this rubric like you would a Kubernetes distribution: it’s an operations decision wearing an ML hat.
Use a simple scorecard across candidates (training frameworks, GenAI app frameworks, and managed platforms) and force explicit owners for each dimension of risk management:
- SLO fit: Can you hit your latency, availability, and rollout goals with sane defaults? Look for canary support, versioned artifacts, and reproducible environments.
- Operational burden: What do you have to run and upgrade? Track “pieces you own” (runtimes, vector DB clients, eval harnesses) and expected on-call handoffs between platform and app teams.
- Lock-in risk: Where do proprietary APIs or hosted-only features become architectural dependencies? Managed platforms can reduce delivery risk, but they can also hard-code your training, serving, and observability paths.
- Security posture: Can you enforce IAM, data residency, secret handling, and audit logging without bespoke glue? Also ask how the tool handles supply-chain risk and dependency pinning.
- Skills market and ramp time: Optimize for what you can staff. JetBrains’ 2024 Python survey shows scikit-learn (68%), PyTorch (66%), and TensorFlow (49%) usage, which matters when you need incident-ready coverage, not just a demo.
- Dependency churn: Measure upstream change rate and breaking transitions. TensorFlow’s move from tf.lite toward LiteRT changes the “stable edge story” and forces explicit migration planning.
Pressure-Test With One Real Workflow
Pick one representative path, like “fine-tune a model and deploy to Kubernetes,” and run it end-to-end. Include registration, regression evaluation, and a rollback within minutes.
If that workflow requires tribal knowledge, you’re signing up for a permanent integration program.
Model Training Frameworks
At this layer, you’re standardizing how models are defined, trained, reproduced, and handed off to serving.
The decision sets expectations for iteration speed, artifact stability, upgrade cadence, and how cleanly research output crosses into production. This is a workflow and operability choice first, so don’t get caught in the capability race.
| Framework | Best for | Operational burden | Watch out for |
| PyTorch | Fast iteration on architecture | You own reproducibility, export, serving compatibility | Upstream churn leaks into prod without guardrails |
| TensorFlow | Stable pipelines, long-lived models | Heavier abstractions, migration planning | Slower experimentation cycles |
| Keras | Consistent modeling interface across teams | Needs strong platform controls underneath | Cosmetic consistency if governance is weak |
| scikit-learn | Interpretable models, tabular data | Governance and lineage are external | Doesn’t scale without additional tooling |
| Spark MLlib | Large-scale training in existing Spark environments | Tightly coupled to Spark | Narrow model expressiveness |
| Hugging Face | Portable model packaging, embeddings | Not opinionated on orchestration | Eval and governance are your problem |
| LangChain / LlamaIndex | RAG and agent prototyping | High churn, version pinning required | Opaque execution paths, debuggability erodes fast |
Managed Platforms Aren’t Frameworks
Managed platforms like SageMaker (and similar offerings) don’t give you only a modeling API. They give you an opinionated control plane for training jobs, artifact storage, deployment, permissions, and sometimes monitoring.
That control plane cuts delivery risk quickly, like hiring a turnkey facilities crew for GPUs, networking, audit logs, and repeatable deployments. If you’re treating “platform” as a shortcut for “less to own,” you’re right, but only if you accept the platform’s operating model.
The tradeoff is coupling. Once teams encode pipelines, registries, deployment targets, and evaluation hooks in platform-specific concepts, you stop buying tooling and start buying an architecture. For example, you might standardize on SageMaker endpoints because it gets a GenAI feature team to production in a quarter, then discover your Kubernetes-based platform can’t reproduce the same rollout, logging, and rollback behavior without a migration project.
Before you standardize, force one portability check: can you take a trained AI model and serve it outside the platform with the same interface, logging, and access controls, or did you hard-wire your reliability story to one vendor?
The Handshake Points Where Stacks Fail
Most “AI framework” pain shows up at the seams, not inside PyTorch or LangChain. Say a team tunes a machine learning model successfully, but it reaches production as a one-off container with missing metadata, different input schemas, and no rollback story. You don’t have a model problem then, you have an interface problem that turns every release into platform-owned integration work.
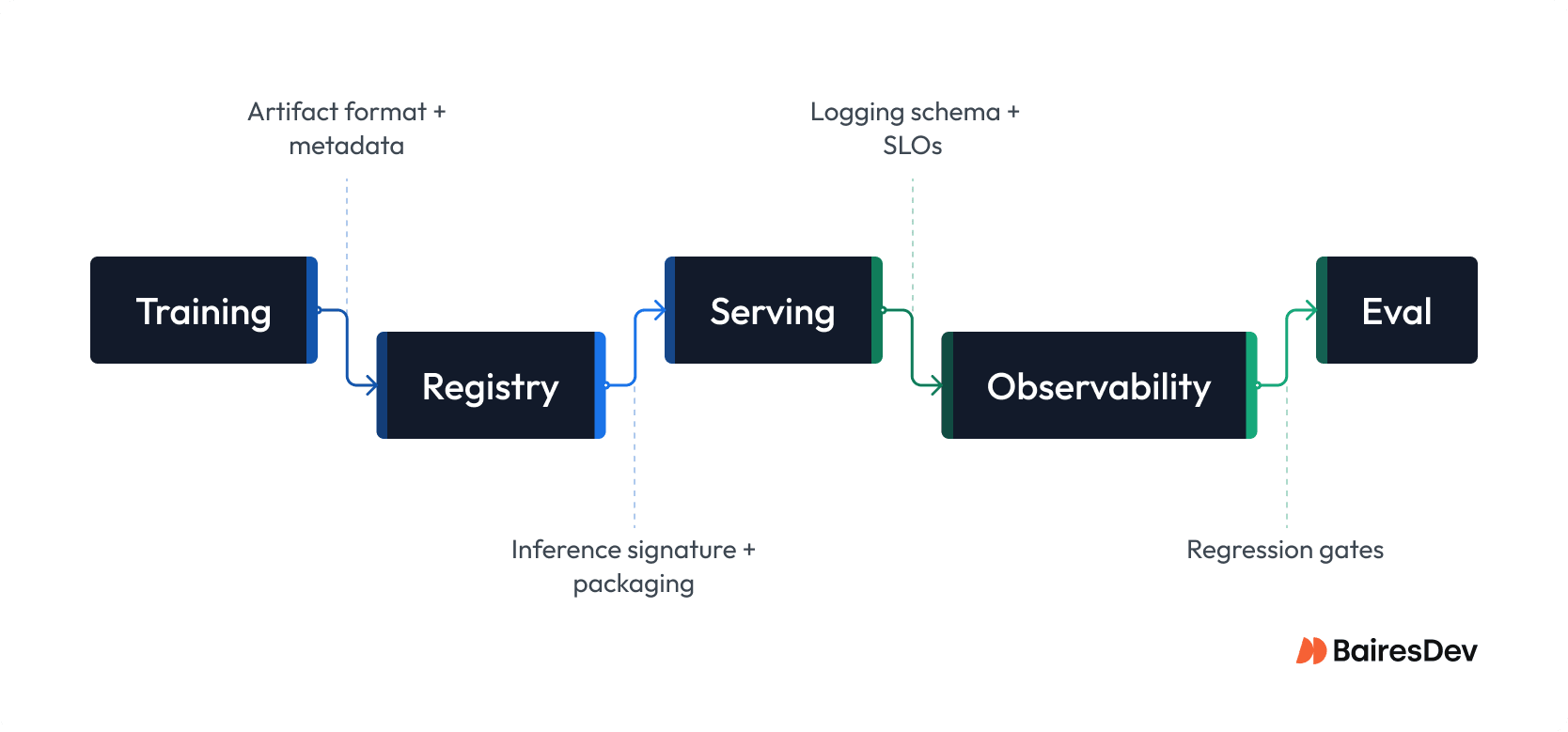
Believing a library standardizes the system is wishful thinking. The Phoenix Project made the same point: constraints live in the handoffs. Put explicit contracts on the handshake points that determine operability:
- Training to Registry: required artifact formats, versioning, and minimum metadata (data snapshot, code SHA, params, eval summary)
- Registry to Serving: a stable inference signature (inputs/outputs), runtime constraints, and a packaging rule you can reproduce in CI
- Serving to Observability: logging and tracing schema, latency/error metrics, and what “good” looks like for SLOs and cost
- App to Eval: a shared evaluation harness for regressions (offline tests plus a small online canary gate)
- Data to Lineage: dataset identifiers, access controls, and provenance rules so audits and incident triage don’t become archaeology
Governance Is a Layer, Not a Feature
Treat governance as “add later” and that’s a P0 mess waiting to happen. It’s like running a factory with no batch log when defects slip through.
A team can launch a RAG assistant that looks fine in staging, then a prompt change causes it to leak restricted snippets from an internal wiki. Without a proper governance layer across your AI systems, your only response is to yank the feature and start a blame-driven investigation. With good governance, you know what data was accessed, what version ran, who approved the change, and which kill switch to flip.
Controls shouldn’t depend on whether you use PyTorch, LangChain, or a managed platform. You need a risk framework mapping for artificial intelligence (use NIST AI RMF as your common language) and enforceable policies (data access, secrets, logging, retention, allowed models/providers). You also need evaluation gates (offline regression thresholds plus a small canary) and auditability (versioned prompts/models, dataset identifiers, decision logs).
Finally, make incident response real: define severity levels for AI failures, require on-call ownership, and pre-write runbooks for rollback paths like “revert prompt,” “disable tool,” “swap retriever,” or “route to human.”
If you can’t execute those in minutes, you don’t have governance, plain and simple.
A Practical Standardization Shortlist
Blessing every framework is the fastest path to chaos. In Jira terms, it turns every release into an evergreen “platform integration” ticket.
If your platform runs Kubernetes and Terraform as the common substrate, your real decision is what you’ll support end to end (build, deploy, observe, roll back) without turning every model release into a bespoke integration. If you’re still debating “best” frameworks, you’re already drifting toward tool sprawl and surprise on-call.
Here are three stack archetypes that fit most engineering orgs without over-scoping the effort:
- Kubernetes-First Open Stack: PyTorch or TensorFlow for training, Hugging Face plus one orchestration layer, and an ops plane you run (model registry, eval, monitoring). Best when you need portability and tight control, and you can afford integration work.
- Managed Control Plane First: a cloud ML platform for training and deployment, with a thin app layer on top. Best when speed-to-production and compliance evidence matter more than architectural freedom.
- Data-Platform First (Classical + Targeted GenAI): scikit-learn or Spark MLlib as the default, with GenAI frameworks only for bounded RAG use cases. Best when most value is tabular and you need predictable cost.
To decide fast, answer this: where must workloads run (VPC, on-prem, edge), who owns pager duty for the full path, and what audit controls must be provable by default in your development process.




