

AI bias has shifted from a technical flaw to a boardroom risk. Regulators, investors, and customers no longer accept speed without safeguards.
For engineering leaders, addressing artificial intelligence bias is the new bottleneck, especially within AI development services. Left unchecked, algorithmic biases rooted in flawed training data or biased AI systems result in lawsuits, fines, and reputational damage. But if you embed governance early and start mitigating bias throughout the AI development lifecycle, the same pressure becomes a throughput accelerator, winning customer trust and long-term market advantage.
Just as privacy laws forced companies to build dashboards and audit trails that are now standard practice, new artificial intelligence regulations are pushing for more transparency and monitoring in AI model development.
This article breaks down what’s changing in 2025, what each regulation means in practice, and how to turn compliance into a competitive edge.
2025 Regulatory Landscape: Your AI Compliance Checklist
The first obstacle for every tech leader is regulatory clarity. AI compliance regulations share common DNA—bias controls, logging, and human oversight. What varies are the triggers and penalties. Here is a bias compliance checklist for AI systems so you can align quickly and avoid surprises, inside a practical AI governance framework.
AI Regulatory Snapshot
| Regulation | Why it Matters | Actions | Evidence Needed |
| EU AI Act | Any “high-risk” AI systems (hiring, healthcare, law enforcement) | Classify models, assign risk owner | Data lineage, human oversight dashboards |
| NIST AI RMF | Federal contracts, enterprise risk teams | Map inventory to RMF functions | Internal risk register, roles & accountabilities |
| NYC Law 144 | Automated AI hiring tools | Plan annual independent bias audit | Budget external audit slots, candidate notices |
| ISO/IEC 42001 | Global AI adoption (certification optional) | Decide certification vs internal framework | Compliance owner, draft audit plan |
| FTC “AI Comply” | Any AI tools marketed as “fair” or unbiased | Document fairness testing & logs | Immutable logs, reproducible test results |
Use this table as your AI compliance checklist. Assign one owner per regulation. In a few weeks you’ll have a governance baseline and AI governance framework ready for your next board or legal review.
Even the largest players can’t rest easily. In late 2024, LinkedIn was fined €310 million under GDPR for misusing personal data in advertising. The lesson for CTOs is clear: compliance is not a box to tick. It’s a living process, and every lapse becomes headline risk. The same is now true for AI bias—which is why the next case studies matter.
AI Bias Case Studies: How Bias Becomes a Business Risk
Recent fines, lawsuits, and reputational hits prove AI bias is a business risk multiplier. Bias is a bottleneck: it slows deployments, creates legal issues, reputational risks, and erodes consumer trust.
But the pressure can be turned into a catalyst. New compliance requirements are driving the governance and innovation that create lasting value.
Case Study: Apple Card Bias Investigation
Problem: In 2019, Apple Card customers claimed men received higher credit limits than women, even when profiles were equal. The model was gender blind, but training data and opaque decision logic created a perception of gender bias.
Impact: NY regulators reviewed 400k applications and found no unlawful bias, but reputational concerns forced Apple/Goldman to add transparency features.
Action: Neutral models can still amplify inequities. Companies must rely on explainable AI dashboards, publish decision factors, keep fairness logs, and customer-facing transparency early. Add human-in-the-loop controls for edge cases, and monitor disparate impact in production so “neutral” models don’t reproduce historical inequities.
Case Study: Health Insurer AI Bias Lawsuit
Problem: UnitedHealth’s algorithm allegedly denied care for Medicare patients by reinforcing biased training data around “length of stay.”
Impact: Lawsuits and regulatory backlash followed. California passed the first US law banning insurers from using AI to deny care. Ironically, AI tools are now being used by advocacy groups to help patients contest denials, demonstrating how bias in AI can cut both ways.
Action: Build human oversight into decision flows, maintain immutable audit logs, embed bias drift detection. Position AI as your customers’ advocate, not a gatekeeper or adversary.
Case Study: Workday AI Hiring Bias Lawsuit
Problem: A 2023 lawsuit alleged Workday’s hiring AI discriminated by age, race, and disability, auto-rejecting applicants before reaching recruiters.
Impact: In 2025, a federal judge allowed a nationwide collective action under the Age Discrimination in Employment Act (ADEA) and ordered Workday to disclose all employers using HiredScore’s AI hiring tools. Liability expanded to vendors, proving how bias audits for AI hiring tools are now a compliance requirement, not an option.
Action: Run independent bias audits for AI hiring tools quarterly. Embed fairness metrics in your CI/CD pipeline, maintain audit logs, and include bias clauses + oversight rights in vendor contracts.
Case Study: Generative AI Stereotyping
Problem: Studies (2024–25) showed Stable Diffusion and DALL·E reinforced harmful stereotypes, reflected training-data bias, producing stereotyped results: “CEO” as white men, “nurse” as women or minorities.
Impact: Enterprise adoption slowed as regulators and procurement teams demanded bias audits and explainability in contracts. What started as a PR problem became a compliance liability.
Action: Audit generative AI models with pre-deployment stereotype/toxicity tests, monitor outputs for drift, curate balanced data, and require explainable AI features (with rejection gates).
CTO Playbook: Building a Trustworthy AI Governance Framework
Leadership expects a practical AI governance framework with clear guardrails, bias metrics, and accountability.
Establish Ownership and Accountability
Bias mitigation starts with clear ownership. Without defined roles, AI governance collapses into finger-pointing. CTOs need cross-functional governance spanning engineering, product, compliance, and legal.
Governance RACI
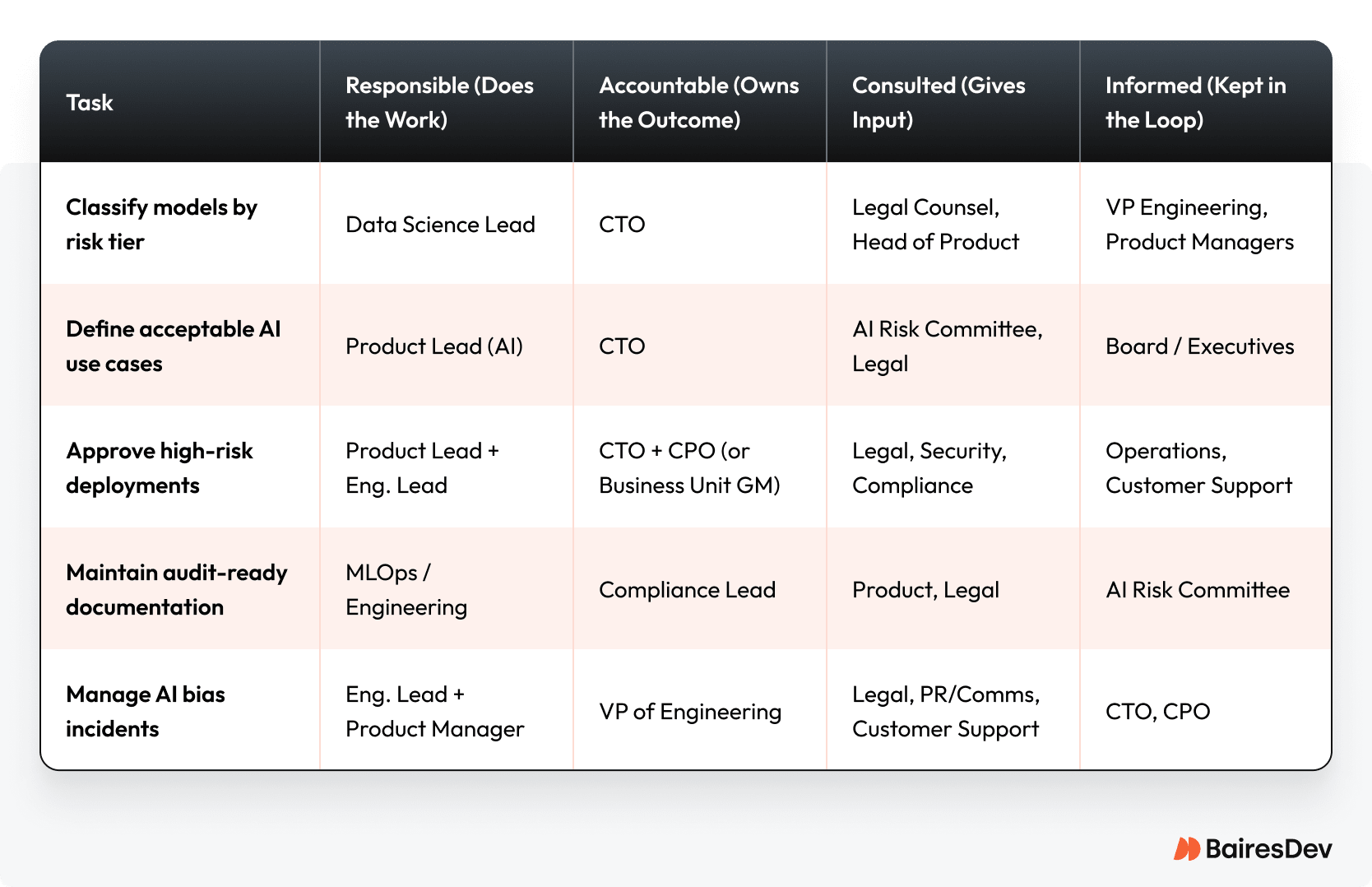
Takeaway for CTOs: Never accept sole accountability for business risk. Use this chart to force the conversation with your counterparts in Product and the business units. If they are not willing to have their role listed in the ‘Accountable’ column alongside yours for a high-risk system, then the project carries too much political and operational risk for Engineering to build alone.
Inventory and Classify Your AI Systems
Leadership needs a live inventory of all AI systems across the org, ranked by risk level. Treat it like a model register that product, legal, and engineering can all pull from. This becomes your single source of truth for audits, compliance, and decision-making.
AI System Inventory Matrix

Takeaway for CTOs: Build your AI inventory within 30 days. Assign one “risk owner” per high-risk system. This gives you a compliance baseline and a board-ready artifact.
Measure: Operationalize Fairness with Metrics
Unfortunately, there’s no single metric that captures all dimensions of bias. You need a cyclic, portfolio approach. You must embed metrics and monitoring into your CI/CD so fairness is tested alongside unit tests and security scans. To do that, treat fairness scores as release-blockers and set thresholds that trigger retraining.
Key Bias Metrics
This table isn’t for reports. It turns the subjective “fairness” debate into a binary engineering gate. Your job is to make these metrics mandatory release blockers in your CI/CD pipeline. If a model introduces bias, the build fails. Full stop. Just like a broken unit test.
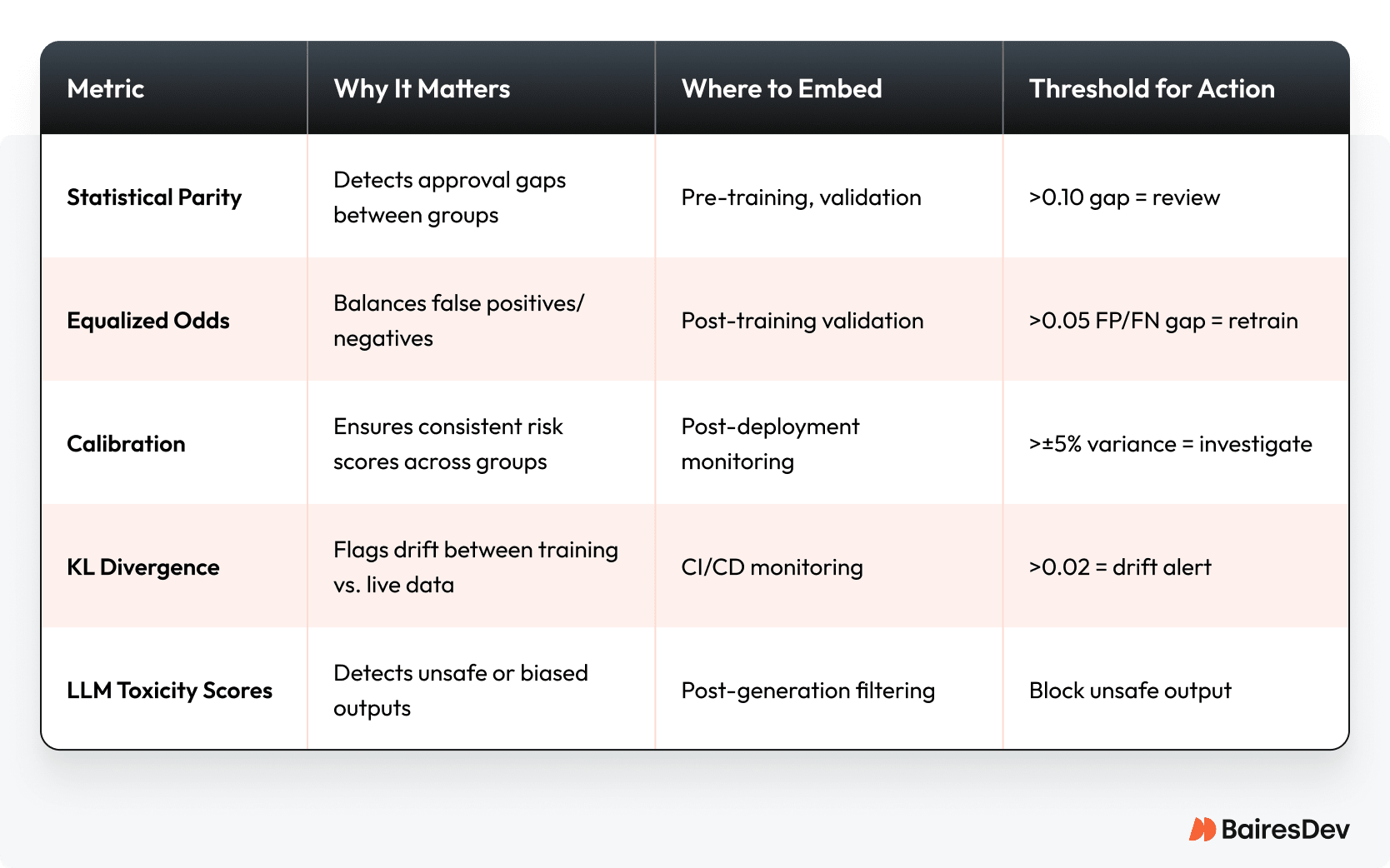
Takeaway for CTOs: Add at least two AI bias metrics to your validation suite this sprint. Publish thresholds in your CI/CD pipeline docs so the board and auditors see bias monitoring as part of your standard engineering practice.
Manage: Monitor and Prove Compliance
As you know now, AI bias doesn’t end at deployment. Real-world data drifts, outcomes shift, and regulators expect continuous proof of fairness. CTOs need post-market monitoring, scheduled audits, and immutable documentation — so when legal, the board, or regulators ask, you’re audit-ready.
Continuous Monitoring & Audit Cadence
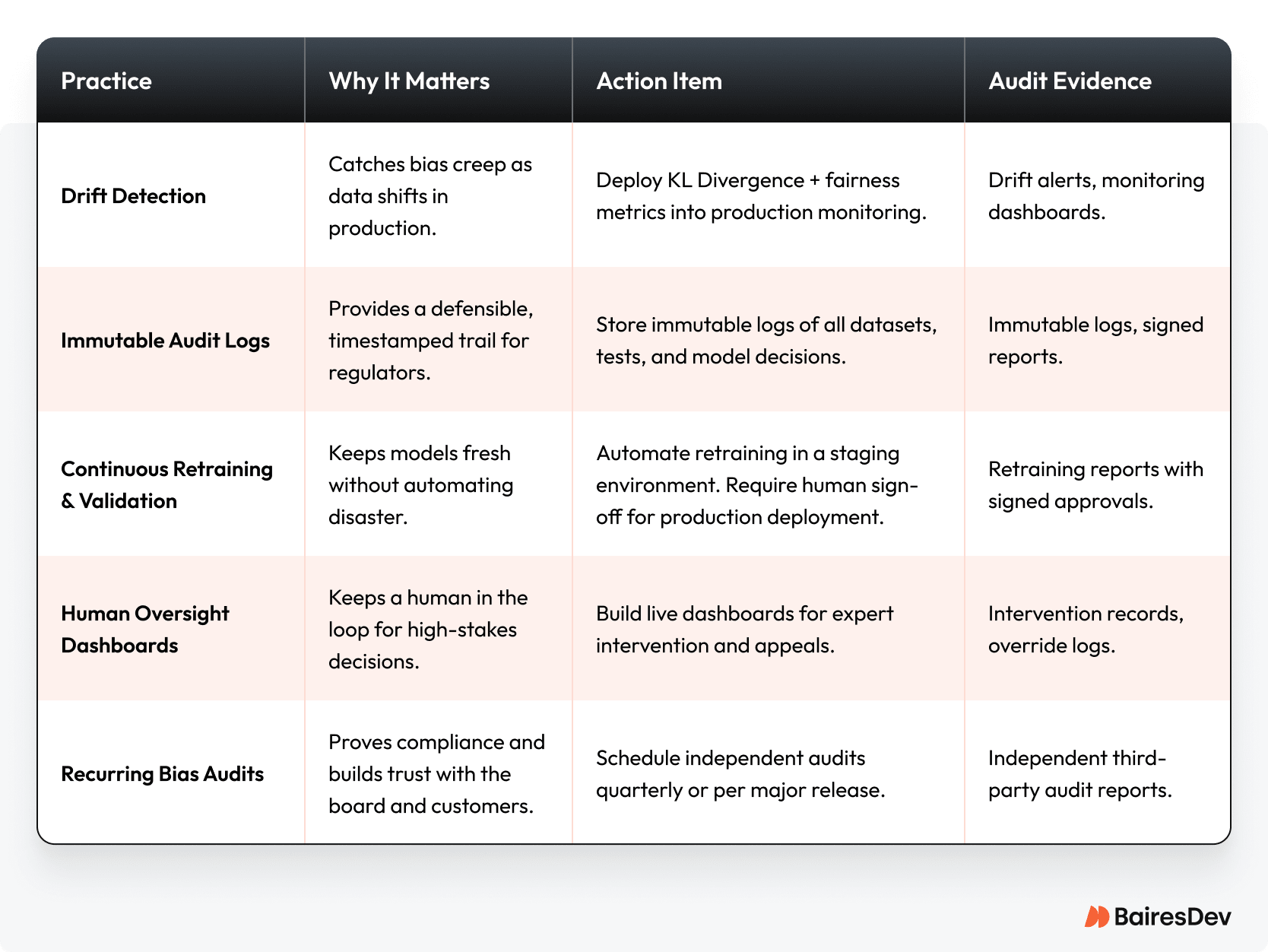
Takeaway: Treat bias monitoring like uptime. It needs to be tracked, reported, and automated. Set up a quarterly bias health review. This creates a compliance cadence that reassures boards, customers, and regulators.
Choosing the Right Tools for AI Bias Mitigation
Bias detection tools can overwhelm you with choices. Instead of trying everything at once, start with the tool that best matches your existing stack and maturity. Expand over time, but don’t stall waiting for “perfect.”
Tooling Decision Matrix
| Scenario | Tool | The Upside | The Real Cost |
| You’re an AWS shop. | SageMaker Clarify | Native integration, path of least resistance. | Deeper AWS vendor lock-in. |
| You’re an Azure shop. | Responsible AI Dashboard | Turn-key dashboards for teams in the ecosystem. | Deeper Azure vendor lock-in. |
| You want full control. | Fairlearn / IBM AIF360 | Maximum control and no vendor lock-in. | Your senior engineers’ time to maintain it. |
| You’re monitoring LLMs. | WhyLabs + LangKit | Purpose-built for the risks of generative AI. | Another specialized tool in your stack. |
| GRC is driving the purchase. | Credo AI / IBM OpenScale | Enterprise-grade audit trails and policy management. | A large contract; risk of being a tool your engineers ignore. |
Takeaway for CTOs: Start with the tool aligned to your current stack. Layer in more specialized platforms as your compliance program matures.
The Bottom Line: Your Move
At the end of the day, you have a simple choice: treat compliance as a tax or as your moat.
You can treat this whole compliance issue as some corporate mandate to be ignored until the lawyers show up. A lot of companies do. And they spend all their time reacting, putting out fires, and watching their best engineers get bogged down in endless review cycles.
Or you can see it for what it is: a lever. An excuse to build a smarter, faster, more durable engineering practice. Winning teams aren’t just avoiding fines. They’re shipping code while their competitors are stuck in meetings about ethics.
So forget the fluff about “trustworthy AI.” That’s for the marketing department. For engineering, this is about building a machine that doesn’t create its own drag. It’s about speed and not having to apologize for the tools we build.
Bias-Resilient AI: A 2025 CTO Readiness Scorecard
This scorecard gives CTOs and VPs of Engineering a fast way to benchmark readiness against 2025 compliance and governance expectations. Print it, check it off, and present it at your next board or legal review.
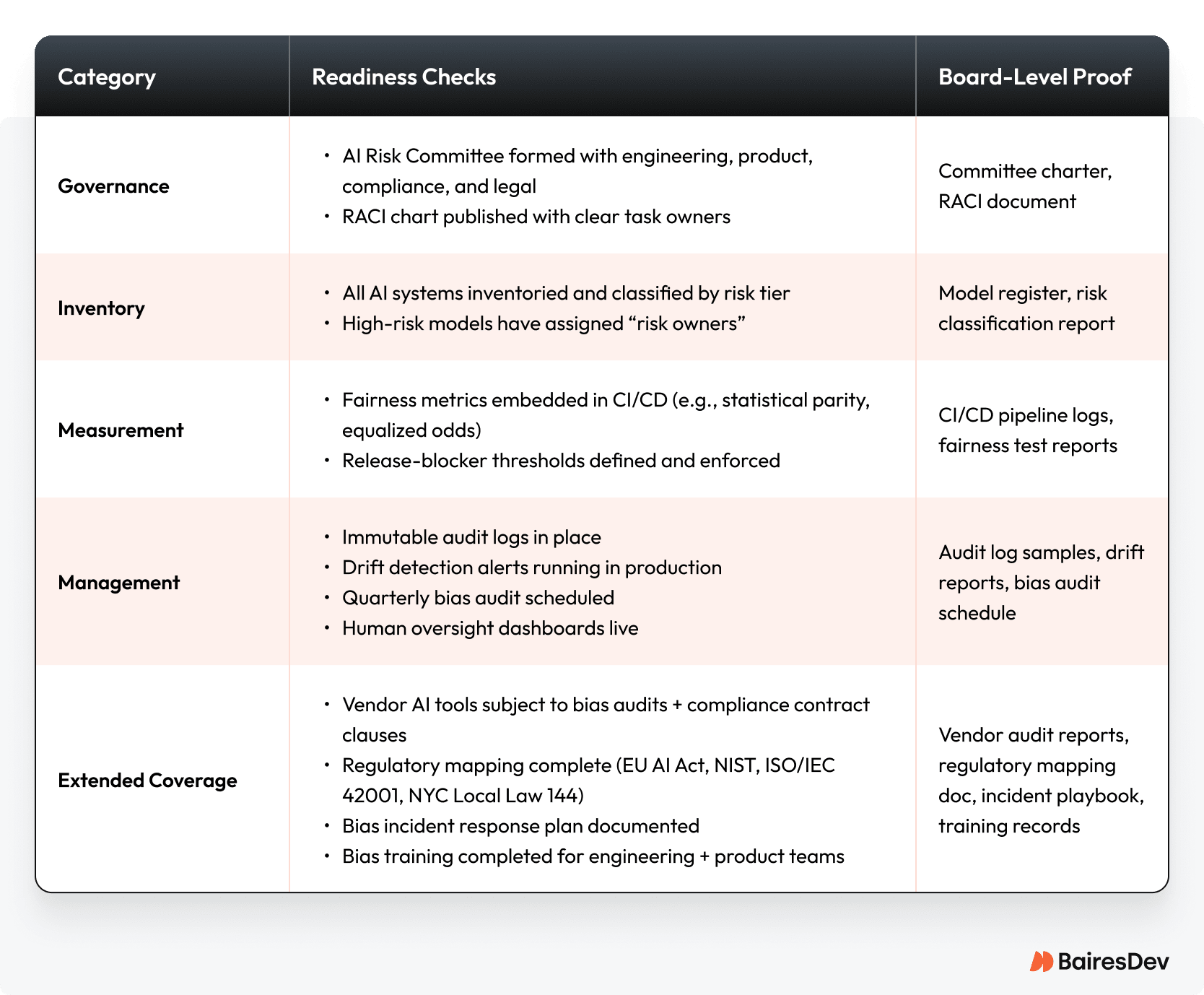
How to Score Yourself:
- If you’re at 80% or more: You’re operating at best practice. Your job now is to maintain discipline and not let it slide.
- If you’re below 50%: You have significant exposure. This is your red zone. Your immediate priority must be to establish your governance committee and build your model inventory.
- If you’re in the middle: Your goal is to show a clear, documented path forward in a board-facing roadmap. Regulators and your board value progress over perfection.
Next 30 / 90 Days: Your Action Roadmap
Within 30 Days
- Stand up an AI Risk Committee (eng/product/legal/compliance).
- Inventory all AI systems; classify by risk; assign risk owners for high-risk models.
- Add at least two fairness metrics (statistical parity, equalized odds) to CI/CD validation.
- Start logging dataset lineage for audit-readiness.
Within 90 Days
- Schedule your first independent bias audit (start with hiring or customer-facing systems).
- Launch immutable audit logging + drift alerts in production.
- Pilot a human oversight dashboard for interventions on high-stakes models.
- Extend governance to third-party AI tools (bias clauses, audit rights).
- Brief the board with a progress snapshot and your quarterly bias-health cadence.
Why it matters: In 90 days you’ve turned compliance into a trust moat without slowing delivery.




