

When someone says “AI use cases,” they might mean three very different things, and the architecture, risk profile, and operating cost for each look nothing alike. If you’re allocating engineering capacity and budget against artificial intelligence initiatives, that distinction matters more than any vendor pitch deck will tell you.
Predictive machine learning models have been in production for years. Demand forecasting, fraud scoring, and quality control systems run on structured data and historical data, failing in predictable, measurable ways.
Generative AI changed the equation in 2023, letting teams summarize unstructured data, draft content, and accelerate code, but generative AI applications need evaluation frameworks most organizations still lack. And now AI agents (autonomous systems that plan, decide, and act across tools) represent the sharpest edge of the artificial intelligence wave. Gartner predicts that 40% of enterprise applications will include task-specific AI agents by end of 2026, up from less than 5% in 2025.
Here’s the thing. Most use case lists treat these categories interchangeably. A computer vision model inspecting welds on a manufacturing line has nothing in common with an AI-powered assistant that books meetings and updates CRM records. The capability pattern, risk profile, and integration effort are fundamentally different, and your portfolio strategy needs to reflect that.
WHY MOST AI PORTFOLIOS STALL
- 78% of organizations use AI in at least one function, only 6% report ≥5% EBIT attributable to AI (McKinsey, 2025)
- The gap emerges when picking use cases you can govern, integrate, and evaluate in production.
A Simple Portfolio Model: How to Avoid Random Acts of AI
I’ve seen engineering organizations generate 50-plus use cases in a single brainstorm, then stall because nobody knows which ones to fund. The fix is a portfolio lens that sorts artificial intelligence initiatives by ambition, feasibility, and time to proof.
Quick wins (assist and augment) reduce manual effort and speed up human decisions. AI tools that summarize support tickets, flag anomalies in dashboards, or auto-generate draft PR descriptions fit here. These are low risk, fast to prove when data access is straightforward and integration surface is narrow, and build organizational confidence. With clean data pipelines and clear eval criteria, expect proof within 60 days**. Without those conditions, timelines stretch to 3+ months even for simple implementations.
Automation (workflow and integration) handles repetitive processes end-to-end with built-in controls. Invoice processing, automated test generation, or supply chain routing fall here. The integration effort is higher because you’re connecting to systems of record, but efficiency gains compound. Time to production depends on integration complexity and data readiness: 3 months when systems have clean APIs and eval criteria are measurable, 6+ months when you’re building connectors from scratch or mapping legacy data models.
Differentiation bets leverage proprietary data and feedback loops for durable advantage. Custom models trained on your operational data, pricing engines informed by real-time market trends, or domain-specific natural language processing pipelines built on your corpus. High effort, high reward. Expect 6 to 12 months minimum, longer if you’re building data infrastructure and governance frameworks alongside the model.
AI Use Case Scoring Rubric
| Use Case Example | Portfolio Tier | Value | Feasibility | Risk | Time to Proof* |
| Ticket summarization (RAG) | Quick win | High | High | Low | 4-6 weeks |
| Code review assistant | Quick win | High | High | Low | 4-8 weeks |
| Fraud detection (classify) | Automation | High | Medium | Medium | 3-5 months |
| Demand forecasting | Automation | High | Medium | Medium | 3-6 months |
| Inventory management optimization | Automation | Medium | Medium | Low | 3-5 months |
| Customer service AI assistant | Automation | High | Medium | Medium | 2-4 months |
| Automated QA test generation | Automation | Medium | High | Low | 2-3 months |
| Supply chain routing optimization | Differentiation | High | Low | Medium | 6-9 months |
| Predictive maintenance (IoT + ML) | Differentiation | High | Low | High | 6-12 months |
| Custom AI-powered pricing engine | Differentiation | High | Low | High | 6-12 months |
*Assumes clean data access, defined success criteria, and existing integration patterns. Add 2-6 months for greenfield infrastructure or complex governance.
** Expect proof within 60 days only if data is already accessible via API. If you need to build the data pipeline first, this is an ‘Automation’ project, not a ‘Quick Win’.
The scoring isn’t precise and you should take it with a grain of salt. It’s meant to force honest conversations about which artificial intelligence use cases you can ship versus what sounds exciting in a strategy deck.
AI Use Cases by Capability Pattern
Organizing artificial intelligence use cases by what the system does, rather than by industry, gives you a clearer map to architecture, data needs, and operating risk. Five patterns cover the vast majority of enterprise AI applications.
Classify and Detect
Good for: fraud detection, anomaly detection, quality defects, threat detection, sentiment analysis.
These solutions take structured data or sensor inputs and assign categories or flag outliers. Computer vision models inspecting product defects, machine learning models scoring transactions for fraud, or NLP classifiers routing customer interactions by intent all fit this pattern.
Data inputs are typically historical data and real-time event streams. Integration points: your data warehouse, event bus, and alerting systems. The AI algorithms here are mature (gradient-boosted trees, CNNs, transformer classifiers), and these applications improve efficiency by reducing human error in high-volume decisions. Plan for a feature store, a model registry, and a monitoring sidecar that tracks prediction distribution shifts.
Production pitfall: Model drift. Your fraud patterns from Q1 won’t match Q3. Without a monitoring loop and retraining cadence, accuracy degrades silently, and customer satisfaction suffers.
Forecast and Optimize
Good for: demand forecasting, inventory management, supply chain optimization, resource allocation, route planning.
These applications consume historical and real-time data to predict future states and recommend actions. AI algorithms here range from time-series models to reinforcement learning for complex supply chain decisions. Supply teams use them to anticipate peak demand periods and optimize inventory levels. Operations teams allocate resources and optimize routes for fuel consumption and delivery speed. The integration surface is wide (ERP, warehouse management, logistics APIs), so plan for a data-mesh approach over a monolithic pipeline.
Production pitfall: Data freshness can be an issue. Machine learning models trained on pre-pandemic data will mislead you. Your pipeline needs to identify trends in recent data and retrain on a cadence matching your domain’s volatility: weekly for routing, monthly for demand forecasting, quarterly for resource allocation baselines.
Retrieve and Summarize
Good for: knowledge search across internal docs, ticket summarization, report drafting, meeting-notes generation.
This is the RAG (retrieval-augmented generation) pattern, probably the fastest-growing category of enterprise use cases. These solutions connect large language models to internal knowledge bases, letting teams extract insights from vast amounts of unstructured data: policy documents, Confluence wikis, Slack threads, audio files, and so on.
Integration requires an embedding pipeline, a vector store, and access controls that respect your existing permissions model. The AI assistant surfaces relevant context rather than hallucinating, which is what makes RAG viable where pure generative AI isn’t.
Production pitfall: Retrieval quality. If your chunking strategy is wrong or embeddings miss domain semantics, the model returns confident-sounding garbage. Evaluate retrieval precision, not just generation quality.
Generate
Good for: content generation, code assistance, templated communications, design mockups, process automation.
Generative AI shines when the output has a clear review gate. AI-powered tools that draft marketing copy, generate unit tests, or produce customer-facing communications all create leverage, but only if a human reviews the output before it ships. The risk isn’t that gen AI produces bad content by default. It’s that teams skip the review step because the output looks plausible but fails to stand up to scrutiny.
Production pitfall: Review fatigue. When 90% of AI-generated outputs are good enough, reviewers start rubber-stamping. Build sampling-based quality control into your workflow, not just approval gates.
Act (Agents and Workflows)
Good for: multi-step task execution, ticket automation, account actions, data pipeline orchestration.
Agents represent the newest and riskiest capability pattern. Agents don’t just recommend, they act. They update tickets, trigger deployments, send communications, and modify records across systems. The MIT Sloan/BCG 2025 research found that 58% of leading organizations using agentic AI expect governance structure changes within three years.
Production pitfall: Privilege creep. AI agents accumulate tool access over time, and without strict least-privilege controls, a single misfire cascades across systems.
Capability-Pattern Quick Reference
| Pattern | Typical Data Inputs | Integration Complexity | Operating Risk | Review Cadence |
| Classify / Detect | Structured data, event streams, sensor feeds | Medium (warehouse + alerting) | Low-Medium | Monthly drift checks |
| Forecast / Optimize | Historical data, real-time signals, market data | High (ERP, supply chain systems) | Medium | Weekly retraining eval |
| Retrieve / Summarize | Unstructured data, knowledge bases, documents | Medium (embedding pipeline + vector store) | Low | Quarterly retrieval audits |
| Generate | Prompts, templates, context documents | Low-Medium (API + review workflow) | Medium | Per-output review gates |
| Act (Agents) | Multi-system state, tool APIs, user context | High (cross-system orchestration) | High | Continuous monitoring |
Functions Where AI Improves Efficiency
These patterns don’t live in isolation. The business functions where AI improves efficiency most consistently are the ones with high data volume, repeatable decisions, and measurable outcomes.
| Business Function | AI Systems and Tools in Use | Impact |
| Customer Experience | AI assistants, natural language processing classifiers, sentiment analysis solutions | Faster resolution, higher customer satisfaction |
| Supply Chain | Machine learning demand models, computer vision QC, AI routing | Operational efficiency in inventory and logistics |
| Engineering | Generative AI code tools, agents for pipeline orchestration, AI algorithms for test prioritization | Fewer review cycles, faster delivery |
Expert Perspective: Agentic AI Deserves Its Own Reality Check
I worked with a platform team that deployed an agent for tier-one support ticket triage. It handled password resets and access requests brilliantly: bounded workflows with clear success criteria. Then someone expanded its permissions to include account modifications and billing adjustments. Within a week, the agent had auto-credited three accounts based on misinterpreted sentiment analysis.
The lesson? AI agents work when the workflow is bounded, success criteria are measurable, and error blast radius is contained. They’re risky when permissions are broad, ambiguous, and human intervention is missing.
McKinsey’s 2025 State of AI report found that 23% of organizations are actively scaling agents, with another 39% experimenting. But fewer than 10% of vertical artificial intelligence use cases have reached production. The gap between experimentation and reliable deployment is governance: the absence of identity-bound, scope-limited control planes for non-human actors.
Guardrails that work for AI agents in production:
- Least-privilege tool access. Each agent gets only the permissions its specific workflow requires.
- Approval steps for high-impact actions. Anything above a defined risk threshold requires human sign-off.
- Immutable audit logs. Every action, tool call, and decision path logged and queryable.
- Regression evaluation before rollout. Test against known scenarios before expanding scope.
- Session-scoped permissions. Agents must not carry privileges from one context into another.
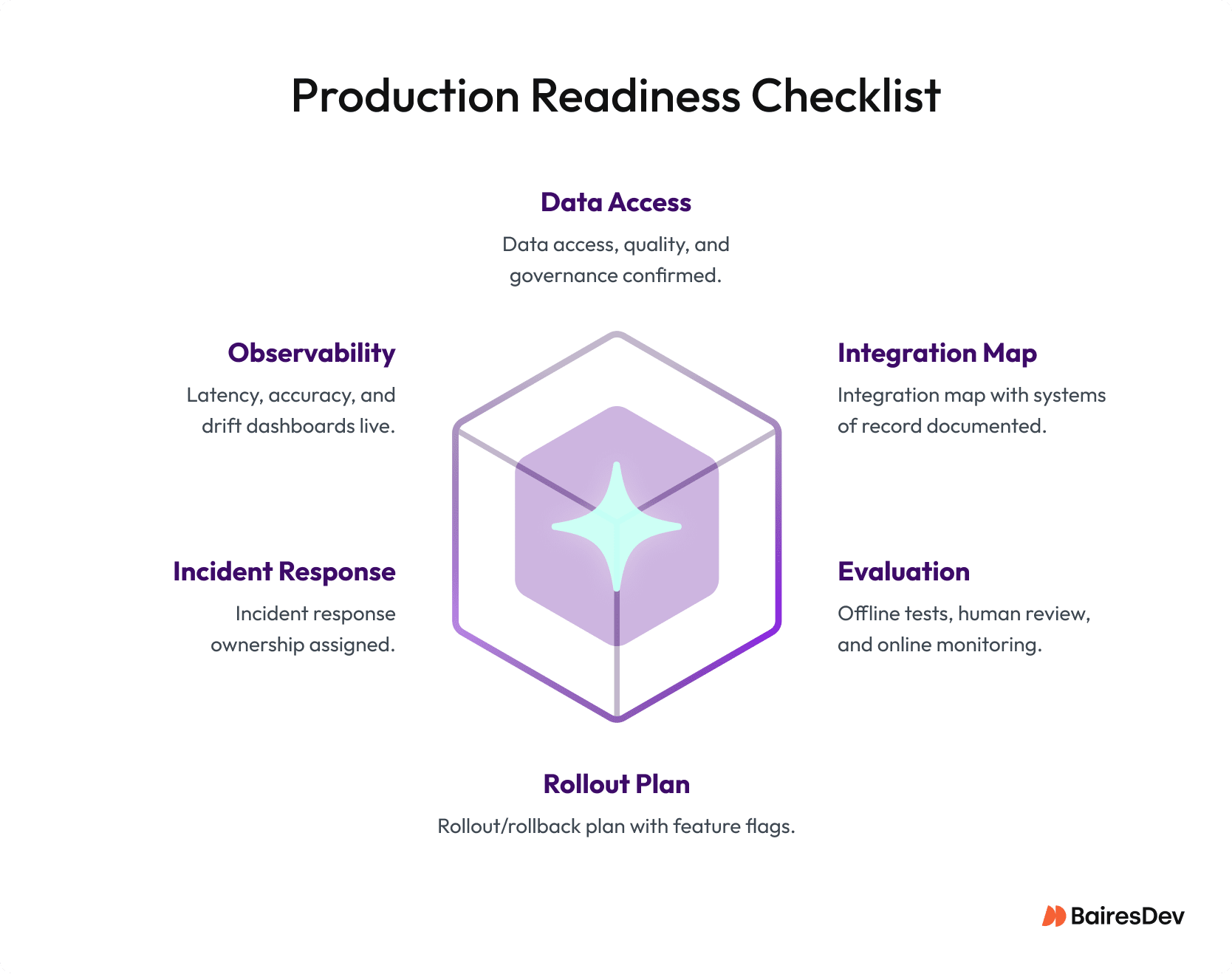
Implementation Blueprint: The Minimum Viable Checklist
Regardless of the capability pattern, every AI use case needs these foundations before earning a production slot.
Data readiness. Can you access the structured data and unstructured data your model needs? Is the quality sufficient, and do you have governance for sensitive fields? AI technologies are only as reliable as the data feeding them.
Integration map. Which systems of record will AI solutions read from and write to? What event streams carry customer experience signals and telemetry you’ll need for monitoring?
Evaluation plan. Offline tests establish a baseline. Human review catches edge cases. Online monitoring tracks drift, latency, and accuracy in production. All three are non-negotiable.
Rollout and rollback. Canary deployments, feature flags, and a clear rollback procedure. If AI applications degrade, you revert without scrambling.
Ownership. Who owns the model in production? Who responds to incidents? AI solutions without clear ownership become organizational orphans that quietly degrade.
Build Versus Buy: A Pragmatic Decision
The build-versus-buy calculus has shifted. Menlo Ventures reported that 76% of enterprise AI use cases were purchased rather than built internally in 2025, up from roughly 50/50 the year prior. Pre-built solutions reach production faster and convert at nearly twice the rate of traditional software deals.
Buy when you need commodity capabilities and speed. Off-the-shelf generative AI tools for code assistance, conversational AI, CX analytics, and supply chain optimization deliver fast value.
Build when differentiation depends on proprietary data, tight integration, or strict governance. If your competitive edge comes from leveraging AI against unique data, the integration and evaluation layers must be yours.
The smart play is hybrid. Buy the generative AI platform. Build the integration layer, evaluation framework, and governance controls. Your AI applications create durable value not in the model weights, but in harnessing AI within the data pipelines, event streams, and approval workflows that are uniquely yours. Integration and observability are the moat.
Deloitte’s 2026 State of AI report reinforces this: organizations where leadership actively shapes artificial intelligence governance achieve greater business value. The operating model is the differentiator.



