

Every large organization reaches a tipping point where yesterday’s data tactics no longer scale. Storage costs creep upward, analytics teams queue behind a single backlog, and executives wonder why dashboards still refresh overnight.
Meanwhile, product teams keep shipping features that create more logs, events, and user signals. In that swirl of growth, leaders must choose an architecture that lets data flow at the speed of the business, yet remains governable and cost-aware.
Two models dominate the conversation. A data lake centralizes everything in one low-cost repository, promising universal access and easy experimentation. A data mesh flips that logic, giving each domain its own pipelines and data products while a federated platform enforces global standards. Both approaches succeed or fail depending on how well they match an organization’s structure, compliance footprint, and appetite for change.
This article dissects the trade-offs through an executive lens. We begin by examining why classic, centralized platforms strain under modern workloads. We then revisit what a data lake actually gets right and where its limits appear. In later sections we will explore the mesh alternative, compare governance, data management, and cost dynamics.
Why Centralized Models Break at Scale
Centralization concentrates expertise but also concentrates risk, workload, and political tension. As user counts soar and regulatory scrutiny tightens, bottlenecks shift from hardware to humans. Many enterprises therefore revisit their architecture, asking whether a broader distribution of ownership can restore momentum without sacrificing control.
Central Governance Becomes a Bottleneck
Centralized data teams start with noble intentions. They curate schemas, monitor data quality, grant access, and protect sensitive fields. Early on, the model works. A small staff can ingest new sources, write transformation jobs, and field ad-hoc data access requests.
Problems arise when fifteen product squads, three compliance groups, and an AI research unit all need changes at once. Every new column, masking rule, or scheduling tweak lands in the same Jira queue. The queue lengthens, context switching rises, and release cycles slip from days to quarters. Business stakeholders see latency in decision-making, not just in query speed.
Data Swamps and Shadow Pipelines
Volume alone does not sink a data lake architecture, but uncontrolled ingestion does. Under pressure to deliver, engineers often bypass formal onboarding and dump raw data into staging folders. Metadata lags behind, lineage grows murky, and analysts lose trust.
They respond by creating private extracts, often on desktops or rogue cloud buckets. These shadow pipelines fracture governance and duplicate storage costs. Worse, silent schema drift in a central store can propagate errors to dozens of downstream jobs before anyone notices. Managing data becomes a challenge.
Organizational Mismatch
A monolithic platform assumes a clear boundary between data consumers and producers. Modern product teams blur that line. Developers who capture user events also need rapid feedback to tune features.
Marketing wants real-time campaign metrics, not yesterday’s roll-up. Finance must trace revenue at the micro-transaction level for compliance. When every domain relies on a single platform team, priorities collide. Negotiating queue position becomes a bigger chore than improving data itself.
What Is a Data Lake and When Does It Work
The data lake architecture emerged as a direct answer to traditional data warehouses. Instead of modeling everything up front, engineers could land structured data, entirely unstructured data, or semi-structured data into inexpensive object storage.
Tools like Apache Spark and Presto let analysts read that data on demand, applying schema at query time. For a growth-stage company or a division launching its first analytics practice, this model is a gift. The cost of storing data stay low, ingestion pipelines remain simple, and data scientists are free to explore large histories without pleading for space.
A well-run data lake also eases compliance. Central teams can encrypt buckets, manage IAM policies, and audit access in one console. Adding a new data source is often trivial: drop files in a partitioned folder or stream events with minimal transformation. That agility supports batch workloads such as revenue reports, quarterly forecasting, or retrospective model training.
The lake’s limitations surface when concurrency climbs. Because compute is decoupled from storage, every heavy query spins up its own cluster or competes for shared resources. Costs spike unpredictably. More critically, schema-on-read can mask semantic errors until query time, turning simple joins into hunting expeditions. Teams that crave real-time insights may balk at eventual-consistency delays on object stores. And as datasets multiply, the catalog becomes the platform’s beating heart; without rigorous metadata, discovery collapses into guesswork.
When, then, is a data lake the right fit?
- Stable governance with modest change velocity. If one team can still oversee ingestion standards and data integration, a single lake remains manageable.
- Predominantly batch analytics. Historical trend analysis, large-scale model training, and archive retention map neatly to cheap storage.
- Budget sensitivity over instant freshness. Enterprises that must retain petabytes of data but access only subsets each day often find the data lake unbeatable in cost efficiency.
Under those conditions a central data lake can thrive for years. The challenge begins when domain teams demand autonomy or when streaming use cases require speeds the lake alone cannot deliver. At that juncture, leaders start weighing more federated patterns, including the data mesh architecture we will examine next.
What Makes Data Mesh Different
The data mesh paradigm is less a single technology stack and more an operating model for data. It assumes that the people who know a dataset best should own it end-to-end and make it available as a product. This shift unlocks speed and accountability, but only if data governance and platform support are designed with equal care.
Decentralized Ownership at the Domain Level
Each line-of-business team, such as payments, supply chain, or marketing, collects, cleans, and publishes its own analytics-ready tables or streams.
Ownership is explicit. If the product catalog team changes a field name, they update downstream contracts and notify subscribers through the same pipeline that delivers the data. Because context lives inside the producing team, questions about meaning or poor data quality are resolved quickly, not bounced across a central queue.
Federated Governance and Self-Serve Platforms
True decentralization needs shared guardrails. A successful enterprise data mesh relies on a thin central layer that enforces standards through automation, not ticket approval. This platform usually provides:
- A unified catalog so everyone can discover data products,
- Built-in lineage and quality checks that run in continuous integration pipelines, and
- Policy-as-code modules that apply encryption, retention, and access rules consistently.
With these pieces in place, data domain teams stay autonomous without drifting into chaos. The central group focuses on the platform itself rather than day-to-day data wrangling.
Data as a Product Mindset
Owning data also means treating it like software. Teams version schemas, publish changelogs, and track service-level objectives such as freshness or completeness. Data consumers gain clear expectations.
Data producers gain clarity on what “done” looks like. This product lens transforms data from an internal raw material into a measurable asset, one that executives can discuss in the same breath as feature releases or uptime targets.
Architectural Trade-offs: Governance, Complexity, and Cost
Choosing between a data lake and a mesh is not just a tooling debate. It is a conversation about how an organization balances control, speed, and spend.
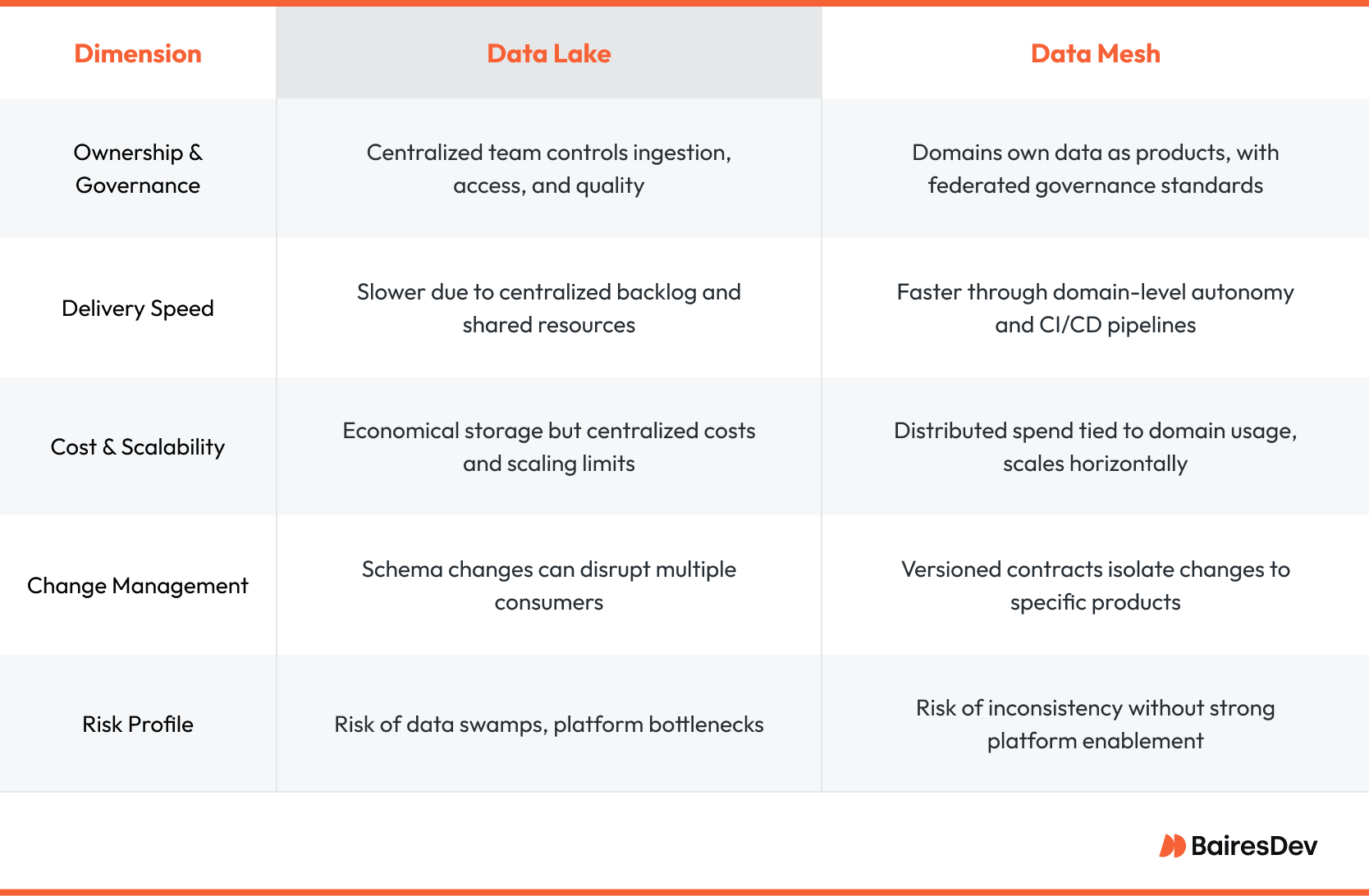
Governance Models
Centralized data lakes concentrate policy enforcement in one place, making audits straightforward but slowing change. Data meshes distribute enforcement. Each domain injects governance checks into its own pipelines, while a federated framework verifies compliance across domains. The result is faster adaptation to local needs, though it requires rigorous standards and automated tests to avoid drift.
Cost Structures
A single lake often wins on storage economics. Object stores cost pennies per gigabyte, and compute scales independently. Hidden expenses emerge when concurrency rises. Teams spin up overlapping clusters or export slices to shadow databases, inflating cloud data processing bills.
Mesh investments look different. Storage is still cheap, but organizations budget for extra headcount in each domain and for a robust platform team. Over time, proponents argue that the cost per delivered insight drops, because fewer cycles are wasted waiting for central resources. Skeptics highlight duplication risks if domains re-ingest the same raw data. Strong data discovery tools and data contracts mitigate that risk.
Tooling and Interoperability
In a lake, interoperability is implicit, as everything lives in one place. The data mesh introduces a network of stores, so cross-domain analytics depends on a query fabric.
The platform team must curate this data fabric and guarantee that domain schemas remain compatible. When done well, analysts enjoy the same seamless queries they had in a data lake, with the added benefit of fresher and better-documented datasets.
Real-World Implementation: Hybrid Approaches in Practice
Few enterprises make a clean break from lake to mesh. Most create a blended data infrastructure that leverages existing investment while introducing domain autonomy.
Why Most Enterprises Land on Hybrid Models
Central object storage still solves archival needs and large-scale machine learning training. Business domain teams layer real-time or curated datasets on top, managed through their own pipelines. This coexistence eases migration risk. Finance can remain batch-oriented inside the lake, while product analytics moves to a streaming mesh, all under a shared governance umbrella.
Patterns That Work
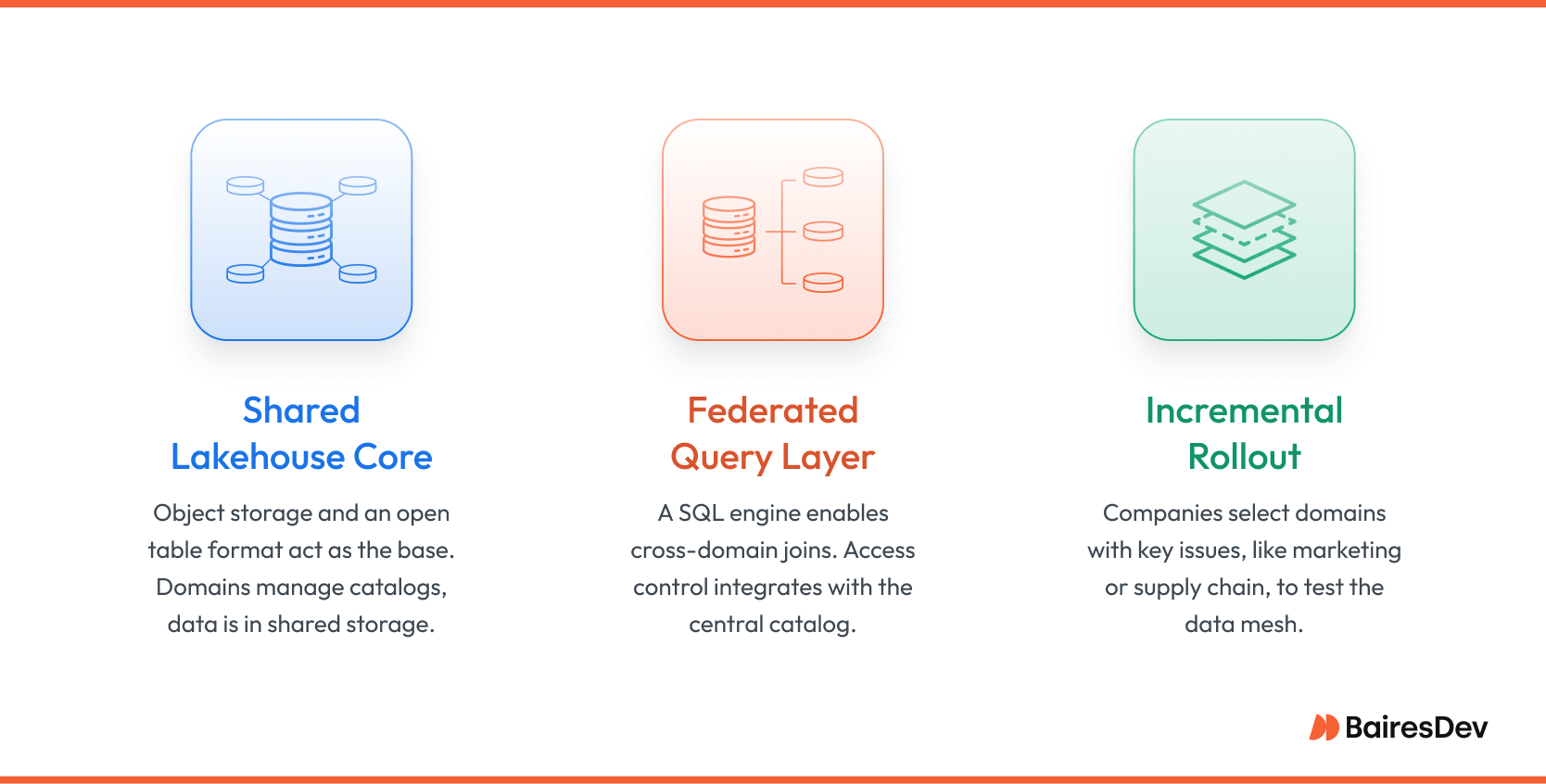
- Shared Lakehouse Core: Object storage plus an open table format serves as the universal substrate. Domains own separate catalogs and pipelines, but data lands in the same storage tier, enabling low-cost sharing.
- Federated Query Layer: A distributed SQL engine provides cross-domain joins. Access control integrates with the central catalog so analysts see only what they are entitled to.
- Incremental Rollout: Enterprises pick one or two domains with acute pain points, often marketing or supply chain, and pilot the data mesh model. Lessons learned feed into platform templates before wider adoption.
Organizations such as Intuit, Zalando, and ABN AMRO report that this hybrid path cuts delivery cycles without discarding proven infrastructure. It also helps cultural adoption, letting modern data teams witness success before committing fully to a decentralized future.
Strategic Considerations for CTOs and VPs of Engineering
Deciding on a data architecture is not a binary choice, it is an assessment of current pains, future scale, and the skills already on your payroll. The following perspectives help senior leaders frame the “mesh vs. data lake” conversation before budgets are locked and teams are reorganized.
When to Stick with a Centralized Lake
A data lake remains sensible if most analytics workloads are batch oriented and if governance is already mature. Central data teams that respond quickly to change, maintain a reliable catalog, and enforce quality checks may not benefit from a disruptive shift.
Compliance-heavy industries sometimes lean on a lake because auditors appreciate a single control plane. Finally, a lake is cost effective when data growth outpaces query volume, since object storage is inexpensive and compute can scale only when needed.
When to Move Toward a Mesh Model
Look for delivery bottlenecks, long onboarding queues, or shadow pipelines. These are signals that domain experts lack direct control over data they understand best. If product features depend on near-real-time feedback or if multiple business units require tailored metrics, decentralization pays dividends.
A data mesh approach is also attractive when leadership wants to tie data spending to specific outcomes. Domain budgets make cost accountability visible and motivate teams to refine rather than hoard. Success, however, hinges on a strong platform group that supplies data catalog, lineage, and policy automation so that autonomy never compromises compliance.
Conclusion: Choosing the Right Model for Your Team
Neither approach is universally better. A central lake excels at low-cost storage and retrospective analysis, while a data mesh accelerates product experimentation and domain accountability.
Many organizations combine them, layering domain pipelines and a federated data catalog on top of well-governed object storage. The winning data platform architecture is the one that matches organizational culture, risk tolerance, and urgency.
Frequently Asked Questions
What is the best indicator that our data lake has turned into a swamp?
When analysts spend more time hunting for trusted tables than running queries, metadata is either missing or outdated. A lake without an actively curated catalog will degrade in usability even if the storage layer is sound.
How much new headcount does a data mesh typically require?
Most companies do not double staff. They redistribute existing data engineers into domain teams and add a small platform squad, often five to eight engineers, to build self-service tooling. Upskilling programs usually accompany the shift.
Can we outsource part of the transition?
Yes. External talent can accelerate platform engineering, pipeline automation, or governance policy codification. Nearshore partners are often used to bootstrap the central platform while internal teams focus on domain data products.
Does a mesh eliminate the need for a data warehouse?
No. Many meshes keep a data lakehouse or warehouse for enterprise-wide reporting. The mesh governs how data gets there and who owns quality, but aggregated views still benefit from a consolidated analytical engine.
How do we avoid duplicate datasets across domains?
Publish every data product to a shared catalog with clear ownership and versioning. Before a new dataset goes live, the platform can run similarity checks or require approval from a federated review board.
What are typical first-year costs compared with enhancing the lake we have?
First-year mesh budgets often rise by up to 20% due to platform build-out and training. Long-term spend levels off because storage remains centralized and domain teams optimize pipelines they directly fund.
Is real-time analytics possible without moving to a mesh?
It is possible, but latency improvements in a centralized data lake usually demand specialized streaming add-ons and dedicated clusters. A mesh lets domains adopt streaming technology where it matters most without imposing those costs on every team.




