

In the early wave of AI adoption, AI systems depended heavily on human labor behind the scenes. Data labelers and content moderators were tasked with cleaning up data, identifying objects, and flagging anomalies or graphic content. After all, you just needed volume, right? The more data you had, the better. That’s no longer the case. Data quality has become mission-critical. It’s not just raw input to feed into models, but potentially a liability when handled poorly.
Only 12% of companies say their data is ready for AI. And it shows, because teams are spending more time cleaning inputs than building anything meaningful. Relying solely on low-cost data labelers or junior analysts just doesn’t cut it anymore. The volume and complexity have outpaced what manual processes can handle. What used to be manageable datasets are now petabytes of unstructured information that require domain expertise, not just extra hands.
Would you board a plane if you found out the fuel had been watered down to save costs? That’s how most AI programs take off, with bad inputs. And the cost, in turn, is that AI models often fail to scale or sustain performance because they’re held together by the data equivalent of duct tape. As reported by an MIT study, 95% of enterprise AI solutions fail, and it isn’t about model quality. It’s about tools that don’t learn, integrate poorly, or match workflows, all problems that trace back to how data is prepared and managed.
This guide is about fixing that. We’ll walk through five core areas of data readiness: use cases for strategy, asset inventory, infrastructure overhaul, hiring a data team, and heralding a data-driven culture. But before we do that, let’s zoom in on what data readiness means.
Establishing What Data Readiness Is
You can’t build an AI model on “data” the same way you can’t build a house with “stuff from a hardware store.” It matters whether the material is structured or unstructured, labeled, raw, complete, partial, standardized, and the list goes on. In the same MIT report, “model output quality concerns” were among the top reasons GenAI pilots failed, driven less by the models themselves and more by poor context, inconsistent inputs, and data that wasn’t ready for the task.
At the simplest level, it starts with structure.
- Structured data is tabular, such as transaction records, sensor logs, or database entries, where each value fits in a clean row and column.
- Unstructured data includes text, images, audio, and video. It’s rich in detail but harder to process.
- There’s also semi-structured data, like JSON files (e.g., user interaction logs from a web app) or XML documents (e.g., product catalogs shared between retailers and suppliers). It has structure, but it’s not fixed into a rigid schema like a database.
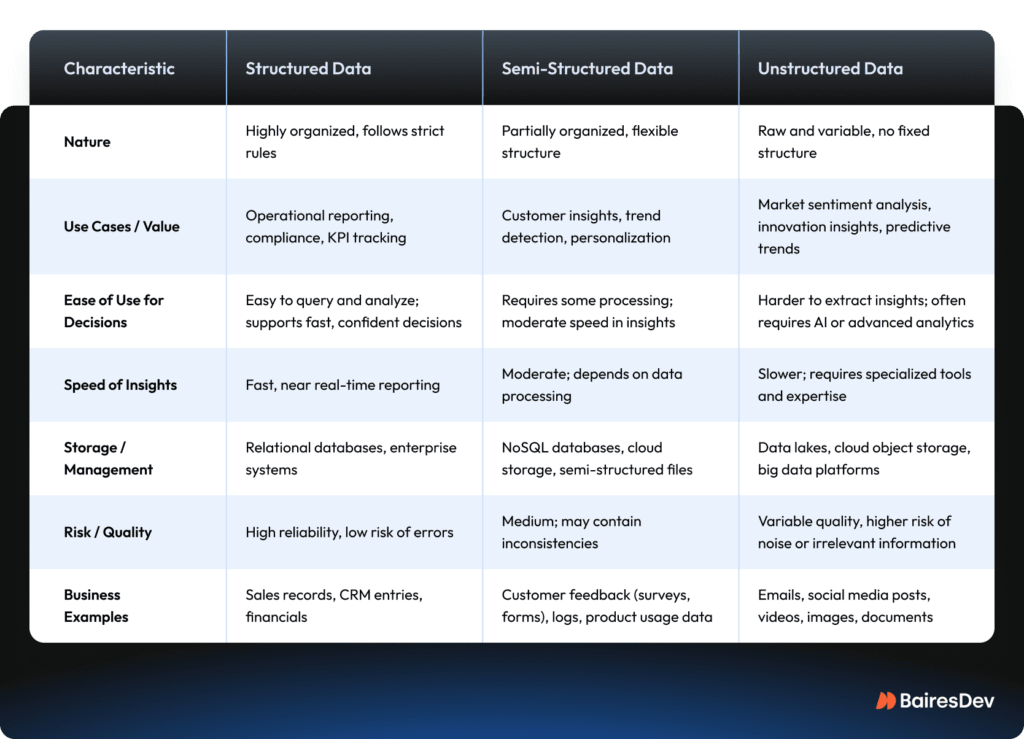
AI can work with all of these formats, but not out of the box. That means more than just having the data. You need to know where it lives, how clean it is, whether it’s labeled, how frequently it updates, and whether it’s even legal to use for your purpose (based on licensing, user consent, or regulations like GDPR or HIPAA).
You can have the right blueprint and the right team, but if the materials aren’t fit for purpose, the whole thing crumbles. The construction industry learned this lesson the hard way. Between the 1950s and 1990s, the UK used a material called reinforced autoclaved aerated concrete in schools, hospitals, and public buildings. It was cheap and easy to install. Decades later, roofs began collapsing without warning. Entire buildings had to be rebuilt. Data is no different, but tech moves faster. If data is not solid from the start, your AI project won’t stand for long.
Phase 1: Clarify Your AI Strategy and Use Cases
Building a home gym for a rower looks very different from one for a ballerina. With the same square footage, they’ll need to work different muscle groups, meaning wildly different equipment lists. AI’s the same: start with the muscle you need to build (the specific business problem you’re solving), not the AI tool you want to buy (the equipment).”
Here are three industry examples of how to match the data you collect to the AI use case you want to solve
Insurance: Define the right data for fraud detection
Let’s say that an insurance provider wants to automate fraud detection using AI. That’s too vague to act on, so start by setting a concrete goal. For example, reducing the number of false claims that reach a claims handler by 30%. With a measurable target, you can immediately narrow the data you need.
In this case, useful sources could include:
- Historical claims with clearly labeled outcomes (fraudulent or not)
- Adjuster notes, structured wherever possible
- Third-party data, such as location risk, prior claim history, and other risk scores, keeping legal and privacy constraints in mind.
Not all data will be ready to use straight away. Some sources require significant processing before they add value. Call center logs and chat transcripts, for example, are still data, but they won’t help until they’re transcribed, cleaned, and mined for patterns like unusual account access requests or inconsistent customer stories.
Website clickstream data is another possible input. It’s only useful for fraud detection if you can reliably link it to a known applicant and spot suspicious behaviors, such as repeatedly changing details in a quote form or altering claim information across multiple online sessions. Without that identity link, clickstream is just noise.
The team must be able to justify both the choice of data sources and the effort required to make them usable. They must weigh that against how much it will actually improve fraud detection.
Manufacturing: target the signals that predict machine failure
Say you’re manufacturing brake parts for cars using precision cutting machines and automated assembly lines. If one machine stops unexpectedly, it can disrupt your production schedule and delay shipments to your automotive clients by weeks. If your goal is to cut these unplanned shutdowns in half, you need to monitor the right signals.
Focus on data like abnormal vibrations, unusual motor strain, or drops in lubrication pressure, early indicators that components may fail. Real-time, machine-specific readings give AI models the context they need to predict failures before they happen.
You don’t need badge swipe records, monthly inventory audits, or forklift pallet counts. Those inputs won’t help your AI predict spindle overheating or bearing wear. Collecting irrelevant data wastes time, storage, and analytic effort. Targeting the right signals is how you make AI actionable and tie it directly to your production goals.
Higher education: spotting dropout signals early enough to matter
Let’s imagine that in higher education, a university wants to lower student dropout rates by 20%. The challenge is spotting who’s likely to leave in time to intervene. Most schools have plenty of data, but it’s patchy, delayed, or split across systems that don’t talk. That makes early intervention difficult.
GPA is usually the go-to signal, but first-semester grades land weeks after the damage is done. If a student is disengaging in October, waiting for December transcripts doesn’t help much. Attendance might work better, assuming it’s tracked. In practice, some professors take roll religiously; others don’t bother. Hybrid classes blur the picture even more. One student shows up in person, another joins online with their camera off, and a third logs in, walks away, and still gets credit for “showing up.” If the data team defines what matters and how it should be captured, they can set governance rules that clean things up and give the AI a real shot at making an impact.
Once leaders lock the metric, “data readiness” stops being a fuzzy ideal and turns into a checklist:
- Are we collecting the right information?
- Is it detailed enough to be useful?
- Is it available quickly enough when we need it?
Often enough, that exercise alone kills half the misfocused AI projects. These examples show how use-case clarity leads to better data decisions. They’re also part of a wider shift in how organizations think about data strategy.
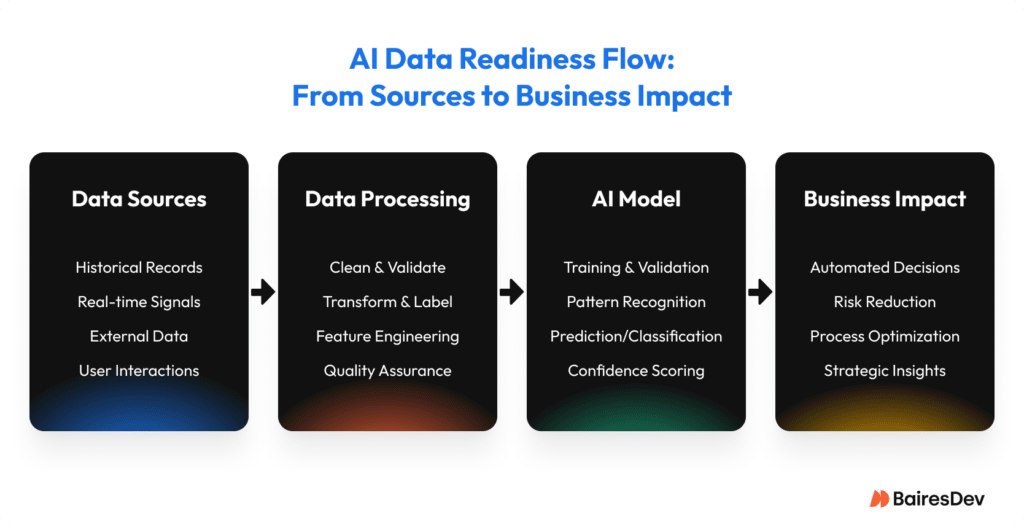
Phase 2: Understand and Organize Your Data Assets
Some problems look technical but are really organizational. It’s like putting the right parts on the wrong shelf. Everything you need is technically there, but good luck building anything with it. Strong data management practices help ensure that your assets are organized, maintained, and governed in a way that sets AI efforts up for success
Picture this: a logistics company assembling what appears to be a solid dataset: warehouse scans, driver logs, and truck schedules, all neatly timestamped and stored. They’re using it to predict and avoid delivery delays. But the model keeps flagging issues that dispatchers swear didn’t happen.
The culprit? Forklifts logged activity in local time, while the rest of the system ran on Eastern Time, matching headquarters. That timezone mismatch made everything look out of sequence. Flagging shipments as late when they weren’t can be pretty upsetting for the drivers who’ve spent hours on the road. It’s pretty confusing for an AI that’s trying to fix delays that aren’t happening. This wasn’t a failure of the algorithm. It was a failure to align and standardize the data.
To organize your data in a way that doesn’t sabotage your AI later, focus on three basic things: inventory, quality, and integration. Our data management services help teams establish ownership, standardize definitions, and clean inconsistencies before they impact models.
Inventory – What exists, where it lives, who owns it?
If five teams are tracking the same process in five different tools, you don’t have five sources, but you have five versions of the truth. Without clear ownership, cleaning, and updates, it’s impossible to know whether that data is reliable.
Quality – Is it complete, current, and consistent?
It’s easy to assume a field is usable because it exists in the system. But what’s actually inside matters. For example, in healthcare, pain scores might be recorded as 1–10 in one hospital, “mild/moderate/severe” in another, and “OK” or “not OK” in a third. The field name is the same, but the meaning varies, leaving AI to interpret human shorthand instead of assessing medical risk.
Integration – Can systems talk without Excel hopscotch?
There are many companies with the right data trapped in tools that don’t connect.
Take a consumer goods company trying to optimize its demand forecasting. Sales data lives in the CRM, promotions sit in the marketing ad platform, and inventory lives in the ERP. In theory, it’s all there. But the sales team, the warehouse, and marketing each have their own product taxonomy: “Charcoal Grill – XL” becomes “BBQ-Grill (Large)” and then “OutdoorCooker_03”.
To the model, they’re unrelated products. Instead of recognizing a successful promotion and ramping up supply chain response, the AI treats them as separate, unrelated SKUs. The result? Forecast accuracy drops to coin-flip territory.
Phase 3: Evaluate Your Data Infrastructure
Your data is clean, labeled, and coming from the right sources, but you still might not be ready yet. If it moves through the wrong systems or too many of them, it’s like pumping filtered water through rusty pipes. What comes out the other end isn’t what you started with.
1. Map the path from raw to AI-ready
Ask your engineers to sketch one use case end-to-end. Count the “hops” (each handoff between tools, systems, or teams). Two hops (e.g., raw → data lake → feature store) is workable. Three or more (raw → spreadsheet → SharePoint → BI tool → analytics platform) means delays, data drift, and higher error rates.
2. Fit-for-purpose systems
Good data also depends on where it lives and how it moves. A few questions help senior leaders see trouble coming:
- Are your pipelines fast and stable enough to move large volumes of data without lags, drops, or format changes? Slow queries and batch job failures are the first sign your infrastructure is undersized.
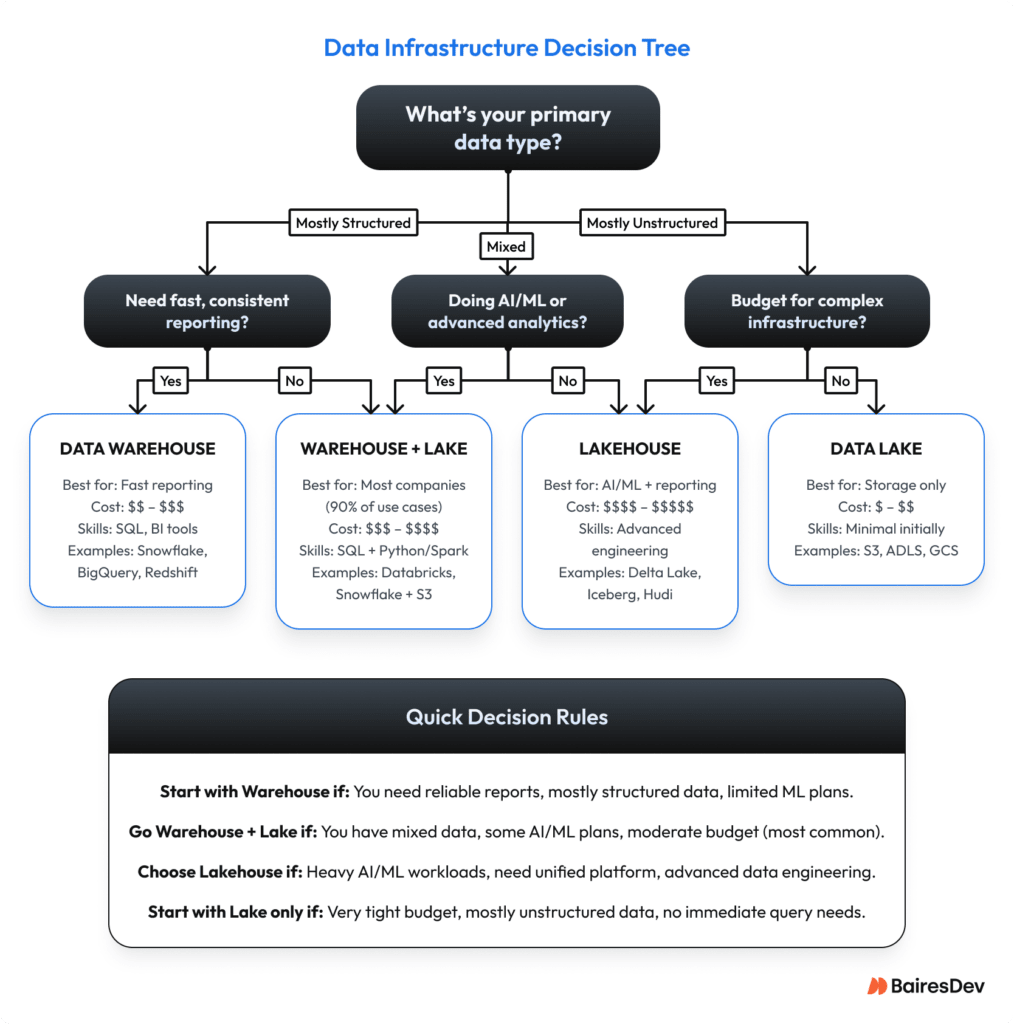
- Do we need a data lake, a warehouse, or both?
- Warehouse: highly structured, quick answers, good for finance-grade reporting.
- Lake: lower-cost storage, flexible schema, good for unstructured or semi-structured data such as clickstream or sensor feeds.
- Lakehouse: combines both. Most valuable when teams truly need large-scale flexibility and warehouse-level performance.
Many firms discover a conventional warehouse plus a modest lake covers 90% of needs, but workloads and business priorities should drive the choice.
3. Compliance you can prove
GDPR, HIPAA, and their cousins all require end-to-end lineage. Keep audit-ready, tamper-evident logs that answer who touched what, when, and where. If consent status is unclear at any step, the model stays on the shelf. Data you can’t legally use is worse than no data at all.
4. Security that matches data sensitivity
Security must also keep pace with data value. Sensitive customer data should be encrypted from source to destination, in transit and at rest. Role-based access, least-privilege policies, and detailed audit logs belong on the training data just as much as on the final model. Cloud AI services need equally fine-grained controls and real-time monitoring.
5. What “good” looks like in data infrastructure
Here’s a real-life example from a client project we worked on. A global freight logistics company wanted more accurate, AI-powered shipment pricing. Their data was there, but slow pipelines made forecasting difficult. We helped them streamline how data moved into their models by upgrading their data infrastructure and implementing automated quality checks, eliminating delays and duplicate requests. Their pricing model now delivers accurate rate recommendations almost instantly and can scale as demand grows. This helps the company respond faster to market changes and improve revenue predictability.
If you’re looking to do the same, explore our AI development services.
6. Advanced architecture considerations
For more ambitious AI workloads, a few strategic infrastructure decisions can have an outsized impact:
- Centralize your data with a feature store so models can reuse inputs safely and consistently.
- Think about cloud-friendly setups to get the right balance of speed, storage, and cost.
- For real-time or sensitive tasks, consider edge or hybrid setups. They help avoid slowdowns and keep you compliant with operational or regulatory rules.
Phase 4: Build the Right Data Team
Strong AI initiatives rely on having the right expertise in the right roles. Beyond being considered technical jobs, they’re business-critical functions that connect your AI projects to meaningful outcomes. Every link in the chain needs a clear owner. Otherwise, gaps surface quickly.
Data engineers
They are responsible for making the right data available, usable, and in the right format. They gather inputs from across systems, clean them, and structure them so teams aren’t wasting time fixing the same issues repeatedly.
Data scientists
They turn business questions into working models. Using clean data from engineers, they explore patterns and build algorithms that solve specific problems like predicting customer churn or optimizing pricing. They design, test, and validate models before handing them off to ML engineers for deployment.
Machine learning engineers
Once a model is built, an ML engineer makes sure it runs reliably at scale. They handle version control, monitoring for errors, and making sure there’s a rollback plan in case performance drifts. Their focus isn’t just maximum accuracy, it’s dependable, maintainable deployment.
AI integration engineers
AI integration engineers are an increasingly important role in the era of large language models (LLMs). These engineers connect AI systems to existing tools, like CRMs, support platforms, or internal knowledge bases, so they work seamlessly in day-to-day operations. They’re often responsible for implementing RAG (retrieval-augmented generation) systems that allow AI models to pull from your specific documents and data in real-time, rather than relying solely on their training data. Their understanding of both AI behavior and system architecture prevents costly deployment delays.
Data product owners
They are the bridge between business goals and technical execution. Whether it’s reducing churn, improving forecasting, or cutting downtime, they keep the work grounded in outcomes that matter to the organization. They’re the one asking, “Is this model actually helping us hit our goals?”
Data stewards
They’re the keepers of data quality and compliance. A data steward can be a dedicated role, or the responsibilities might sit with someone already in another position, like a business analyst or data engineer. Their job is to make sure every piece of data is accurate, up to date, and legally and ethically usable. They help the organization stay audit-ready and reduce risk when regulations change, keeping data trustworthy for every team that relies on it.
These specialized positions can be tough to fill and even tougher to fill well. If you’re building out your data team or need to bring in AI experts who actually understand how to connect models to business results, we can help.
Phase 5: Foster a Data-Driven Culture
Data rot isn’t always about incompetence; sometimes it’s just human nature. People take shortcuts and dashboards get cloned. Teams track what helps them hit targets, not what makes downstream systems hum. That’s a normal part of not being a robot. Over time, these shortcuts crystallize into “how we do things.” Before long, your AI is running on a foundation of copy-pasted numbers and undocumented workarounds.
A quick pulse check can tell you whether data health is truly part of the organization’s everyday mindset:
- Visibility. Do executives see a data-quality indicator in the same place they track revenue and conversion? If quality metrics sit in a separate tool or nowhere at all, the hidden message is that “someone else” owns them.
- Source of truth. Can every team point to the canonical dataset for the KPIs they report? If not, you are paying a “multiple-truths tax” in meetings, rework, and model drift.
- Ownership. When data breaks, is there a named owner who logs, fixes, and closes the issue, or does it get passed around like a hot potato?
- Accountability. Do employees feel personally responsible for the accuracy of the data they handle, or is quality viewed as a back-office chore?
If clean data is “everyone’s job,” the organization has to make it matter to everyone’s job.
An example of who’s doing it right
Airbnb bakes data health into the same surface its teams use for business metrics. Its Minerva platform acts as a single source of truth for analytics, reporting, and experimentation, eliminating multiple-version chaos.
But its company-wide Data Quality Score is what’s truly impressive. Calculated daily and displayed next to every dataset inside Dataportal, the score measures four weighted dimensions: accuracy, reliability, stewardship, and usability. It’s visible to both data producers and consumers, creating natural incentives to improve quality and to choose high-scoring datasets without relying solely on top-down enforcement.
Make Data Your Superpower for AI Success
You wouldn’t build a house with corroded steel beams, launch a product without QA, or fuel a plane with watered-down jet fuel. Yet many companies try to launch AI initiatives on data that’s incomplete, conflicting, or unusable.
Before you invest in another AI pilot, invest in making your data ready for AI, and that means more than cleaning up a few spreadsheets. It requires visible, owned, and embedded data quality practices that are part of how people already work. When data health is integrated into everyday decision-making, cultural habits shift, and AI readiness becomes everyone’s responsibility, not just a technical team’s. Data health becomes an organization-wide capability, one that makes every AI initiative faster to deploy, easier to trust, and far more likely to deliver real results.




