

You thought you staffed the right team. Two data scientists, one engineer. Smart people. Great resumes. But three sprints in, the dashboard is still broken and all you get are promises about when things will be fixed. Meanwhile, marketing delays a $2M campaign because the churn model isn’t ready.
This is not a talent problem. It’s an issue with role clarity. The line between data scientist and data engineer often blurs during hiring. That’s the perfect incubator for missed deadlines and frustrated teams.
When data scientists are expected to fix pipelines, or engineers are pulled into model tuning, progress stalls. You get fragile systems and skewed insights because no one has the bandwidth to do both jobs well.
In scaled environments, this ambiguity can cost millions in lost opportunities. Analysts wait weeks for clean data. Engineers patch brittle ingestion logic just to keep daily jobs running. Scientists waste time interpreting incomplete outputs.
The fix starts with sharper definitions. This article maps how each role contributes to the data pipeline and why analyzing data or building data visualization depends on that division.
In brief:
- Data scientists use tools to spot patterns.
- Data engineers build the systems data scientists use.
Data Scientist vs. Data Engineer
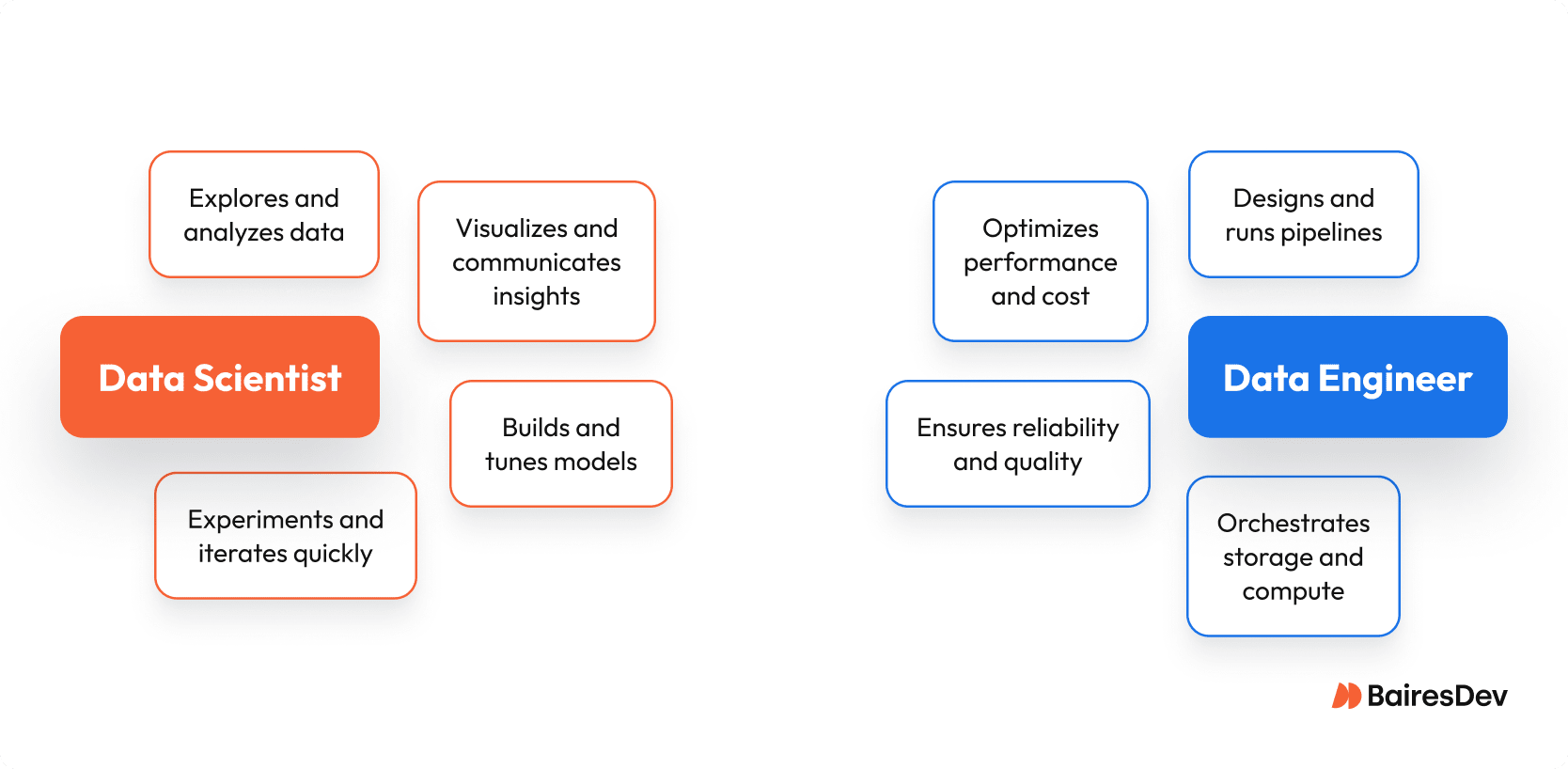
Data scientists use data analysis to build business insights. Data engineers build data infrastructure. Engineers build and monitor the pipes, data scientists turn what flows through them into decisions. The right role doesn’t depend on tools but on mindset and impact.
The data scientist role is more than dashboards, and data engineering is more than storage. These jobs reflect different ways of thinking. Each one is critical to scaling real-world data science projects.
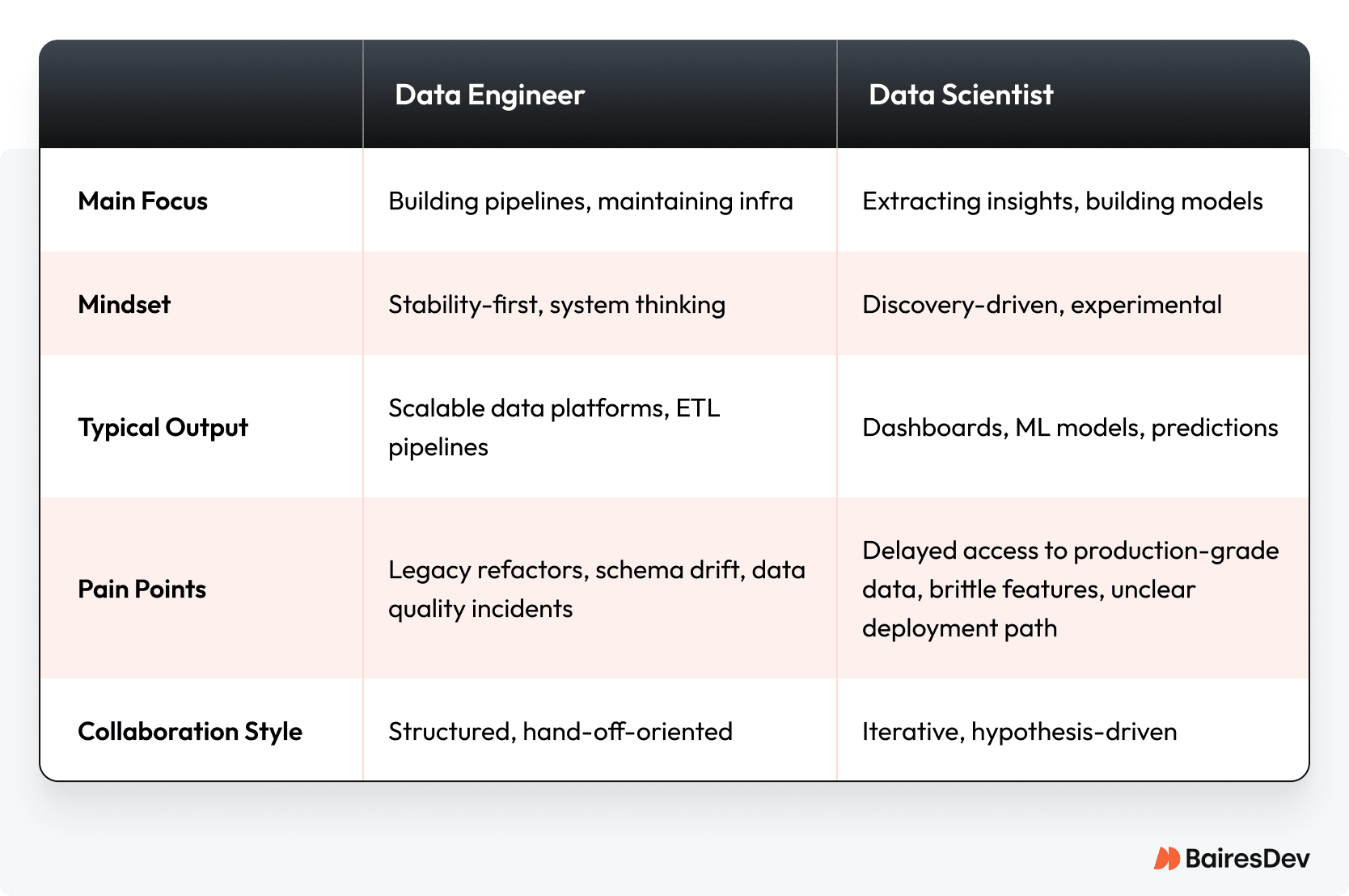
Engineers and data scientists share the same goal: business impact. But how they get there couldn’t be more different. Data scientists focus on exploring messy data sources, seeking patterns that inform decisions. Engineers work on data reliability, uptime, and scale. Top teams respect both roles.
Tools of the Trade
Tools reinforce habits, workflows, and priorities. The tools used in data science and data engineering reveal the primary focus of each role, from system stability to statistical analysis.
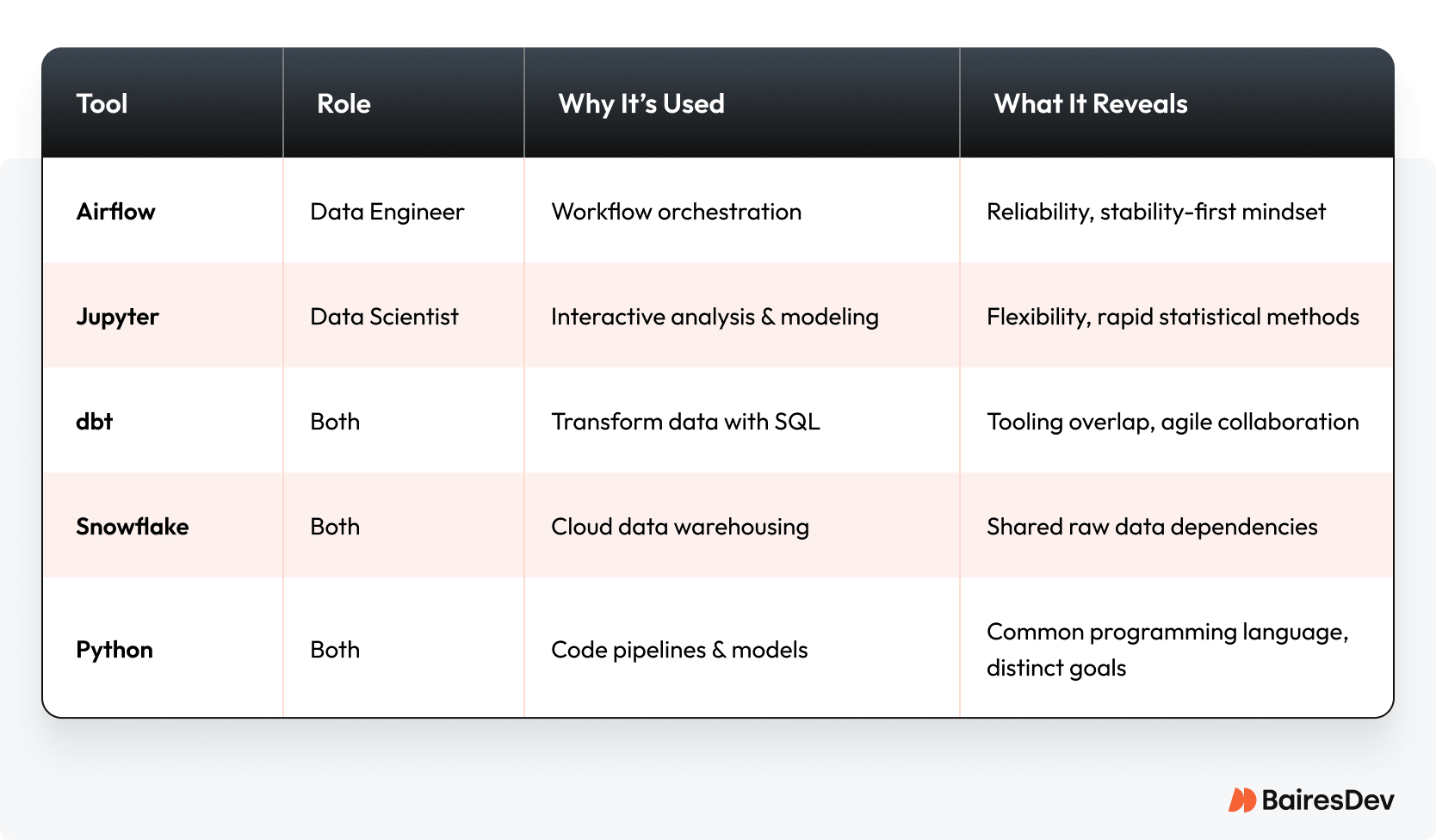
Airflow orchestrates workflows. Jupyter is for discovery. Think of it as an open notebook for testing machine learning algorithms and building predictive models.
Both engineers and data scientists use dbt. It lets many them prepare data without deep backend skills. But misuse it, and you inherit hacky SQL layers that break at scale. For example, a data scientist might use it on raw marketing data for a churn model. But if they skip tests or documentation, a schema change can break forecasts downstream.
Snowflake can unify access but it won’t erase friction. In the wrong hands, shared platforms can lead to too many cooks in the query.
As The Data Science Handbook shows, tech is only half the story. The best teams know when to hand off and when to collaborate to solve business problems, not just write code.
Day-to-Day Work: From Refactoring to Modeling
Tempers can flare when teams ignore the feedback loop. One side’s stuck refactoring while the other’s backed up in model blocking. This is the daily grind of both roles, and this is where the real collaboration happens.
What Data Engineers Do
Data engineers spend a lot of time coding. Here’s what their day-to-day looks like:
- Build and maintain data pipelines: Automate and optimize ingestion from raw data sources to warehouses.
- Debug ingestion jobs: Fix failures in scheduled workflows that disrupt real-time or batch data flows.
- Handle schema drift: Adjust systems when upstream data structures change without notice.
- Develop scalable systems: Ensure infrastructure can handle growth in data volume and complexity.
- Support data reliability: Monitor pipeline health and resolve data quality issues quickly.
- Collaborate on cloud platforms: Use Airflow to orchestrate jobs.
- Optimize big data technologies: Tune Spark, SQL, and storage systems for performance and cost efficiency.
What Data Scientists Do
Data scientists turn raw data into business intelligence. For many, the daily grind looks like this:
- Explore datasets: Explore structured and unstructured data to understand trends.
- Run machine learning algorithms: Use models to classify or predict outcomes from complex datasets.
- Tune predictive models: Optimize model performance through feature selection and parameter tuning.
- Visualize data: Many data scientists use matplotlib to create actionable visualizations for key stakeholders.
- Perform statistical analysis: Apply statistical methods to validate findings.
- Run A/B tests: Design experiments to evaluate product or strategy changes based on performance.
- Communicate findings: Translate technical insights into business impact through reports.
- Collaborate across data infrastructure: Work closely with engineers to access clean data and deploy production models.
Why Collaboration Matters
The two roles build trust when they collaborate. An organization needs both engineers who understand experiments and scientists who respect constraints. As Hilary Mason says, agile data teams thrive when walls come down. Think cloud platforms, shared repos, and mutual respect vs siloed science.
How the Roles Interact
You won’t get far with data pipelines if your team doesn’t play well together. And yet, data engineers and data scientists clash all the time over mismatched tools, unclear boundaries, blocked workflows, and more.
When data engineers struggle with unstable schemas, they may spend days rewriting transformation logic. Meanwhile, data scientists stall out waiting for access to production-ready data sources that never come on time. This back-and-forth can turn into a weird turf war.
But it doesn’t have to. Teams that float between both worlds—like analytics engineers using dbt—solve data problems in tandem. Shared platforms like Amazon Redshift provide a common data warehouse, but without clear ownership, they can just as easily create friction as remove it.
The Netflix Tech Blog often says alignment beats tools. When data professionals share metrics and use collaborative environments like Jupyter Notebooks, the work flows. To be like Netflix, avoid silos and build good communication habits.
The Rise of Hybrid Data Roles
CTOs are under pressure to deliver more ROI without growing headcount. That pressure often exposes a structural gap. Traditional org charts split data science and engineering into silos that can slow delivery and increase rework.
Hybrid roles like Analytics Engineers and ML Engineers help close that gap. They blend computer science foundations with data modeling and visualization skills, merging infrastructure and insight.
Analytics Engineers apply software engineering principles to the analytics layer. They write transformation code that’s versioned and maintainable. That improves model reliability and speeds up access to trusted metrics. ML Engineers reduce time-to-deployment by automating training and testing pipelines.
To staff hybrid roles effectively, start by identifying bottlenecks between data processing and insight delivery. Let’s say data analysts are waiting on engineering for cleaned datasets. Analytics Engineers can apply software practices to data processing and free analysts to focus on interpretation. ML Engineers can move models smoothly from notebooks to deployment. That can close the loop between experimentation and impact.
The Cost of Getting It Wrong
If you want to deliver actionable insights faster, define the key differences between data science and data engineering. Infrastructure slows when engineers deal with ad hoc requests that scientists should handle.
Here’s what happens when the line between roles is ignored:
- No one owns the pipeline: Data engineers build it, but no one maintains tests or docs.
- Analytics become fragile: Scientists model on unstable layers and lose stakeholder trust.
- Insights don’t land: Data analytics is treated as a feature instead of a strategic asset.
- Infra work gets buried: Engineers refactor endlessly while high-leverage work stalls.
Successful teams start by defining who does what—and hiring for it. Strong data engineering skills set the stage. Data scientists create the narrative. The outcome? Cleaner workflows, fewer surprises, and insights that scale.
Org Design That Supports Scalable Data Strategy
CTOs fail when they focus on hiring talent without first designing the right architecture around them. In that scenario, smart people get stuck interpreting data from machine learning models that never should’ve gone to prod.
A scalable data strategy begins with thoughtful org design. That means more than centralizing data roles in a platform team. Instead, map roles to business outcomes and fix the flow between engineering and insight.
The best organizations implement hybrid pod structures. They embed analysts and scientists with centralized engineers. In this setup, engineers govern data storage and ensure data quality. Meanwhile, domain-aligned scientists focus on the modeling.
Make sure scientists don’t own production and engineers don’t own experimentation. But be clear that both need visibility. Shared metrics and cross-functional retros help teams understand what’s working and where friction lives.
Role Clarity Drives Delivery
Clear role alignment is both a hiring best practice and a delivery accelerator. When teams know who owns data generation or modeling, they move faster with less rework. Cloud computing and modern pipelines have blurred some boundaries, but the need for specialization hasn’t gone away.
Data engineers bring the technical skills to architect scalable infrastructure. They manage storage and orchestrate pipelines. Data scientists apply statistical models to uncover patterns.
Both roles require fluency but not duplication. When roles are defined and respected, organizations unlock real-time insights and faster model deployment. Structure drives velocity.
At BairesDev, we build cross-functional teams where engineers and data scientists collaborate and scale. From database management to modeling, from data engineering to insight, we make it fit the priority.
Frequently Asked Questions
How do we decide what to hire first?
Start with reliability. If data freshness and quality miss SLOs, hire Data Engineering/Analytics Engineering. If reliability is solid but decisions are slow or ad hoc, hire Data Science and ML Engineering.
Can one person handle both data science and data engineering?
In high-growth teams with high demand, hybrid roles exist. But blending discovery and infrastructure long-term can lead to burnout and project delays.
When should an organization hire a data scientist vs a data engineer?
If the company lacks clean, scalable pipelines, start with engineering. If pipelines are solid but insights are missing, hire a scientist. Let the key stakeholders’ needs guide the hire.
Is data engineering relevant to web development?
Yes. While not the same, both rely on backend systems and performance optimization. A data engineer develops the infrastructure that supports scalable apps, not just analytics.
How do data scientists and engineers collaborate on shared platforms?
Collaboration works best when responsibilities are clear. On platforms like BigQuery, access is shared but ownership must be defined to prevent overlap.
What skills should a data engineer learn to work with machine learning teams?
To support ML workflows, a data engineer should understand data manipulation, model input requirements, and basic machine learning concepts. Skills in Python, feature engineering, and scheduling tools like Airflow help ensure that pipelines deliver reliable data.
What KPIs should leadership track monthly?
Your team should track six KPIs: freshness SLO attainment, mean time to recovery (MTTR), dbt test coverage, percentage of production models under monitoring, deployment lead time, and the incident root-cause mix.




