

Ten years ago cloud computing advocates sold executives on one simple promise: trim the capital bill.
Those early migrations, mainly lift‑and‑shift file servers and dev sandboxes, delivered savings only on paper. Once workloads escaped the data‑centre cage, product teams began shipping faster, customers demanded richer features, and cloud infrastructure quickly turned from cost line item to competitive weapon.
Many large organisations still treat the cloud as just another tech expense. They settle invoices, move a handful of workloads, and assume the job is finished. It is not. Meaningful returns appear only when every decision aligns with architecture, cloud model, and business objectives.
How does that alignment work in practice and how do we avoid the short‑sighted traps that stall progress?
Why the Cloud Matters Now
Speed, predictability, and global reach once required significant capital. Public hyperscalers changed that equation, and organizations increasingly pair these platforms with cloud application development services to accelerate delivery. Teams could dial up resources in minutes, replicate across regions with a few API calls, then scale down again when traffic ebbs. Elasticity is important, yet it is not a differentiator by itself. Leaders attach cloud capabilities directly to revenue, risk posture, and talent strategy.
Consider a financial-services client that modelled branch-level outages. By distributing its core ledger across three cloud regions, supported by systems integrated through ERP development services, the bank lowered potential downtime per incident from hours to minutes, keeping customer churn in check and satisfying strict regulatory audit windows. The cloud infrastructure project appeared on the balance sheet under customer retention, not cost reduction.
A contrasting retail example shows how response to seasonal traffic changed. Before migrating key services, a retail chain ordered hardware in March for end‑of‑year bursts and endured long depreciation cycles. After re‑platforming on a managed container service, capacity decisions shrank to a daily forecast. That shift freed budget for marketing experiments that directly improved holiday conversions.
What Enterprise Cloud Actually Means
At enterprise scale the cloud is not one thing. It blends managed compute, event services, data platforms, and governance tooling into day‑to‑day operations. Front‑end developers push containers to managed clusters, data scientists query vast lake houses without pleading for storage, finance tracks usage curves in near real time, and security monitors posture continuously. None of that happens if cloud resources remain a side project.
Enterprises rarely start on a clean slate. They juggle mainframe interfaces, regional data‑sovereignty laws, legacy vendor licences, and security teams who grew up defending fixed perimeters. Integrating cloud services into that mix demands sober planning and staunch realism. Quick wins exist, but momentum fades if foundational issues stay unresolved.
Understanding Cloud Deployment Models
Unlike two decades ago, engineering teams now have a few distinct cloud models to consider:
- Public cloud services, such as Amazon Web Services or Microsoft Azure, offer enormous scale and flexibility, but they also introduce questions around control and security.
- Private clouds, built in-house or through a specialized vendor, offer tighter oversight but at a higher cost and complexity.
- Hybrid cloud setups, combining private and public clouds.
- Multi-cloud solutions, where companies work with several providers to balance strengths and reduce risks.
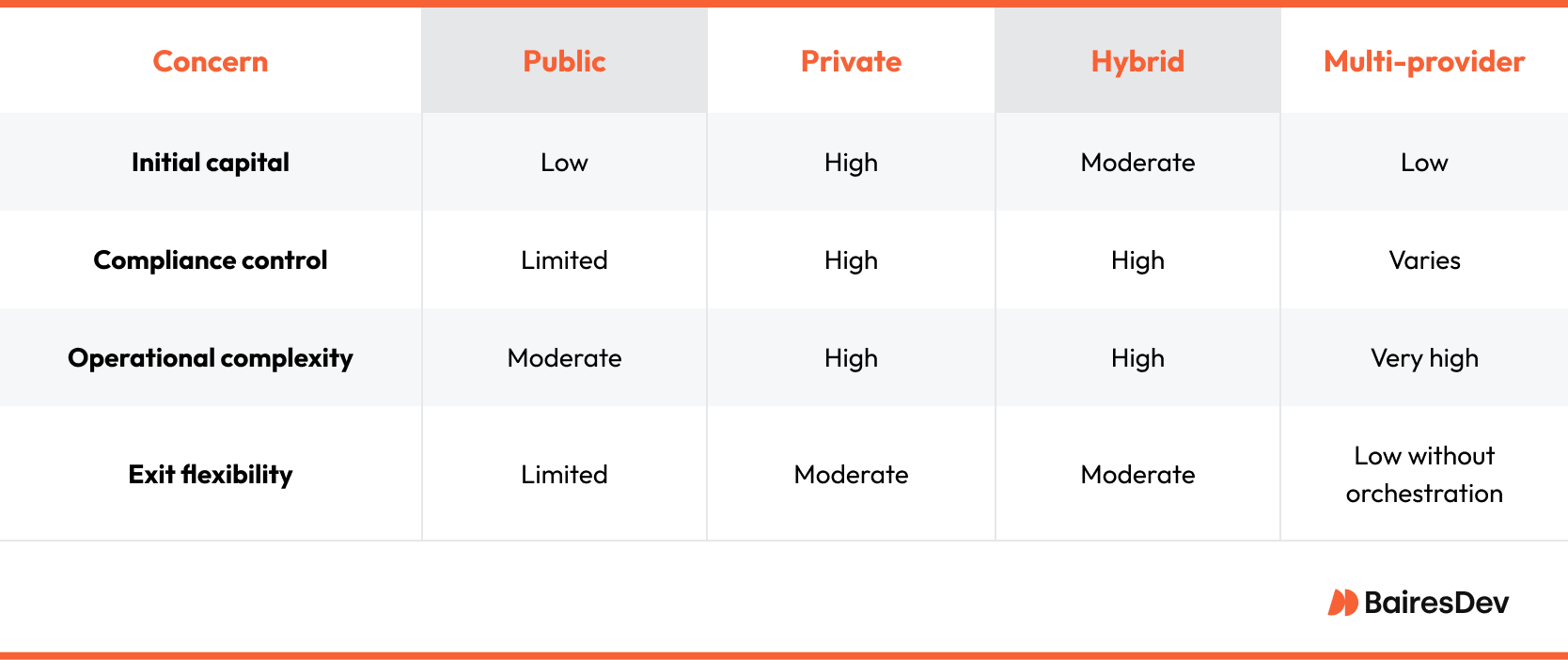
Public cloud services offer maximum elasticity and a relentless feature stream, ideal when time to market outranks granular control. Private platforms give governance purists the audit trail they need, provided the company funds hardware refresh cycles and patch management. Hybrid environments blend the two, a pragmatic choice where latency to plant‑floor equipment or national data rules block wholesale migration. Multi‑cloud strategies go further by mixing providers to limit vendor risk or to sit workloads close to specialised services.
A pattern worth noting is single‑workload poly‑cloud using multiple cloud service providers. For example, one multinational handles payments on Azure for proximity to its ERP, trains large language models on Google Cloud GPUs, and serves consumer media from AWS edge nodes. The architecture works, yet the integration and monitoring overhead is real. Exit costs rise quickly when each component leaves on‑prem norms behind, so documenting breakpoints and setting rational ownership boundaries becomes essential.
The table below maps common concerns to each pattern.
Benefits and Hidden Caveats
Cloud platforms deliver genuine value, yet it arrives with a long footnote. Enterprises that acknowledge these caveats early avoid disappointment later.
- Elastic scale keeps Black Friday or playoff streaming from melting sites, but unmanaged auto scaling can drive six‑figure surprises. FinOps practices such as mandatory cost allocation tags, enforced idle shutdown rules, and weekly utilisation reviews tame the risk.
- Geographic resilience lowers recovery objectives, yet only if runbooks, DNS fail‑over, and application retries are rehearsed instead of theorised. Chaos drills expose gaps before real incidents do.
- Operational expenditure instead of capital expenditure funnels cash to product experiments, though finance teams need fresh metrics. Amortised servers are predictable; pay‑as‑you‑go bursts need near real‑time alerts. Show‑back dashboards help engineers police their own usage.
- Innovation velocity rises as teams consume managed AI, stream processing, or edge runtimes. The trade‑off is version churn and a skills treadmill that never stops. Budget time for continuous learning, or technical debt will accumulate around obsolete APIs.
Common Knots and How to Untie Them
- Governance drift occurs when any engineer can spin a cluster in thirty seconds. Tag hygiene, identity boundaries, and budget caps must live in automation workflows or shadow platforms will bloom.
- Lock‑in by surprise happens when free trials lure teams onto proprietary data stores. Designing abstraction layers or at least documenting exit paths keeps negotiation leverage intact.
- Legacy gravity surfaces when a nightly batch to a mainframe anchors a cloud‑native pipeline. Wrapping the legacy service behind an API and mirroring data to a cloud store buys breathing room while longer rewrites are planned.
- Culture lag emerges if procurement still writes six‑month hardware requests or if security insists on ticket‑based firewall changes. Adopting cloud rewires budgeting, risk analysis, and incident response norms.
A regional insurer recently fell into governance drift when developers used unmanaged keys to push customer PII to a third‑party analytics tool. The fix blended technical guardrails, such as automatic policy checks on new buckets, and an internal awareness campaign. Within three months untagged resources dropped by eighty percent and audit exceptions returned to normal levels.
FinOps in Action
Cost control in elastic environments is continuous. The most effective teams implement three simple feedback loops.
- Daily spend digest posted to a shared channel keeps usage visible. Engineers quickly delete forgotten test clusters once costs show up next to their names.
- Monthly business unit scorecards map consumption to value delivered. One retailer pairs site revenue per minute with hosting cost per minute, letting product owners justify or slim spending.
- Quarterly architecture reviews examine per service cost trend lines and recommend reserved capacity, refactors, or provider renegotiations.
These rituals shift the conversation from blame to optimisation and keep finance, operations, and engineering aligned.
Cloud Service Model Nuance
Infrastructure services keep operations staff close to the operating system and network stack. Platform services lift that burden, yet restrict configuration freedom. Software delivered as a service removes infrastructure toil completely but narrows integration points. Successful enterprises match service model to differentiation. Control the pieces that underpin competitive advantage, offload the rest.
A decision matrix used by a media group illustrates this mindset.

Nearshore Engineering, Filling the Gaps
Cloud programmes live or die on experienced hands who understand Kubernetes admission controllers, least‑privilege identity policy, and cross‑account networking quirks. Those profiles are scarce and mobile. Nearshore partners supply senior talent without multi‑day timezone lag, letting architecture debates and code reviews happen synchronously.
Onboarding guidance for such teams includes a single backlog, shared stand‑ups, peer code reviews, and access to the same monitoring dashboards as in‑house engineers. Treating partners as embedded colleagues avoids the ticket‑tossing void that traditional outsourcing created.
Success metrics focus on lead time for change, change failure rate, mean time to recovery, and service cost per feature. One telecoms client cut MTTR by forty percent in six months after pairing its operations lead with a nearshore site‑reliability squad.
Security as Continuous Discipline
Providers patch hypervisors and rotate physical hardware, yet customers still misconfigure storage, over‑permission service roles, and leave old tokens in code repositories. A strong baseline contains automated guardrails that quarantine public buckets, short‑lived credentials backed by enterprise identity, real‑time asset inventories, and compliance expressed as code.
A bank using these principles embedded policy checks into its deployment pipeline. Every push triggered static analysis that blocked misaligned configurations before they reached production. Over twelve months security incidents related to misconfiguration dropped by half.
Maintaining a Living Roadmap
A credible roadmap answers vital questions of purpose, priority, and measurement.
- Purpose explains how each cloud initiative supports revenue growth, risk reduction, or talent leverage.
- Priority ranks applications by complexity, customer impact, and interdependency. Some firms begin with front‑end services, others prioritise disaster recovery.
- Measurement defines metrics such as deployment frequency, defect escape rate, mean time to restore, or compute spend per transaction. Publishing these numbers builds accountability.
Roadmaps age quickly. Quarterly review cycles, built‑in refactor budgets, and a contingency fund for unexpected provider services keep the plan relevant.
Looking Ahead
Cloud adoption has moved from a migration project to an operating discipline. Enterprises that weave cloud thinking into product cycles, risk frameworks, and hiring pipelines see benefits that persist long after the first victories. Those that stop at workload transfer discover, usually the hard way, that servers in another building still represent their responsibility.
The pressing question is not whether to migrate. That ship sailed years ago. Instead, leaders must ask whether the next twelve months will turn cloud spend into a differentiator. The answer rests in architecture choices, governance automation, and the engineers submitting pull requests on Monday morning. Nail those fundamentals and monthly invoices become an investment in staying relevant rather than a utility bill to grumble about.




