

Executive Summary
Most enterprise AI initiatives fail due to immature data foundations, not model limitations. This article outlines a pragmatic data maturity model and execution strategies. Together, they enable organizations to scale enterprise AI incrementally while strengthening data foundations and delivering real AI value in parallel.
Research shows many enterprise AI efforts still don’t make it out of pilot. In 2025, S&P reported that 42% of companies abandoning most AI initiatives before production. This data point underscores an execution gap driven more by data, governance, and integration challenges than model sophistication.
Many organizations are now confronting a painful paradox: the most capable AI models depend on strong, well-governed data foundations, yet those foundations are often immature. As a result, promising AI initiatives stall long before they deliver business impact. However, deploying AI does not require a sweeping, multi-year platform overhaul. With a pragmatic, engineering-led approach, organizations can make meaningful progress.
This article offers a practical blueprint for leaders facing that reality. It outlines a four-stage data maturity model for AI readiness. It also explains how organizations can progress through these stages without pausing AI initiatives, and shows how distributed data teams can accelerate foundational work without sacrificing control.
What Is the Four-Stage Data Maturity Model for AI?
The four-stage data maturity model describes the progression from fragmented, opaque data environments to continuously optimized AI-ready platforms. Progression is incremental and non-linear, but the stages provide a practical execution map.
That execution map matters because successfully scaling enterprise AI starts with an honest data readiness assessment of where your data infrastructure stands today. Across organizations at different levels of AI adoption, we consistently see four data maturity stages that strongly correlate with whether AI initiatives stall in pilot or reach production.
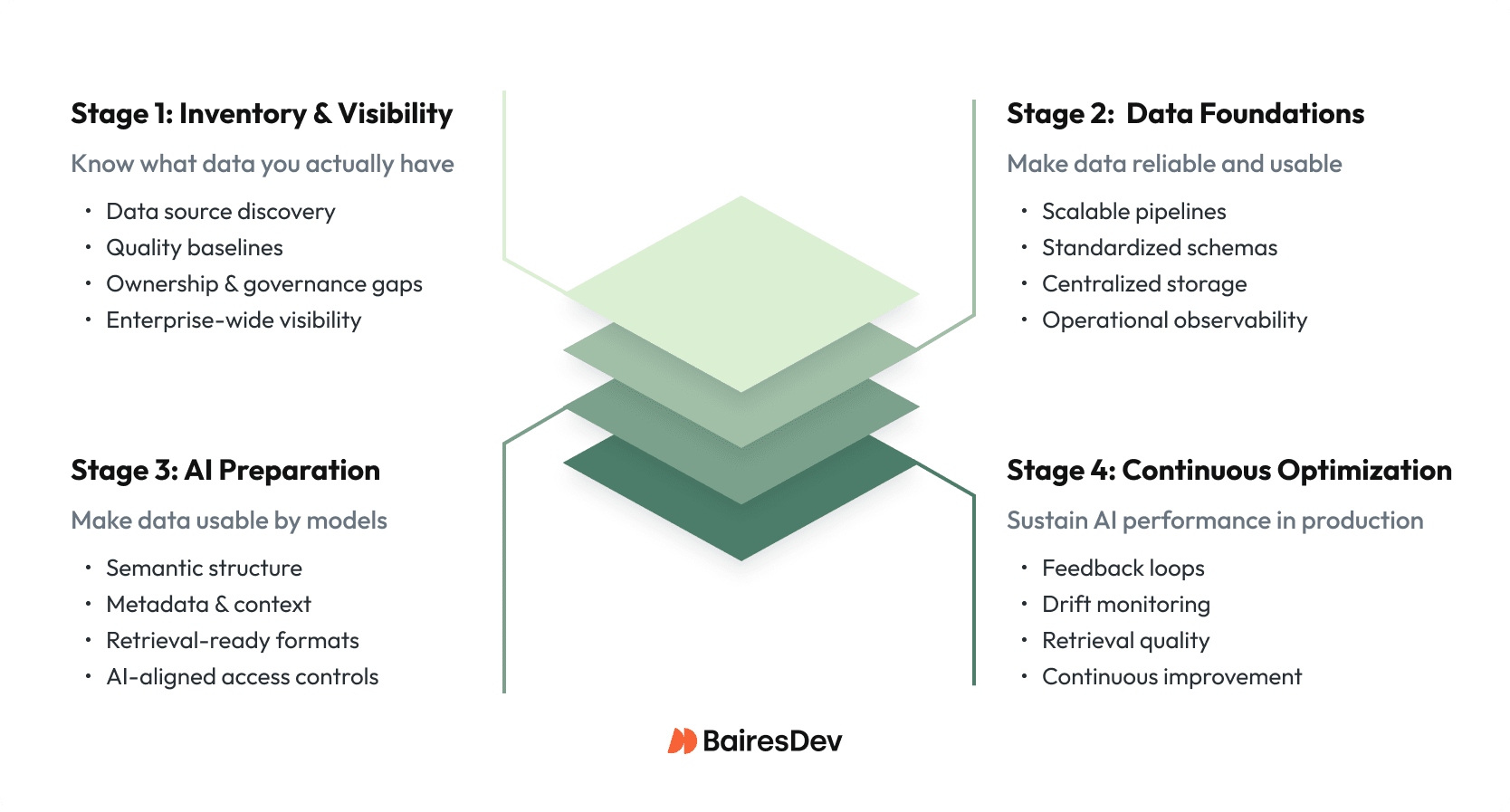
Stage 1: Data Inventory & Assessment
This stage focuses on identifying enterprise data sources, ownership, quality baselines, and governance gaps.
This is the low-key but essential starting point, and it’s where many organizations underestimate the effort involved. Teams catalog data sources across the enterprise, establish basic quality baselines through statistical profiling, and identify governance gaps.
In practice, this stage often reveals uncomfortable truths: dozens of shadow databases owned by no one, inconsistent naming conventions across systems, and no clear data stewardship model. The goal is visibility, not precision. Until teams can see what data they actually have, every downstream AI initiative is built on assumptions.
While building predictive maintenance algorithms for a SaaS organization focused within the connected retail refrigeration space, my team and I were tasked with sourcing not only volume of good/bad event data for different asset types, but also, data from different retailers with similar connected assets and environmental conditions. This data is critical by which to train our AI models for the use case of providing advanced notice of impending asset failures and the prevention of perishable losses.
Stage 2: Foundation Transformation
This stage strengthens core data infrastructure to support reliable, scalable AI workloads.
With a clear inventory in place, organizations can begin the harder work of strengthening foundations as part of a broader AI modernization roadmap. This typically involves building or refactoring ETL pipelines, implementing scalable data lakes or warehouses with well-defined schemas, and adding basic observability so failures don’t surface only after business impact.
The biggest risk at this stage is paralysis. Teams often lose momentum in prolonged architectural debates or platform comparisons. Focus instead on pragmatic improvements that unblock AI use cases, even if the architecture isn’t “perfect” yet.
Stage 3: AI-Centric Preparation
This stage prepares data specifically for AI consumption, retrieval, and reasoning.
Once data foundations are stable enough to trust, AI-specific requirements come into focus. This is where vector database implementation enables semantic search, teams apply richer metadata tagging to support retrieval-augmented generation (RAG) readiness, and transform raw data into formats that models can reliably consume.
This stage is where generative AI initiatives move from experimentation to go-live readiness addressing many common generative AI deployment challenges around accuracy, context, and trust. Data must be contextually rich, semantically structured, and traceable, otherwise even the most capable models will produce inconsistent or untrusted results.
Stage 4: Continuous Optimization
This stage ensures AI systems remain reliable as data, users, and models evolve.
AI in production is never “done.” As models interact with real users and evolving data, performance will drift unless it’s actively managed. This stage emphasizes feedback loops, monitoring for data and retrieval drift, and ongoing evaluation of response quality.
Organizations that reach this stage treat AI systems as living products, continuously learning, adapting, and improving alongside the business.
Can Enterprises Deploy AI Before Their Data Is Fully Modernized?
Yes. Enterprises can and should deploy AI while modernizing data in parallel. Treating data readiness as a prerequisite slows momentum and delays learning. The most effective organizations tightly couple foundational data work with AI delivery.
While at that same SaaS solutions organization, we built an AI-enabled knowledge base for all connected healthcare assets within core healthcare hospital systems. The solution was used by procurement personnel within the hospitals who were responsible for the purchases of high-value healthcare assets like EKGs, MRIs, X-Rays, and infusion pumps. Our consortium of data spans multiple hospital systems. This gives us a differentiating competitive advantage in the market. We used that as the basis for our LLM use case — specifically, to determine the lowest cost of ownership and highest ROI tied to specific asset types and models.
The hard truth is that most enterprises today are stuck between Stages 1 and 2. They’re approaching data modernization as a sequential, multi-year journey when it should be an agile, tightly coupled effort. With the right team structure and execution model, foundational data work and AI delivery don’t have to happen sequentially.
How Do Nearshore Data Teams Accelerate AI Readiness?
Nearshore development teams accelerate AI readiness by enabling parallel execution without sacrificing control. They expand delivery capacity while allowing internal teams to retain ownership of architecture and domain decisions.
Time is the scarcest resource in the AI race, which is why distributed data team models have become a meaningful competitive differentiator. When implemented well, nearshore development teams offer real-time collaboration, cost efficiency, and access to specialized enterprise data engineering and platform engineering talent that can be difficult to source locally.
The most effective implementations follow a hybrid model. Nearshore pods are embedded directly into internal teams, augmenting capacity without the disruption of wholesale outsourcing. Internal teams retain strategic control, architectural ownership, and domain expertise, while nearshore engineers execute in parallel—building data pipelines, automating quality checks, and accelerating infrastructure buildout.
When the right conditions for a nearshore development partner are in place, the impact is measurable. We’ve seen organizations compress data pipeline deployment timelines by 40–60% compared to internal-only teams. The reason is straightforward: while core teams stay focused on business-critical deliverables, a dedicated nearshore pod can simultaneously modernize legacy data sources, build new ingestion patterns, and prepare data assets for AI execution.
This model is about magnifying your team’s impact, not about replacing your team. One financial services leader described the shift as “suddenly having three hands instead of two.” Just as importantly, distributed execution creates built-in redundancy and knowledge transfer, reducing key-person risk in critical data platform initiatives.
Real-World Transformation
At the same SaaS organziation, we’ve been deep in the weeds of data readiness. As CTO, I’ve seen how even the most established accounting and assurance teams can struggle to bridge that execution gap. Here are a few examples of how we’ve helped our clients navigate these specific hurdles:
Financial Services: Building the Foundation for Intelligent Agents
A mid-sized investment firm set out to deploy GPT-powered research assistants for its analysts but quickly ran into a familiar obstacle: client data spread across six legacy systems, market data locked in proprietary formats, and no unified document repository. The ambition was clear, but the data foundations were not.
By augmenting its internal team with a nearshore data pod, the firm executed a six-month data lake modernization effort aligned to its AI scalability roadmap. The work focused on consolidating fragmented data sources, implementing appropriate access controls, and designing a retrieval-optimized architecture tailored for AI workloads. The outcome was a production-grade RAG implementation that gives analysts instant access to decades of research, precedent analysis, and client history. Routine research queries are now handled by the AI assistant, allowing senior analysts to focus on higher-value strategic work.
SaaS Tech: Knowledge Bases That Drive Operational Efficiency
A B2B SaaS organization faced a different challenge: a fragmented knowledge ecosystem spanning product documentation, support articles, and internal runbooks. Rather than attempting a full rebuild, the company introduced a retrieval-augmented AI assistant layered on top of existing systems.
By deploying an LLM-agnostic RAG solution, the organization enabled secure, role-aware, citation-backed responses for support agents in under eight weeks. A phased rollout that prioritized high-impact content delivered measurable results—average support resolution times dropped by 30–40%, Tier-1 ticket volume declined by 25%, and dependence on senior subject-matter experts decreased. Importantly, these gains came without compromising governance, accuracy, or data security.
How Should Enterprises Start When Their Data Is Not Ready?
Enterprises should start by gaining clarity, not chasing completeness. A focused data readiness assessment helps teams understand what data is available, where quality gaps exist, and which AI use cases warrant early investment. From there, deliberate choices about internal ownership versus augmented execution can dramatically accelerate progress.
Data readiness is not a prerequisite to AI adoption. It is the work itself. The opportunity window for AI advantage is real, but it will not remain open indefinitely. Organizations that move forward pragmatically—building foundations incrementally, augmenting where needed, and deploying iteratively—will be the ones best positioned to sustain AI-driven impact. The future of enterprise AI is being shaped by the data decisions made today.
Key Takeaways
- Enterprise AI fails on data maturity, not model capability.
- Data readiness and AI deployment should run in parallel, not in sequence.
- A four-stage maturity model maps the path from fragmented data to production-grade AI.
- Nearshore data pods can cut pipeline deployment timelines by 40–60% without ceding architectural control.
- Start with clarity on what data you have, not a pursuit of data perfection.




