

Modern software organizations move too quickly, and the blast radius of a single defect is too large, to leave quality to chance. Yet many teams still approach test-case design as an afterthought, a clerical exercise delegated to the last quiet hour before a sprint closes.
They document a few steps, attach a screenshot, and hope that automated pipelines will compensate for testing process gaps. The result is a familiar pattern: a release sails through software testing, continuous integration, looks healthy on staging, and then folds under real-world data. Hot-fixes follow, weekend calendars disappear, and executives question whether engineering can match its velocity goals with the reliability the business demands.
Never Create Test Cases to Check a Box
Treating test cases as executable specifications rather than disposable checklists changes that story. Good cases do more than uncover bugs; they clarify intent, preserve domain knowledge, and create a shared language between product, development, and software testing teams.
When the underlying design is rigorous, those test cases become a living safety net that travels with every code branch and every team hand-off. When test case design is vague or obsolete, the suite devolves into a false sense of security.
This article revisits core test case design techniques, but challenges each one to meet the realities of large, distributed programs: regulated markets, rapid iteration, and the need to prove compliance on demand.
The Strategic Nature of Test-Case Design
Let’s start with the basics of test case design. A single test case looks deceptively simple: prepare data, perform an action, compare the observed outcome to an expected result. That perception of simplicity is a problem.
Scale that idea across hundreds of services, multiple regulatory frameworks, and several time zones, and the simplicity evaporates. The traits that keep a test suite useful over time, such as traceability, repeatability, and maintainability, do not emerge by accident. They come from deliberate test case design decisions made early, then enforced through tooling and culture.
Leaders who view the test design process through this strategic lens talk about portfolio health rather than test counts.
They ask which business risks remain untested or which service domains suffer from flaky assertions. They invest in the suite with the same seriousness they reserve for production observability or build performance, because they understand that delivery speed and software quality are bound together.
Why Scale Exposes Weak Test Case Design
Small teams can survive a degree of informality in the testing process. Defects surface quickly, and communication overhead is low. Enterprises do not enjoy that luxury, and their test strategy has to reflect that.
Imagine a global payments platform that processes card authorizations in milliseconds. A single rounding error in the calculation service can ripple into tax, fraud, and reporting systems. If those integration points lack precise, automated verification, the next release may silently drop invalid transactions into production. Root-causing the financial discrepancy could take weeks, and the cascading cost of chargebacks, customer support, and brand damage would dwarf the effort that disciplined test-case design would have required up front.
Metrics expose the same truth from a different angle. Teams that invest in traceable suites report shorter detection times for critical regressions, fewer emergency patches, and dramatically lower audit preparation effort.
The Consortium for Information and Software Quality observed in its 2024 study that enterprises with thorough testing practices spent forty percent less on recovery work than peers who relied on exploratory testing or manual checks. Time saved on firefighting returns to roadmap delivery, a virtuous cycle that executives notice.
Four Principles That Survive Change
While textbooks list a dozen desirable test qualities, four prove essential under enterprise conditions.
Clarity comes first. A test is a communication artifact; a future maintainer must understand its purpose without hunting through stale documentation. Test designers have to use explicit data values, concrete post-conditions, and consistent naming conventions. “Reject purchase orders dated in the past with error PO_DATE_PAST” is self-explanatory. “Validate date logic” requires a meeting.
Completeness follows. Maximum coverage can never be guaranteed, but it can be systematic. Teams map features to risk and concentrate depth where the business cannot tolerate failure: payment settlement, personally identifiable information, or market-facing APIs. Lesser modules receive lighter treatment. The map evolves every quarter as features and regulations change, and the suite evolves with it, providing comprehensive test coverage continuously.
Traceability binds the artifacts together. Every test carries a hyperlink or unique identifier back to the user story, architectural decision record, or statutory clause it protects. Modern test-management platforms turn those links into real-time dashboards. When a regulation changes, quality leads pull a report to see which tests must be adjusted and which services require additional coverage.
Reusability keeps the maintenance budget manageable. Parameterized fixtures, shared setup steps, and modular assertions allow one logical case to validate dozens of scenarios across different test environments. The savings compound over thousands of test executions each month. More importantly, reusability shortens the onboarding curve for new team members: they extend existing patterns rather than inventing ad-hoc scripts.
Revisiting Classic Techniques for Modern Software
Foundational test case design techniques still work, but their execution must respect real delivery pipelines.
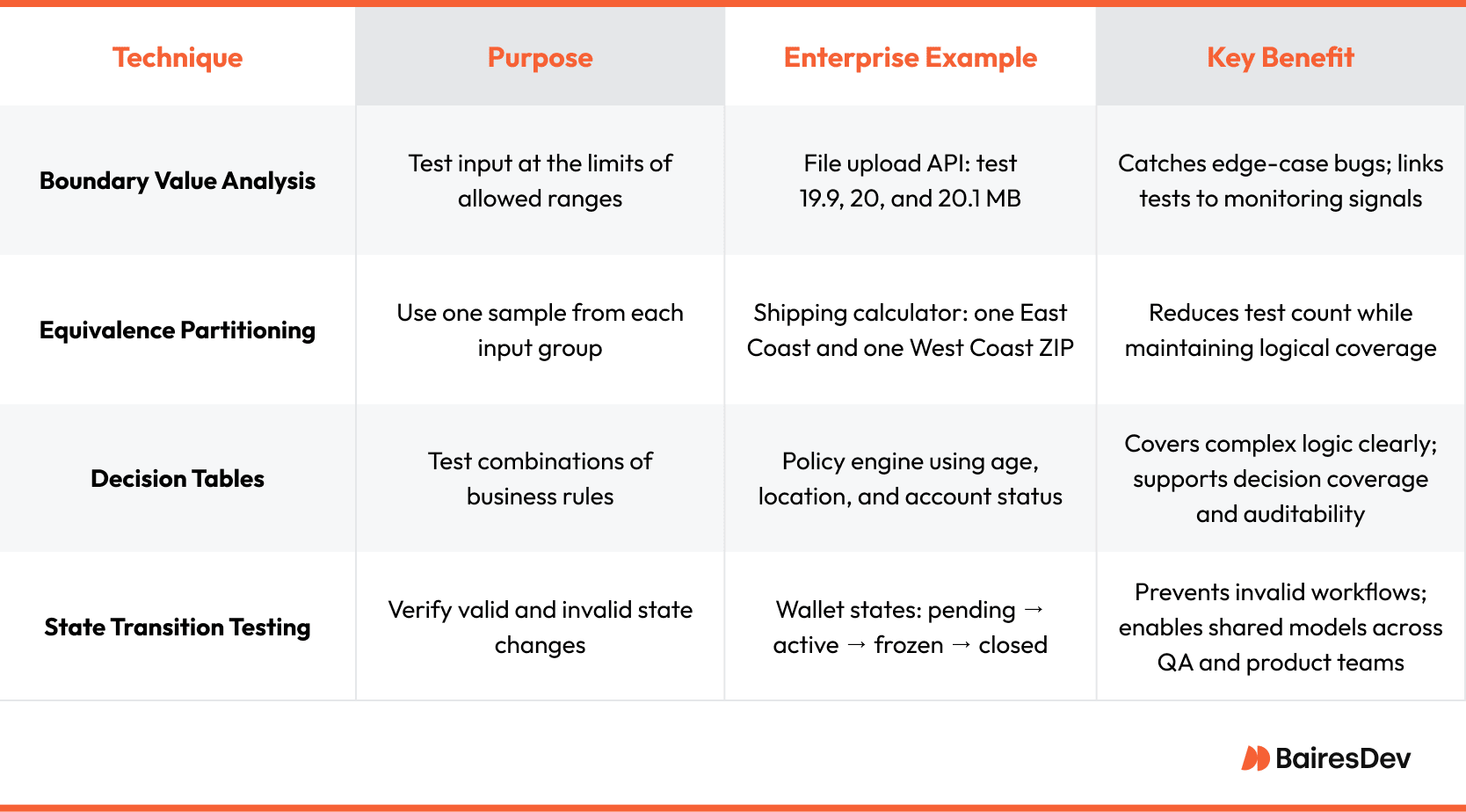
Boundary Value Analysis (BVA) remains the most efficient first line of defense. Failures often lurk where domains transition: zero versus one, maximum length versus maximum length minus one. In an enterprise API that accepts file uploads up to twenty megabytes, boundary tests target nineteen point nine, twenty, and twenty point one megabytes, then confirm not only the response code but also the observability signal that operations uses to detect abuse. Linking assertions to metrics ensures production monitoring extends the guardrail.
Equivalence Partitioning trades exhaustive enumeration for representative sampling. A shipping calculator that applies the same fee to every continental US ZIP code need not test all fifty states. One East Coast and one West Coast code demonstrate the rule, freeing cycles for higher-risk cases like military bases or overseas territories. The discipline lies in documenting assumptions so future maintainers know when the partition no longer holds.
Decision Tables tame rule complexity. Policy engines explode into combinations of age, location, account standing, and feature flags. Expressing the matrix as a table turns each row into a generated test and each failure into an explicit rule violation. When implemented thoroughly, test cases derived from decision tables can also contribute to achieving decision test coverage by ensuring that all logical branches in the underlying code are exercised during execution. If newrequirements add a column, quality engineers update the table and regenerate the suite instead of hand-coding edge paths. Auditors prefer this transparency; developers appreciate the single source of truth.
State Transition Testing safeguards workflows that depend on legally valid progressions. A wallet may start pending, become active, freeze under suspicion, and close on request. Modeling the states and transitions in a diagram, then generating tests from the model, highlights illegal moves quickly. Product managers can review the diagram without reading code, closing the communication gap before a defect ships.
White-box coverage metrics still provide value, yet only when filtered by business priority. Instrumenting every line of a data-transfer object delivers a flattering number but little risk reduction. Instrumenting the fraud-scoring algorithm matters, and the coverage dashboard should highlight that difference. Quality leaders who align instrumentation to risk avoid the trap of chasing one-hundred-percent vanity goals that inflate build times.
Toolchains That Turn Design into Enforcement
Well-written test cases stored in a wiki gather dust, while integrated cases shape behavior.
First, source control integration. Housing test definitions beside application code ties changes together. Pull requests that alter logic must update or add cases, or the merge fails. Engineers see red minutes after they break an invariant, not hours later on a staging server.
Second, continuous-integration orchestration. Pipelines trigger the suite on every commit or merge, using production-like containers. Parallel execution across node pools keeps feedback under ten minutes for typical services. Failures publish structured artifacts—logs, screen-shots, recordings—to a central dashboard so developers reproduce issues locally.
Third, analytics and reporting. Pass-fail counts alone hide flakiness and neglected partitions. Platforms such as TestRail, Zephyr, Xray, or custom Grafana boards surface execution time, stability trends, and requirement coverage. Compliance officers subscribe to weekly digests that flag any test tied to an unverified regulation, while managers track slow suites and allocate refactoring time during sprint planning.
The result is a virtuous telemetry loop: engineers manage test cases and learn which ones degrade, product owners see gaps before they become production incidents, and leadership links quality investments to velocity and customer satisfaction.
How Mature Teams Avoid Test Case Pitfalls
Exhaustive testing is difficult, and even experienced organizations can stumble when deadlines loom. Four traps appear most often.
Out-of-date fixtures drift from production reality and mask regressions. Mature teams schedule fixture refreshes each quarter or when a schema changes, and they generate synthetic personally-identifiable data to protect privacy.
Duplicate test cases creep in when squads work in parallel. A lightweight design review scans the repository for overlap and assigns ownership before test automation begins. Duplicates identified later are merged and parameterized.
Opaque results alienate executives. Quality leaders turn low-level metrics into risk narratives: “failed decision-table rows affect three percent of monthly revenue,” rather than “seven tests broke.” Visibility secures continued budget and headcount.
Missing ownership is the silent killer. When everyone owns the test suite, no one refactors it. Assigning a rotating domain steward creates accountability without locking knowledge to one individual. Stewards track decay, approve new patterns, and mentor incoming engineers.
An Incremental Adoption Road-map
Rewriting a neglected test suite on short notice sounds heroic, but usually fails. Successful transformations proceed in stages that align with the existing cadence.
- Inventory existing tests, map each to a requirement, and mark unlinked test cases for review.
- Refactor brittle or duplicate automated test scripts into parameterized, documented, traceable units.
- Automate high-risk areas first, gating merges with fast, deterministic checks.
- Instrument pipelines to capture coverage, flakiness, and execution cost, then publish trends.
- Evolve the suite with each feature, and never let it stagnate. New risks receive new cases; obsolete paths retire gracefully.
Even partial completion yields a return. Once ninety percent of customer-facing flows carry automated evidence, release windows expand, and hot-fix weekends decline. Finance notices fewer revenue leaks, compliance appreciates the faster audit responses, and engineering experiences a morale boost.
Conclusion
Test-case design, when practiced as an engineering discipline, underwrites delivery speed, regulatory confidence, and brand reputation. It transforms “did we test enough?” from a nervous guess into a quantifiable statement backed by living artifacts. The work is front-loaded. You invest in clarity, traceability, and reusability before the deadline hits. The payoff arrives every sprint thereafter.
Take an honest look at your test data and current testing process. Can a newly hired engineer trace a failing case to its requirement before lunch? Can your compliance officer prove coverage for each statutory rule without assembling a folder of screenshots? Can your product manager release a critical patch on Friday afternoon confident that test automation covered all edge conditions?
If not, start small. Refresh fixtures, link cases to stories, parameterize a brittle set, and build outward. Software quality at scale is not a moonshot, it is the cumulative result of many deliberate design choices. Make the next one today.
Frequently Asked Questions (FAQs)
What is the difference between black box and white box testing techniques?
Black box testing looks at what the system does from an end-user’s point of view. Testers feed in input data, observe the outputs, and never touch the source code. White box testing, on the other hand, examines how the software works internally. Engineers analyze branches, conditions, and logic paths to confirm that all routes through the code behave as expected. In practice, both approaches are essential. Black box tests verify functional behavior, while white box tests uncover hidden logic errors.
How do I decide which test design technique to apply?
Start with risk and visibility. If you’re testing externally visible behavior like API responses, user interface flows, or compliance-driven logic, black box methods such as boundary value analysis or decision tables are often the right fit. When you need to evaluate internal logic, like algorithm correctness or error handling under the hood, white box techniques are more appropriate. Team skills, tools, and timelines matter, but the core decision is based on where a defect would have the most impact.
Can I mix several testing techniques in the same project?
Yes. In fact, combining test design approaches is standard practice in enterprise QA. A single sprint might include decision table tests to cover rule combinations, data-driven testing to rotate input data and hit edge cases, and white box analysis to ensure critical code branches are exercised. This layered approach strengthens test coverage without wasting effort on redundant checks.
Why doesn’t anyone chase 100 percent test coverage?
Because it’s expensive and usually not worth it. Once the high-risk paths are covered, each additional test tends to catch fewer bugs while consuming more time in maintenance and execution. Many engineering leaders set realistic thresholds for comprehensive coverage, often around 75 to 85 percent for high-priority modules, and focus the remaining effort on exploratory testing, usability feedback, or performance validation.
How do teams generate effective test data for complex systems?
They use test data generators to automate the creation of structured, realistic input data. This allows QA teams to test broad input scenarios, including edge cases and invalid formats, without exposing real customer information. In a data-driven testing setup, a single test script can run dozens of times against different input sets, improving coverage while keeping test code clean. The goal is to simulate real-world behavior repeatably and safely.




