

Executive Summary:
This article discusses how reliability issues in enterprise systems are often organizational rather than technical. When team boundaries don’t align with failure domains, incidents turn into handoffs and shared capabilities fragment. Conway’s Law explains why architecture mirrors communication paths. Designing ownership and team structure intentionally allows leaders to make reliability and delivery reinforce each other instead of compete.
Conway’s Law is often treated as an interesting theory about organizational charts and architecture, but it’s also a practical tool for fixing reliability problems. It explains why incidents bounce between teams, why shared capabilities quietly fork, and why reliability work so often loses to roadmap pressure.
Put simply, Conway’s Law says systems end up shaped like the communication structures of the teams that build and run them. Architecture follows conversation: ownership boundaries, escalation paths, and incentives end up mattering as much as the diagrams.
I saw this pattern show up in an organization where two product teams each built their own version of user messaging and notifications. Both teams used solid tooling but optimized for different roadmaps. Fixes landed in one place, while similar defects resurfaced in the other.
When we tried to consolidate, we moved “ownership” of messaging to one team and had the other contribute changes. That’s when incidents started to bounce. Pages went to the owning team, but the breadcrumb trail often led elsewhere, turning routine mitigations into repeated routing that interrupted both roadmaps.
This isn’t a rare edge case. Across enterprise SaaS, reliability and delivery lag even with good tooling because ownership and communication don’t align with failure domains. Conway’s Law makes this visible: when architecture reflects how teams communicate and own work, org design becomes a lever that determines whether reliability is the default or a recurring negotiation.
Why Does Conway’s Law Matter for Reliability?
Conway’s Law matters for reliability because system resilience is directly constrained by the communication boundaries of the teams that build them. When these paths are misaligned, technical failures inevitably mirror org silos.
This becomes visible in how teams operate day to day. The way teams communicate, escalate, and make decisions shapes the system they build. Those paths become architectural boundaries, regardless of what diagrams say.
When teams are organized around products, coupling tends to become product-shaped even when the desired boundary is a domain boundary. Shared or ambiguous ownership produces shared or ambiguous operations. You feel this during incidents: triage turns into routing, pages bounce between teams, and fixes stall in another team’s backlog. Tooling can help, but it can also amplify existing incentives. Modernization stalls when every safe change requires cross-team negotiation.
One lever leaders control is ownership: make boundaries explicit, align on-call and escalation paths to those boundaries, and dedicate capacity to durable charters for shared capabilities. When those conditions exist, the intended architecture is easier to sustain without constant cross-team negotiation.
What Organizational Patterns Most Commonly Cause Reliability Failures?
Reliability failures most often arise when team boundaries are decoupled from system failure domains, leading to fragmented ownership and delayed recovery. These mismatches manifest in several recurring patterns across enterprise SaaS.
- First, product-aligned teams create product-shaped coupling even when domain boundaries are the goal.
- Second, a platform is most effective when one team owns the shared capability end-to-end, including on-call, and makes adoption easier than forking.
- Third, incidents tend to get shorter when the paged team can diagnose and fix without routing across teams.
The Case for Centralized Messaging
This example illustrates how an organizational change, not a technical one, can reverse reliability drift.
Two product teams were each doing their own implementation of messaging capabilities. The inflection point was organizational, not technical. We formed a small platform team external to both product teams and moved the messaging capability under that team’s ownership, including operations and on-call.
With a clear charter, the platform team could design once for both products, prevent drift, and iterate without sprint-by-sprint negotiation. Reliability improved because accountability was end-to-end. Over time, we expanded from email-only to SMS and chat integrations because we were no longer doing the work twice or fighting for parity across products.
Why Architecture Eventually Follows Communication and Ownership
Architecture eventually follows communication and ownership because day-to-day work naturally flows along backlogs and reporting lines, not static design diagrams. Over time, these social shortcuts reshape system perimeters.
Even when a system starts with well-defined service boundaries and contracts, everyday work gradually bends them toward whatever the organization makes easiest. When two teams need the same capability but operate with separate backlogs and incentives, the fastest path is often duplication, special cases, or informal reach-across changes.
Those shortcuts compound quietly into tighter coupling and unclear ownership. The impact usually appears later: slower incident diagnosis, longer time to recovery, and drawn-out negotiations to make routine changes safely.
In the notifications example, the initial duplication was easy to spot. However, the intermediate “reuse” attempts still encoded conflicting roadmaps and incentives. One team queued behind another’s backlog, and changes flowed through cross-team pull requests without full operational context.
On paper, the boundary looked shared. In practice, the operating model stayed ambiguous and incidents continued to bounce. The missing ingredient was not a pattern or a tool, but ownership aligned to the intended boundary.
Why This Matters for Operational Resilience
Operational resilience depends on stable team ownership for every failure domain to ensure rapid diagnosis and mitigation. When team structures do not align with these domains, incidents turn into routing exercises and recovery slows.
This operational work becomes harder when a failure domain does not map to a stable owning team. In those cases, incidents turn into routing work: pages bounce, context gets rebuilt, and postmortem actions fragment across backlogs.
When boundaries align with failure domains, the on-call team can diagnose and fix issues without cross-roadmap negotiation, and corrective actions are more likely to stick.
If the goal is reliability and predictable delivery, the practical question is which ownership and charter decisions make the right behavior the easiest behavior. The next section translates that question into a short list of org preconditions you can design for and observe in day-to-day system.
What Organizational Preconditions Are Required for Reliability?
Reliability depends on a small set of org preconditions, including clear ownership, teams aligned to failure domains, minimal handoffs, stable charters, and dedicated platform ownership.
At a baseline, those preconditions are structural rather than technical. Reliability is primarily determined by org structure rather than tooling choices. Tooling matters, but it is leverage, not a foundation. The foundation is whether the organization makes it easy to do the right thing by default. That means shipping small, reversible changes, restoring service without assembling a committee, and ensuring incidents lead to corrective changes that reduce recurrence.
In practice, reliability tends to improve when the following preconditions are in place:
- Clear ownership per service or domain, including on-call responsibility and authority to change it
- Teams aligned to failure domains, so incidents do not require a committee by default
- Minimal handoffs to ship changes and to mitigate incidents
- Stable, long-lived charters, allowing teams to own outcomes over quarters rather than sprints
- A real platform owner for shared capabilities, so adoption is easier than forking
Organizational Preconditions and Observable Signals
| Preconditions (What You Design) | Observable Signals (What You See Day to Day) |
| Clear ownership boundaries | Service or domain ownership is obvious to any engineer; on-call routes to the team that can diagnose and fix the failure; “Who owns this?” questions are rare |
| Teams aligned to failure domains | Incidents resolve with one team most of the time, without bouncing; postmortems have clear corrective owners; repeat incidents drop because postmortem actions ship |
| Minimal handoffs to ship and mitigate incidents | Routine changes do not stall on cross-team negotiation; the paged team can diagnose and fix without routing across teams; fixes do not queue behind another team’s backlog |
| Stable, long-lived charters | Teams own outcomes over quarters, not just deliverables; stable context reduces repeated relearning and routing; fewer tribal-knowledge outages |
| Platform ownership for shared capabilities | One team owns the shared capability end-to-end, including operations and on-call; adoption is easier than forking; shared capabilities do not fragment into “just for our product” variants |
Observable Impact
These preconditions translate directly into day-to-day operational signals.
When they are present, you tend to see:
- Incidents resolved by a single team most of the time, without bouncing
- Routine changes that do not stall on cross-team negotiation
- Fewer repeat incidents because postmortem actions actually ship
If these preconditions are so powerful, why do they remain uncommon? Because they often compete with near-term business pressure in ways that are easy to rationalize in the moment.
Why Reliability Often Loses to Short-Term Business Pressure
Reliability work often loses out because org incentives consistently prioritize and reward visible progress, like feature shipping, over the invisible prevention of system risk.
Most engineering leaders care deeply about reliability. The problem is not intent, but pressure. Product wants features, sales needs dates, finance expects predictability, and customers push for fixes. Every incentive is legitimate, but the organization is usually optimized to reward the most visible work. The result is a steady drumbeat of “just this once” exceptions.
Meanwhile, risk accumulates quietly. Releases become brittle, incidents grow harder to diagnose, and routine changes take longer as hidden complexity builds.
The Release Automation Trap
This example shows how visible delivery work can crowd out risk reduction, even when the consequences are well understood.
In one environment, multiple teams shipped within a shared monolith with essentially no automated regression coverage. As release trains grew, manual “release hardening” became the rational priority. Release weekends and post-release incident spikes became normal.
The trap was that hardening consumed the same capacity needed to reduce risk. Teams stayed busy preparing releases, but never created space to make releases safer.
The exit was organizational, not technical. We formed an automation tiger team with a narrow mission and a clear definition of done: automate release-critical workflows and remove the manual regression gate. Once that backlog was cleared, we dissolved the tiger team and returned its engineers to the product teams, but kept the operating model change. Automation coverage became part of the definition of done for new work and post-incident actions.
That is the Conway’s Law point. Releases became safe and repeatable by default, rather than a quarterly negotiation.
Why Organizational Design Is the Most Sustainable Path to Reliability
Org design is the most sustainable path because it embeds reliability into the delivery lifecycle, preventing it from being treated as optional “extra” work. By structuring teams around outcomes, leaders eliminate the constant need to justify maintenance over features.
When teams optimize for their own roadmaps, shipping the next feature feels urgent and visible, while improving release safety or incident repeatability feels important but deferrable. Over time, that gap turns reliability into something teams care about, but rarely have time to own.
Org design can turn deferrable work into owned work. Leaders can make reliability compatible with business pressure by doing three things consistently:
- Put end-to-end ownership where the failure domain lives. The team accountable for an outcome must also have the authority and capacity to improve it.
- Make quality and operational readiness part of normal delivery, not a special project. Definitions of done, on-call expectations, and incident follow-ups are operating mechanisms, not statements of intent.
- Use charters to protect cross-cutting work from being renegotiated every sprint. When a platform or enablement function exists, it should exist because the business expects it, funds it, and measures it.
When these pieces are in place, tradeoffs do not disappear, but they become explicit and repeatable. Reliability stops being the thing you do after the deadline. It becomes part of how you hit deadlines without paying for them twice.
The job is not to “care more” about reliability. It is to design the organization so reliability work is owned, routable, and hard to defer. The next section breaks down the org levers that make that possible.
How Organizational Design Balances Reliability and Delivery
Org design balances reliability and delivery by aligning ownership and on-call paths to minimize maintenance friction. This structural alignment converts the tradeoff between speed and stability into a managed tension rather than a constant firefight.
When reliability feels like it is constantly competing with delivery, the organization is forcing one-off decisions. Teams decide sprint by sprint whether reliability work gets done and who absorbs the cost. These choices change those negotiations into defaults by making the right behavior the easiest behavior.
The following three levers focus on ownership and charters rather than tools or process, and they work by reducing handoffs and ambiguity.
- Platform Team With an Explicit Charter
A platform team is not a shared repository or a set of recommendations. It is end-to-end ownership of a capability that multiple teams depend on, including operations and on-call. The charter should clearly state what the team owns, what it does not own, and what “good” looks like for adoption. The goal is to make the shared path easier than forking.
- Cross-Functional Initiative Teams for Modernization and Risk Reduction
Some work is important, time-bound, and difficult to accomplish through steady-state team backlogs. In those cases, form an initiative team with a narrow mission, a clear definition of done, and authority to change the systems involved. Stand the team up to remove a specific risk or bottleneck, then decide deliberately where the resulting capability should live long-term.
- Align Ownership and On-Call to Failure Domains
On-call is where paper ownership meets reality. If the paging path does not match the team that can diagnose and fix the failure, handoffs are encoded directly into incident response. Use incident history to identify recurring failure modes, then adjust ownership so one team can carry fixes end-to-end, ship mitigations safely, and follow through on postmortem actions. When the business expects durability, prefer long-lived domain teams over project-based staffing, because stable context and accountability reduce repeated relearning and routing.
These levers are intentionally general. They describe ownership and charter decisions that reduce handoffs and prevent shared capabilities from fragmenting over time. The next section provides a repeatable way to apply them to the places where the system is already hurting.
A Practical Framework for Improving Reliability Without a Re-Org
This framework provides a repeatable way to surface ownership and incentive misalignments and correct them incrementally, without starting with a re-org.
You do not need a re-org to begin. Apply the five steps below to a single failure domain to surface where ownership and incentives create friction, then make a small ownership or charter change and observe what improves.
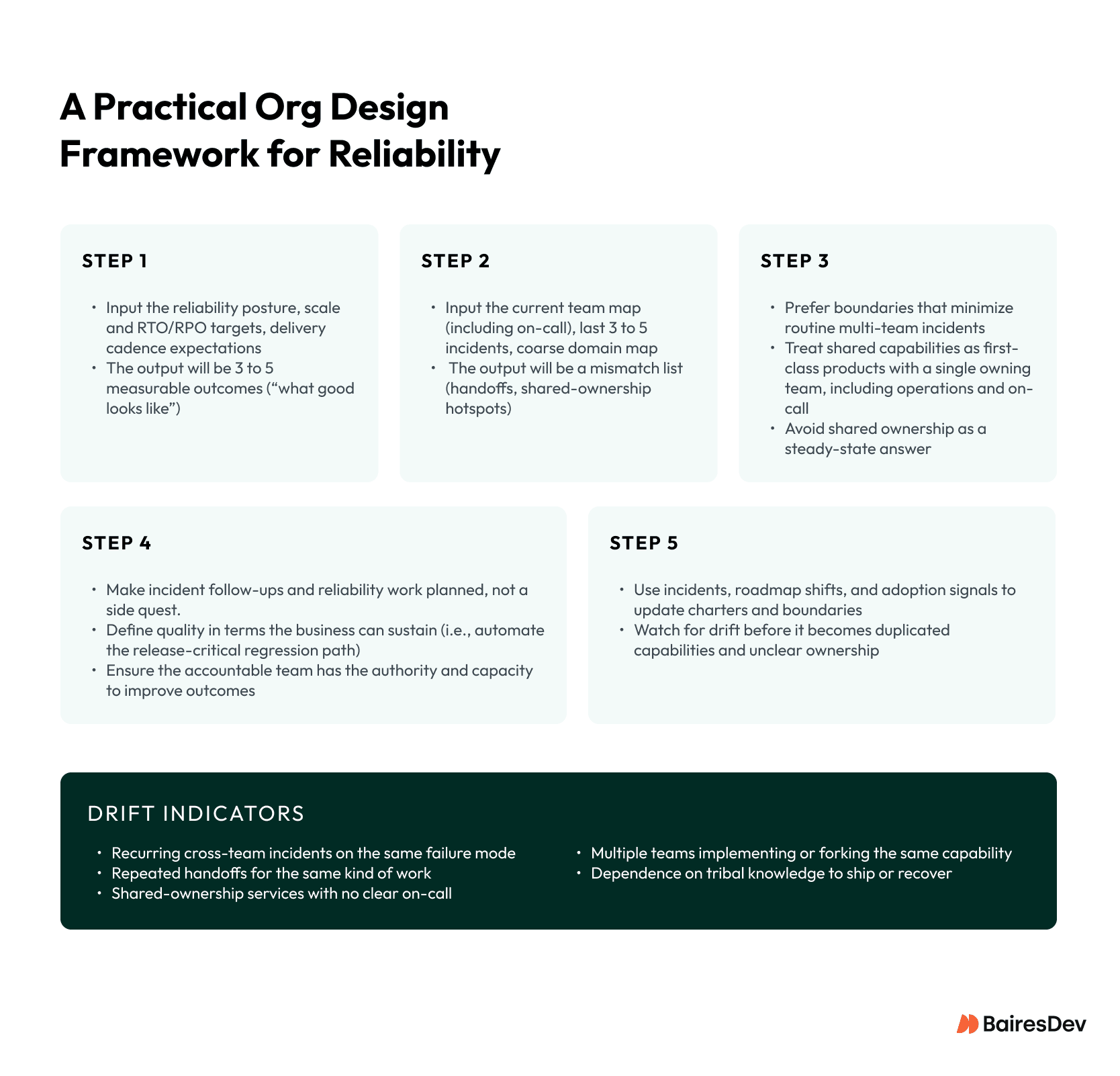
Step 1: Define Desired System Outcomes
Start with outcomes the business expects, including reliability posture and any Recovery Time Objective (RTO) or Recovery Point Objective (RPO) targets, stated in operational terms. If you cannot describe what “good” looks like, discussions about org structure will stay abstract.
Write down three to five measurable outcomes, for example:
- Most incidents are resolved by the first-responder team, without bouncing across teams.
- Every service lists an owner, an on-call rotation, and a runbook in the service catalog.
- Incident escalation follows a single documented path, without ad hoc “ask around” routing.
- Releases are small and reversible.
- Postmortem actions have an owner, a due date, and a clear deployment target, and most are closed on time.
Step 2: Map Communication Paths and Ownership Boundaries
Make the actual flow of work and incidents visible.
Use a current team map and on-call assignments, review the last three to five incidents (where pages went and how many handoffs occurred), and reference a coarse domain map. The output should be a short mismatch list: places where the same failure mode routinely crosses team boundaries, or where “ownership” and “ability to fix” are not held by the same team.
Step 3: Shape Team Topology
Adjust team boundaries so natural communication paths reinforce the architecture you want.
Choose boundaries that minimize routine multi-team incidents. Treat shared capabilities as first-class products with a single owning team, including operations and on-call. Avoid “shared ownership” as a steady-state solution.
Step 4: Align Incentives
Ensure operating mechanisms reinforce the org design rather than contradict it.
Make incident follow-ups and reliability work planned work, not a side quest. Define quality in terms the business can sustain, for example automating the release-critical regression path rather than attempting to automate everything. Ensure the team accountable for an outcome also has the authority and capacity to improve it.
Step 5: Iterate as the Architecture Evolves
Org design requires ongoing maintenance. Drift is not a moral failing. It is a signal.
Use incidents, roadmap shifts, and adoption signals to update charters and boundaries before a slow slide into duplicated capabilities and unclear ownership.
Drift Indicators to Watch
You can often see drift before it shows up as a major outage. Common signals include:
- Recurring cross-team incidents tied to the same failure mode
- Repeated handoffs for the same kind of work, especially during incidents
- Services with “shared ownership” but no clear on-call path
- Multiple teams implementing or forking the same capability
- Dependence on one or two people’s memory to ship changes or recover service
How to Apply This Without Boiling the Ocean
Apply the framework narrowly to one painful failure domain in 5 steps:
- Define outcomes for that domain, including what “better” should look like next quarter.
- Map handoffs from the last three to five incidents.
- Adjust ownership so one team can carry fixes end-to-end.
- Align incentives so reliability work is planned work.
- Re-check drift indicators after the next few incidents and releases.
Done this way, you start with one domain and repeat as needed, without beginning with a re-org.
Why Reliability Is Ultimately a Leadership and Org Design Decision
Reliability is ultimately a leadership and org design decision because leaders determine how ownership, incentives, and decision-making are structured long before incidents occur. It is often framed as a choice: you can ship fast or you can run stable, but not both. In practice, that tension is frequently a symptom of org design. When ownership is ambiguous and failure domains span multiple teams by default, you pay for delivery twice—once to ship, and again to route incidents, recover service, and relearn the same lessons.
The more useful shift is to treat Conway’s Law as a leadership tool rather than an inevitability. The structure of your organization shapes the structure of your system, and together they determine how quickly you can deliver change and how safely you can operate it. By applying the framework above to a single failure domain—mapping handoffs, aligning ownership, and watching for drift—you can make reliability the default instead of the exception. Make ownership obvious and align teams to failure domains. The architecture will follow.
Key Takeaways
- Reliability failures are often caused by organizational design, not technical limitations.
- When ownership does not align with failure domains, incidents turn into handoffs and slow recovery.
- Conway’s Law explains why communication paths shape system architecture over time.
- Platform ownership and stable charters reduce drift by making adoption easier than duplication.
- Sustainable reliability depends on clear ownership, aligned incentives, and long-lived teams mapped to failure domains.




