

Your dashboards are dark. Your finance team is complaining about a delayed filing, and your expensive machine learning models are failing because the incoming data is garbage. If your data pipeline is a single, fragile script, every change is a risk. Instead of being a competitive asset, it’s a single point of failure. And it’s brittle.
Data has become central to every business, and having a well-designed data process is no longer optional, even for smaller organizations. In today’s article, we examine modern data pipelines and discuss a battle-tested architecture that works: the Medallion model.
Given the inherent complexity of data pipelines, a sound architectural foundation is critical to maintain reliability and scalability. We will cover the different layers of a well-architected data pipeline, explain their roles, and discuss phased implementation.
Data Pipeline Architecture
Good architecture starts with the separation of concerns, which is the decomposition of data flow into distinct, manageable layers. This makes the pipeline manageable by delineating areas of responsibility with its own data contracts, SLAs, and team ownership.
For most use cases, we recommend the Medallion architecture, also known as the Bronze-Silver-Gold Architecture, which is one of the most commonly adopted architectures today. In this architecture, the pipeline is separated into three layers.
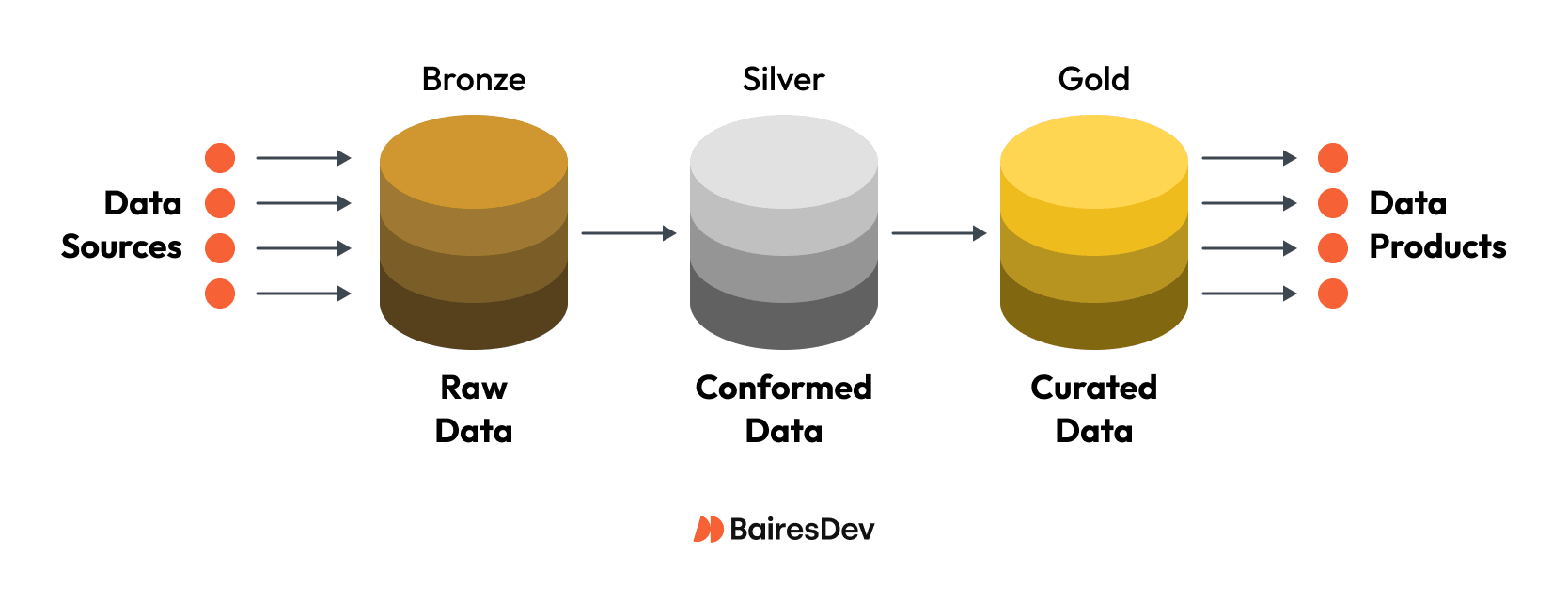
Bronze Layer
In the bronze layer, the focus is on data ingestion from source. Raw data is ingested from your operational systems, usually from multiple sources at once. This includes structured data, your SaaS tools, event logs, and your unstructured data like images, PDFs, or raw text. This data transfer can happen via batch processing (like a nightly dump) or by capturing streaming data from data streams or IoT sensor data. This layer typically stores data in data lakes (like S3 or ADLS).
The focus here is on fidelity to the original source data, capturing diverse data types in their native data formats. Relevant metadata such as ingestion timestamps, errors, or changes in data schema from the source are included too.
Data processing is minimal. This layer is built to handle high data volume.
In practice, the bronze layer often provides valuable auditability for the data pipeline, helping organizations triage data issues that may be otherwise difficult to identify. It’s your immutable log. It serves as a durable checkpoint, enabling historical data processing (reprocessing) even if the original source data is no longer available.
Silver Layer
In the silver layer, data is ingested from the bronze layer and processed for further analysis, its first significant data transformation and data processing.
At this stage, key data engineering operations like deduplication, standardization, and validation are performed on the data. It’s all about ensuring data quality and data integrity. The goal is to make data conform to the assumptions expected by downstream layers, and catch any issues that might cause costly errors.
The silver layer plays a crucial role in centralizing and enforcing data contracts across the data pipeline, saving valuable time and resources for the consumers of the processed data product.
Gold Layer
In the gold layer, which is often your data warehouse, data from the silver layer is turned into datasets that are ready for consumption by data analytics teams, business intelligence platforms, and machine learning and AI systems.
At this stage, a final data transformation is applied. Data is often aggregated, flattened, and structured based on requirements of each downstream consumer, building on top of the high-quality data produced by the silver layer. These models can be built to support everything from standard reporting to real-time analytics.
This is the layer that interfaces most directly with business consumers, and is the place where product management and data science often intersect.
| Bronze | Silver | Gold | |
| Purpose | Land raw data; enable audit/replay. | Conform and validate domain data under contracts. | Serve consumer-ready datasets for BI/ML/apps. |
| Data state | Immutable/raw with ingestion metadata. | Cleaned, deduped, versioned. | Aggregated/denormalized, optimized. |
| Transforms | Minimal. | Quality + conformance rules. | Business logic per use case. |
| Primary users | Platform/ops. | Domain data teams. | Analysts, product, data science. |
Complexity is Not Your Enemy
At first glance, the Medallion architecture may appear overly complex. Yes, it’s clearly more complex than a single giant script. But so is a microservices architecture. We use both for the same reasons: isolation of failure, scalability, and letting teams work independently.
As for the cost? This results in three copies of the data, but Bronze/Silver storage in a data lake is dirt cheap. Your engineers’ time spent firefighting bad data and your execs making decisions on garbage data is not.
In this case, complexity is not the enemy. There is a reason behind every part of this data architecture. In the next section, we explain the “why” of the Medallion Architecture.
Why Medallion Architecture?
To paraphrase Leo Tolstoy, all successful data pipelines are alike, all failed data pipelines fail in their own way.
Almost by definition, data pipelines have a large number of failure modes, and a set of principles and best practices have been developed to avoid the most common failure modes. Let’s look at some key principles, and how the Medallion Architecture addresses each of these.
Contract Before Code
Before writing any code or implementing any systems, it’s important to define explicit contracts that specify how upstream and downstream components will interact. This planning stage creates clear ownership and enforces scope discipline, which helps prevent confusion and redundant work at later stages.
In the Medallion Architecture, contracts and scope discipline is built into the design. Additionally, because interaction between each layer is defined by clear contracts, it is extremely difficult to have scope creep that significantly affects the performance of other layers.
Design for Replay and Chaos
Real-world data environments are inherently chaotic. APIs migrate, credentials expire, and vendors can even disappear overnight. A robust pipeline must have an effective checkpointing regime so that when failures happen, the team can quickly find workarounds or hotfixes and play back the pipeline for seamless continuation.
The Medallion Architecture is designed for failure management and replay. The bronze and silver layers serve as two key checkpoints from which the pipeline can be played back. Additionally, externally-driven failures are usually caught by these layers before making it to the gold layer, preventing failures from cascading.
Design for Change
Similar to the above principle, data requirements can often change quickly in an organization. Sometimes, this is internally driven – a new business unit might suddenly require a new data source to be added to the pipeline. Other times, the change is externally driven – a data vendor is no longer available, and the data previously provided by these vendors now need to be acquired from a new source.
These changes need to be managed with care to avoid introducing new problems to the pipeline. The Medallion Architecture makes change management easier, because the modularity and contract-driven nature of the pipeline allow code changes to be implemented in parallel. Additionally, the layered model allows for change to be tested and rolled out in phases, reducing risks of cascading failure.
Next, let’s look at the components of each layer and how to design them for maximum robustness and reliability. Notably, breaking layers down into smaller components further help with modularization, making the system more manageable.
Designing Each Layer
Each layer in the data pipeline has four common components that should be managed based on where they are within the architecture.
Data Ingestion System
First, we have the ingestion system, which is how data enters the layer. The bronze layer ingestion is the most complex, since it has to integrate with an external data source that is inherently unpredictable and uncontrollable. This often involves managing changing API specifications, expiring credentials, and shifting schema.
Comparatively, the silver layer is much simpler and is often a matter of coordinating with the data storage and service system developed by the bronze layer. However, silver layer ingestion can still encounter complexities due to the raw, unprocessed nature of the bronze layer data. The gold layer ingestion is the easiest of the three, since the data contract between the silver layer and the gold layer is often well specified and highly predictable.
Data Processing
Next, we have the processing system, where the data is transformed and operated on. By definition, the bronze layer will have very light processing. Often, bronze layer processing involves validation for pipeline-breaking errors and enrichment with ingestion metadata. In the silver layer, processing involves validating the data against an exhaustive list of requirements and assumptions, cleaning the data where appropriate, and enriching the data using a number of data engineering techniques.
The result is conformed, validated datasets that satisfy explicit data contracts and are usable by the gold layer. In the gold layer, the processing phase is where the data is transformed into a variety of datasets that are consumed by the end-user. Because it interacts with users who will have changing needs, the processing phase of the gold layer is likely to change frequently.
Storage and Serving
Then, we focus on the storage and serving system. Because each layer handles distinct outputs, their storage systems differ correspondingly. In the bronze layer, storage will often focus on volume, flexibility, and efficiency. Therefore, data is usually stored in a flat-file system like AWS S3 or Azure Blob Storage, along with a SQL database for holding metadata. In the silver layer, the output data is much cleaner, and will likely be slightly structured to help the gold layer.
Therefore, data is likely stored in a database of some kind, likely a SQL database or, should the situation require it, a NoSQL database. In the gold layer, the output system is driven by the needs of the end user. Some BI systems may work best with an SQL database, while some ML/AI systems might prefer file-based formats like parquet or HDF5.
Last but not least, we have the observability system, which monitors each stage of the process and flag issues as they arise. Unlike the other systems, observability is a single system that runs parallel to the three layers, rather than having a separate implementation for each one. An effective monitoring system plays a large role in catching problems in a timely manner, and should be built into each layer.
Now that we have a solid grasp of how to design each part of the architecture, let’s plan through a potential implementation of a data pipeline.
Data Pipeline Implementation
The success of any data system, in the final analysis, depends on the team that builds and maintains it.
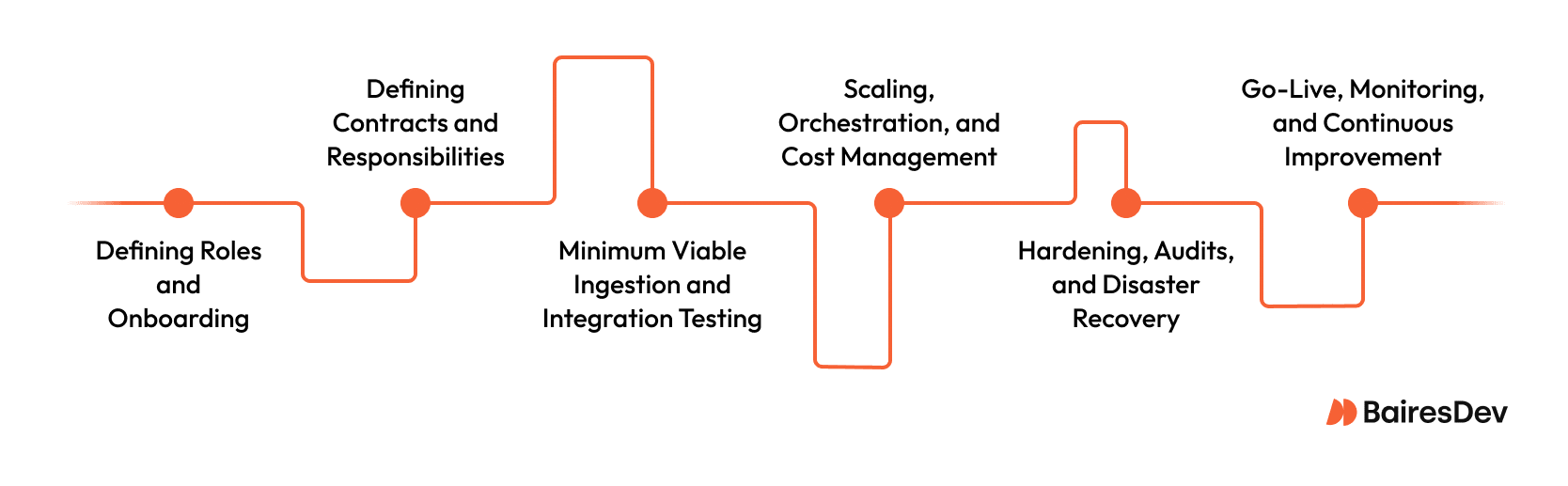
Step 1: Defining roles and onboarding.
The first step of any data pipeline project should be identifying a team with the appropriate skills needed to implement the various components of the project.
Typically, a pipeline project will need people with skills in data science, data engineering, database administration, devops, and system administration.
Step 2: defining contracts, responsibilities, and incident management.
Because the Medallion Architecture is contract-driven, the most important design step is the contract definition.
Before any code is written, the team should decide how the layers will interact with each other, and what assumptions can be made on the data that is handed off between the layers. This is where implementation details of each layer can also be discussed, since these details can influence the structure of the contracts.
Finally, make ownership explicit. Your contract must define who owns each dataset and what the incident response plan is. You don’t need a 100-page document, but you absolutely need to know who gets the alert when something goes wrong.
Step 3: Minimum Viable Ingestion and Integration Testing
Similar to a Minimum Viable Product, a minimum viable ingestion is a key stage in the development of a data pipeline. At this stage, the pipeline should ingest a small amount of data and process the data through all of the layers to ensure that handoff is going smoothly.
This is also when integration tests can be run, where increasingly troublesome data is introduced to the pipeline, and traced through the system to ensure that processing is happening as expected.
Step 4: Scaling, Orchestration, and Cost Management
Once the pipeline has been validated with limited datasets, it’s time to scale. Production-level volumes should be put through the system to ensure that the pipeline can handle throughput consistent with production.
At this stage, it’s also time to begin testing with live data, to ensure that the system can handle a typical workload that it would encounter in the wild. Orchestration tools may be introduced to help with monitoring and management, and costs should be tracked to ensure that the pipeline is performing efficiently.
Step 5: Hardening, Audits, and Disaster Recovery
There is another crucial step before the pipeline can go live. The pipeline should be audited and hardened to ensure security best practices are followed.
Are all of the data storage endpoints access-controlled? Is sensitive data appropriately encrypted and/or sanitized? Are there appropriate backups in case of loss or corruption? These are all questions that need to be asked before go-live.
Step 6: Go-Live, Monitoring, and Continuous Improvement
After the team is satisfied with the performance, management, and security of the data pipeline, it is finally time to go live. In the early stages of deployment, it is important to dedicate sufficient monitoring resources. The pipeline interacts with real-world data, so new monitoring systems will likely need to be created, and new alert thresholds will need to be tuned.
As the data and business needs evolve, various parts of the data pipeline will have to be changed to accommodate these changes. While the data pipeline needs continuous improvement, confidence in the pipeline will grow as the system matures, making the pipeline an indispensable asset.
From Blueprint to Asset
In this guide, we covered some key topics in data pipeline design and implementation. We examined the Medallion Architecture, its design details, and outlined why it is so popular.
As businesses embrace increasingly sophisticated data systems, it is important to keep in mind that a good pipeline is not a one-time investment, but an ongoing commitment to best practices. So, that’s the Medallion Architecture. We’ve covered the design and the ‘why.’
It’s popular among data engineers for one simple reason: it’s a resilient blueprint that solves the most common data pipeline failures. It’s a good model, as long as your team can execute it well.




