

A mid-sized fintech spent nine months and $400K training a custom model on internal documentation. Six weeks after launch, the team quietly switched back to GPT-4 with RAG. The trained model couldn’t keep up with policy changes, hallucinated on edge cases, and required constant retraining. The problem wasn’t the model, but the decision to train in the first place.
Your GenAI roadmap is slipping and the ask from leadership is simple: train LLM on your own data and make it smarter on our domain. The fastest way to say yes is to promise training. The fastest way to regret it is to start before you know what problem you’re solving or which training data should drive the outcome.
Engineering leaders are no longer deciding whether to use AI. They’re deciding where to take risk and where to buy time. That’s the real question behind training on your own data, and it’s rarely binary.
This guide frames the options as a spectrum and shows how to choose the lowest regret path for your team.
The Spectrum of Options
Most conversations about training large language models skip a level. There’s a wide gap between using a strong model with careful prompting and running a full training pipeline. When those differences blur, teams buy complexity without delivering the performance they need.
Below are four distinct paths, each with its own data and operational footprint. Treat them as operating models.
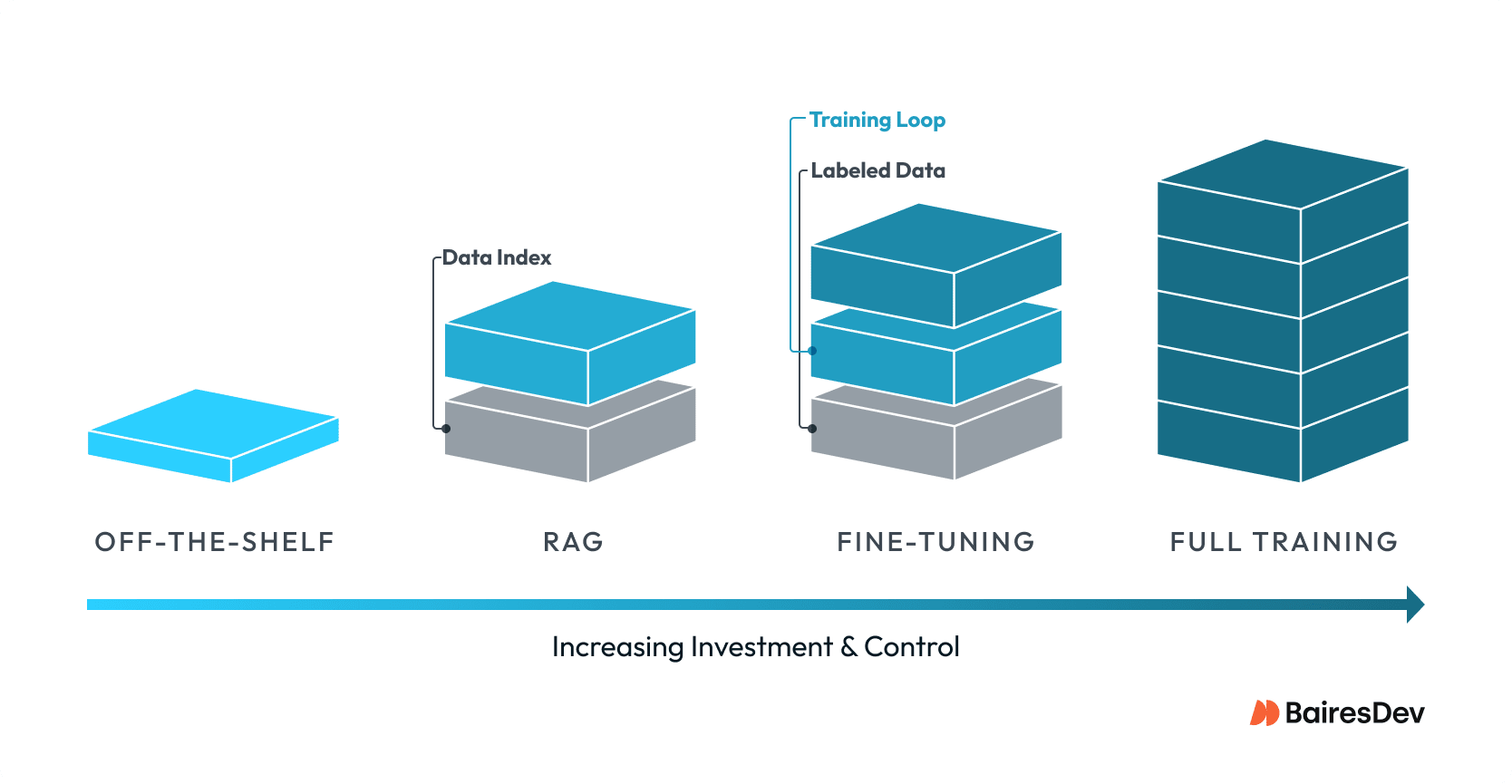
Off The Shelf Models With Strong Prompting
This path assumes you’re using a leading base model and investing in prompt design, tool calling, and workflow orchestration. You’re not changing the model. You’re improving how it’s used. Pre-trained LLMs offer the fastest route to value and the safest place to learn what your users actually need.
It’s also where many teams stop. If the system can handle the task with good prompts and clear guardrails, the rest of the stack stays simple. You avoid training costs and keep your team focused on product delivery.
Retrieval Augmented Generation Over Proprietary Data
RAG adds your data at query time. The model stays the same, but it’s grounded on your documents and records through retrieval. If your domain changes often, or if answers must cite specific policies or tickets, RAG delivers the freshness and traceability that training alone cannot.
A strong RAG system needs more than a vector database. It needs specific data contracts, chunking strategy, access controls, and evaluation. Done well, it can outperform fine-tuning for knowledge-heavy tasks while staying transparent about sources. Teams often start with RAG because it balances control with speed.
Parameter Efficient Fine-Tuning For Targeted Tasks
Fine-tuning changes the model so it behaves differently, usually for specific tasks. It’s useful when you need a consistent output format, stable behavior under specific constraints, or improved performance on a tightly defined workflow (e.g., classification, summarization, or routing).
This is where teams start to get into trouble by overreaching. Fine-tuning doesn’t replace access to fresh data. It doesn’t turn a general model into a domain expert on its own. It’s a precision tool for fine-grained control, and it works best when paired with RAG or when your task is stable and well-bounded.
Full Training Or Continued Pre-training
Full training or continued pre-training is the rarest approach. It assumes (very) large datasets, a serious GPU budget, and a team that can own the model lifecycle and choose model architecture. The upside is deep customization and long-term control. The cost is multi-dimensional. You take on model performance risk and the burden of keeping the model current. Overhead becomes an issue as top AI talent and specialized hardware don’t come cheap, and can be difficult to source even with generous budgets.
For most mid-market enterprises, this isn’t a near-term option. It can be the right move for companies with massive proprietary corpora and a business model that depends on model control. For everyone else, it’s a strategic horizon item, not a default plan when deciding whether to train an LLM.
Data readiness is the gate that determines which of these paths you can actually execute. It’s also the place where most projects silently fail.
Data Readiness Is The Gate
Training on your own data isn’t about volume alone. It’s about quality, coverage, and governance. If your data is inconsistent, duplicated, or not aligned with the tasks you care about, training will amplify the wrong patterns. High-quality data is what separates successful projects from failed experiments.
The good news is that readiness can be measured. Treat it as a product quality problem, not a research experiment.
Data Quality And Coverage Checklist
A practical checklist to decide if your data is ready for RAG or fine-tuning. If you can’t check most of these, your first investment should be data work, not model work. Building a custom dataset requires this foundation.
Coverage maps to the target task and key edge cases. Relevant data is cleaned, deduplicated, and well-structured. PII and sensitive fields are identified and handled. Ground truth or labels exist for evaluation. Data access and lineage are auditable.
Use this as a gating review before any training budget is approved. It saves more time than any model tweak ever will.
Labeling And Feedback As A Product
Data labeling isn’t a one-time sprint. It’s a feedback system that must evolve with the product. You need a steady flow of high-quality labels and human judgments to tune and evaluate your model. The labeling process, when done well, becomes a strategic asset. Without that, you can’t prove improvement or diagnose regressions.
Teams that succeed treat labeling as part of the product roadmap. They invest in data annotation tooling, clear rubrics, and a feedback loop that captures real user outcomes and preferences. Even for RAG, human feedback is how you improve retrieval quality and ranking over time.
Governance And Risk Controls
Once data touches a training or retrieval pipeline, it becomes a security and compliance issue. The requirements here aren’t exotic. They’re the same controls you expect for any system that handles sensitive data. You need access controls, retention policies, redaction for PII, and audit trails.
Regulatory guidance from bodies like NIST and regional data protection rules should shape your internal policy. The operational question is whether you can enforce those rules at scale, not whether the model is powerful enough.
Think of governance like version control for code. You wouldn’t deploy to production without knowing what changed, who approved it, and how to roll back. The same discipline applies here. Every dataset needs an owner, every change needs a log, and every access pattern needs monitoring. This applies whether you’re managing a single dataset or multiple datasets across different projects.
Good data governance is the foundation that lets you move fast without breaking compliance or leaking sensitive information. Teams that skip this step can end up paralyzed by audit requests or forced to shut down production systems when regulators ask questions.
Decision Framework For Choosing The Path
Leaders need a simple framework that respects technical reality. The decision should map to problem type, latency and control needs, and the cost of building and operating the system. LLM training is expensive, and understanding which path to take requires clarity and a good understanding of the training process.
Use the table below as an executive lens. It doesn’t replace detailed architecture work, but it prevents the most common missteps.
Comparison Table For Executive Decisions
Off-the-shelf, RAG, fine-tuning, and full training differ across six axes that matter for delivery and risk.
| Path | Data Requirements | Compute | Cost Profile | Risk Profile | Control And Consistency |
| Off The Shelf | None | Provider managed | $0.50-$5 per 1M tokens | Low technical risk, vendor dependency | Limited to prompt design |
| RAG | Clean, indexed proprietary data | Light (vector DB, retrieval) | $5K-$50K initial setup, $500-$5K monthly | Moderate (data quality, retrieval gaps) | High traceability, fresh data |
| Fine Tuning | Labeled task specific dataset | Moderate (single GPU to small cluster) | $10K-$100K per training run | Moderate (overfitting, drift) | High consistency for narrow tasks |
| Full Training | Massive proprietary corpus | Heavy (multi-GPU clusters, significant computing power) | $500K-$5M initial, $50K-$500K monthly | High (model quality, ops burden) | Full control, high maintenance |
A table is only useful if it influences behavior. Three signals tend to determine the right path faster than any long debate.
Decision Signals That Matter Most
First, ask whether the task needs fresh data or just consistent behavior. Fresh data points toward RAG. Consistent behavior for a narrow task points toward fine-tuning. The fine-tuning process is most valuable when your requirements are stable and well defined.
Second, ask whether the value is in the answer or in the process. If the answer must be auditable or tied to a specific record, RAG is often the lowest risk option. If the process is about consistent format or tone, fine-tuning can help.
Third, ask how much operational load you can sustain. If you don’t have a team that can run training pipelines, manage a training environment, and handle evaluation cycles, full training isn’t realistic. That’s a staffing decision.
Recommendation Matrix For This Year
A simple matrix can guide the first year of work without pretending to lock in the future.
| Data readiness | Task profile | Recommended path this year | Notes |
| Strong | Narrow, well-defined | Targeted fine-tuning plus RAG as the default grounding layer | Use instruction tuning on specific workflows |
| Strong | Broad, knowledge-heavy | Invest in RAG and retrieval quality before any fine-tuning | Focus on coverage, ranking, and permissions |
| Limited | High product demand | Off-the-shelf models with strict guardrails and a data improvement roadmap | Use this to learn and clean data in parallel |
| Exceptional proprietary corpus | Long-term strategic need | Evaluate continued pre-training / full training with dedicated research + platform track | Only if you can own lifecycle and compute |
In practice, most teams fall into four buckets. If your data is strong and the task narrow, targeted fine-tuning on top of RAG makes sense. With strong data and broad knowledge needs, invest in RAG and retrieval quality first. When data is weak but demand is high, stick to off-the-shelf models with guardrails and a data-improvement roadmap.
Only if you have an exceptional proprietary corpus and a strategic need for deep control does continued pre-training belong on this year’s plan.
Operating Model Without A Research Lab
Most enterprise teams don’t need a research org. They need a delivery model that can ship, measure, and improve safely. That means clear roles, realistic tooling, and a tight evaluation loop.
Roles And Responsibilities
A practical model separates three functions. Data engineering owns data pipelines, quality, and access control. MLOps owns deployment, monitoring, training setup, and model lifecycle tooling. ML specialists focus on model selection, training design, and evaluation methodology.
Nearshore teams can add leverage here by owning pipeline work, evaluation harnesses, and integration into product systems. The core team should keep control of model policy, security requirements, and success metrics. That division protects risk while keeping velocity.
Tooling And Evaluation Harness
Successful teams treat evaluation as a first-class system. They define task-specific test sets, track regression, and monitor real-world scenarios to understand how the model performs in production. Tools in the Hugging Face ecosystem, along with evaluation frameworks like OpenAI Evals, make this practical without a heavy custom build.
The point isn’t the tooling itself. The point is to measure whether the system is improving the business outcome you care about. If you can’t measure the model’s performance against clear metrics, you can’t justify training.
Risk Management And Change Control
Any AI system in production needs change control. That includes versioning of prompts and retrieval indexes, canary releases for model updates, and clear incident response when outputs fail. These are familiar practices to platform teams, but they need to be explicitly scoped for AI behavior.
Risk management also includes model fallback. If retrieval fails or the model produces unsafe output, the system should degrade gracefully. That design work is as important as any training step.
The fastest way to validate this operating model is to ship a small pilot with clear metrics. That’s the most reliable way to earn the next investment.
Pilot Playbook For A First Use Case
A strong pilot is narrow, valuable, and measurable. It should solve a real operational pain point and be small enough to ship in weeks, not quarters. A support assistant that answers tier one questions or an internal knowledge bot for technical documentation are good examples.
Pilot scope should include a fixed dataset, a limited set of workflows, and an evaluation plan with clear success metrics. If the pilot succeeds, you’ve earned the right to expand. If it fails, you’ve learned where the data or process is weak without burning a large budget.
This is also where a nearshore team can be most effective. They can build ingestion and retrieval pipelines, set up evaluation harnesses, and integrate the pilot into existing tools while your core team focuses on policy and adoption.
Making The Call
Training on your own data isn’t a badge of maturity. It’s an operating choice on a spectrum. For most organizations, the low regret path is to start with strong prompting and RAG, then add fine-tuning only when a stable task and solid data justify it. Training LLMs from scratch should be the last resort, not the first move.
The question isn’t whether you’ll eventually train a model. The question is whether you’ll do it for the right reasons at the right time. Start with the simplest path that solves the problem. Prove value with off-the-shelf tools and good data practices. Earn the complexity before you buy it.
The best next step is to run a narrow pilot with a clear metric and a realistic operating model. If it works, scale the data and the process before you scale the model. That’s how you build leverage without building a research lab.




