

A large language model (LLM) is a generative AI system built on deep learning and transformer architecture. At its core, it tries to predict the next token in a stream of text. Tokens are small units of language like a full word, part of a word, punctuation, or a symbol. By repeating this single prediction step thousands of times, an LLM produces text that looks deliberate, even though each step is just a statistical guess.
For an engineering leader, the real issue isn’t fluency but behavior. So, it’s easiest to understand LLMs as a statistical model for text generation, trained on massive volumes of language data. It doesn’t store facts the way a database does. It also doesn’t reason symbolically or learn rules. Instead, it generates human like text based on its training data and the context you supply. That’s why it’s a serious mistake to treat it like a deterministic system component.
In practice, LLMs do best when the most plausible language is also useful. They struggle when they have to be correct. They struggle even more when determinism or compliance is non-negotiable. This is not a subtle tradeoff. It is the whole picture.
How LLMs Are Trained
Training explains why these AI systems feel powerful and why they sometimes fail in uncomfortable ways. The math behind neural networks is heavy, but the pipeline is simple enough to matter for architectural decisions and risk assessment.
Most modern large language models trained today pass through two main stages:
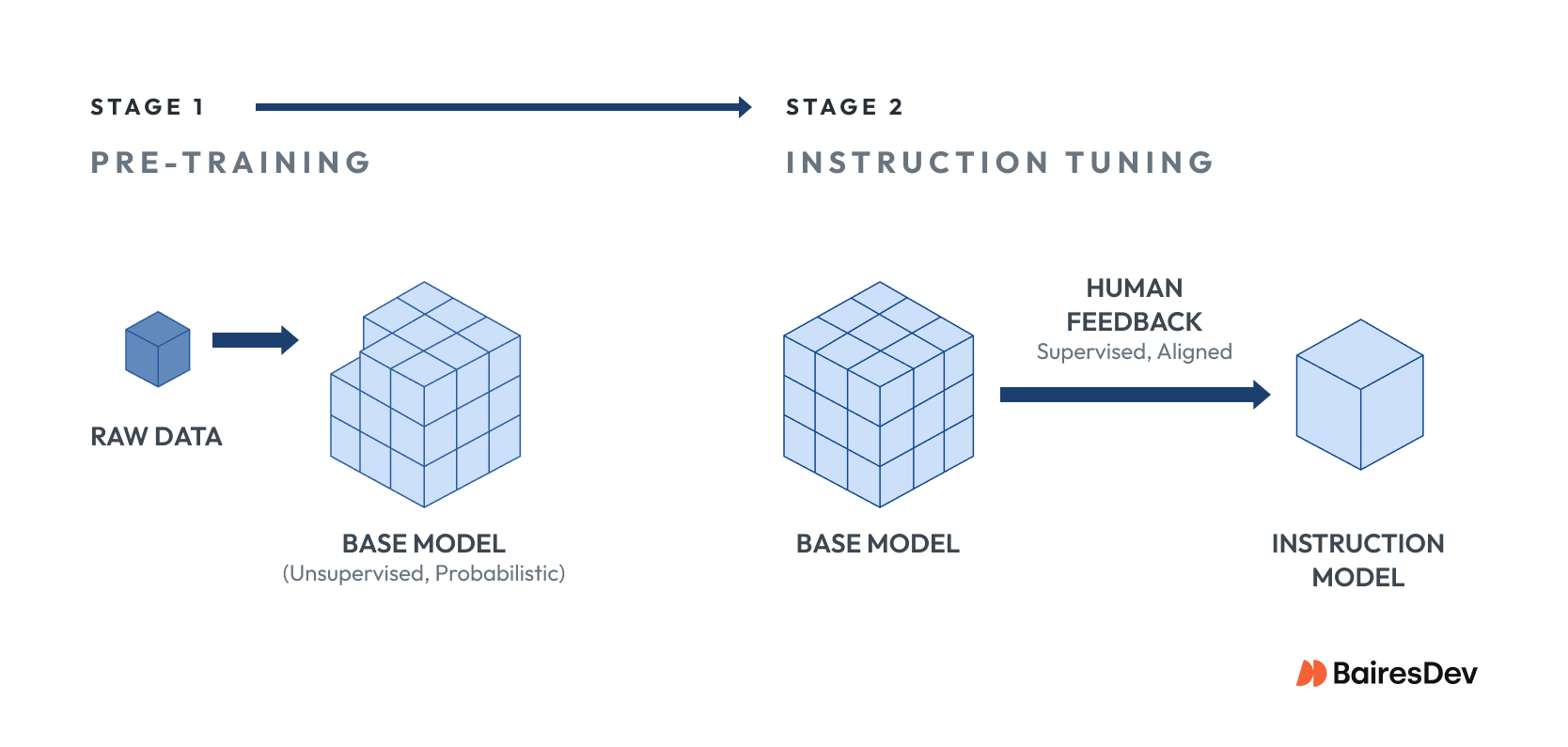
Stage 1
First, the model is pre-trained on enormous collections of textual data. This phase teaches the system how human language works in the wild. It learns structure and patterns. It absorbs broad world knowledge, along with all the noise and bias that come with it.
Stage 2
Second, many models are adjusted through instruction tuning and human feedback. This step shapes how the model responds. It nudges outputs toward being more helpful and polite, and less dangerous. It does not turn the model into a rules engine or a source of truth.
Implications
From a leadership perspective, several implications follow.
- Pre-training data is broad and messy. This is why models can sound confident while being very wrong.
- Fine-tuning improves task-level behavior but does not change the underlying probabilistic nature of the system.
- Human feedback aligns outputs toward usefulness and safety, but it does not guarantee correctness under pressure.
This is why LLMs feel flexible yet unpredictable, like running a distributed system with no guardrails and hoping your retries save you when traffic spikes. Anyone who’s done a late night PagerDuty alert knows how that movie ends.
If you approach LLMs the way you approach a database or a rules engine, you are setting your team up for pain, because these systems behave less like a spec-compliant API and more like a junior engineer who has read every design doc on GitHub and skimmed The Phoenix Project. Maybe they can talk a good game, but they still need supervision before you let them anywhere near production. This is why saying “the model will figure it out” is hand-wavy nonsense that experienced engineering leaders reject outright.
Tokens, Parameters, and Model Size
When evaluating LLM capabilities or vendor claims, three concepts show up constantly: tokens, parameters, and context windows. These are not academic trivia. They’re the knobs that control cost, latency, and operational risk. The engineering leader who ignores them does so at their peril.
Tokens are the units the model reads and emits. A token might be a full word. It might be a fragment. It might be punctuation.
Parameters are the internal weights learned during training that encode language patterns and relationships. More parameters usually mean better language quality and broader task coverage, but they also mean higher inference cost and slower responses. Bigger is not automatically better. That assumption is lazy.
Context windows define how much text the model can consider at one time. This matters more than most vendor decks will lead you to believe. A small context window forces chunking. Chunking introduces glue code. Glue code introduces bugs. A large context window simplifies integration, but it raises cost and increases the blast radius when the model fails. Pick your poison.
For engineering leaders, these variables are levers. You pull one and something else moves. That trade space should feel familiar, like tuning memory and network limits in a distributed system where every shortcut eventually shows up in production.
What LLMs Are Good at Today
LLMs excel when the job is to transform language, like in language translation or summarizing. They don’t do as well when they’re asked for a single correct answer. (They can mimic complex patterns, but they can’t interpret human language.) This distinction is everything. Miss it, and you’ll deploy these systems in places where they don’t belong.
High-value use cases tend to cluster around a few patterns:
- Summarizing long documents, support tickets, or meeting transcripts where perfect fidelity is not required.
- Drafting or rewriting content to match a specific tone, format, or audience.
- Powering natural language processing tasks on top of structured systems like search, analytics, or reporting.
- Offering code suggestions in different programming languages or draft documentation that a human will review.
- Answering internal questions over company knowledge bases when paired with retrieval.
In these scenarios, small mistakes are acceptable and expected. Humans catch them. The productivity gains usually dwarf the residual risk, especially when outputs are clearly framed as assistive and not authoritative.
Using LLMs for language-heavy work is smart. Using them as arbiters of truth is asking for trouble of the worst kind.
They’re great accelerators, but they make terrible judges. So, treat them like a fast-moving conveyor belt in a factory line. They work at impressive speeds, but if you remove the human inspection step, you’ll ship defects.
Core Limitations Engineering Leaders Must Plan For
Every LLM deployment must account for limitations inherent in the technology, not vendor-specific shortcomings. Ignoring these leads to brittle systems.
Hallucinations get the most attention, and for good reason. Because the model predicts what text is likely to come next, it will invent details when it finds gaps in the prompt or the retrieved data. Better prompts help. Guardrails help. None of them eliminates the problem. Anyone selling that story is selling something.
Non-determinism is harder to explain to stakeholders, but just as painful in practice. The same input can yield different outputs, especially when sampling settings are tuned for creativity or speed. That variability complicates testing and debugging.
Context window limits force real architectural choices. Long documents must be chopped up. Conversations must be summarized. External data must be retrieved on demand. Each step adds logic, and each layer adds a new way for things to break. Sadly, those failures rarely show up in happy-path demos.
How Large Language Models Work in Modern Architectures
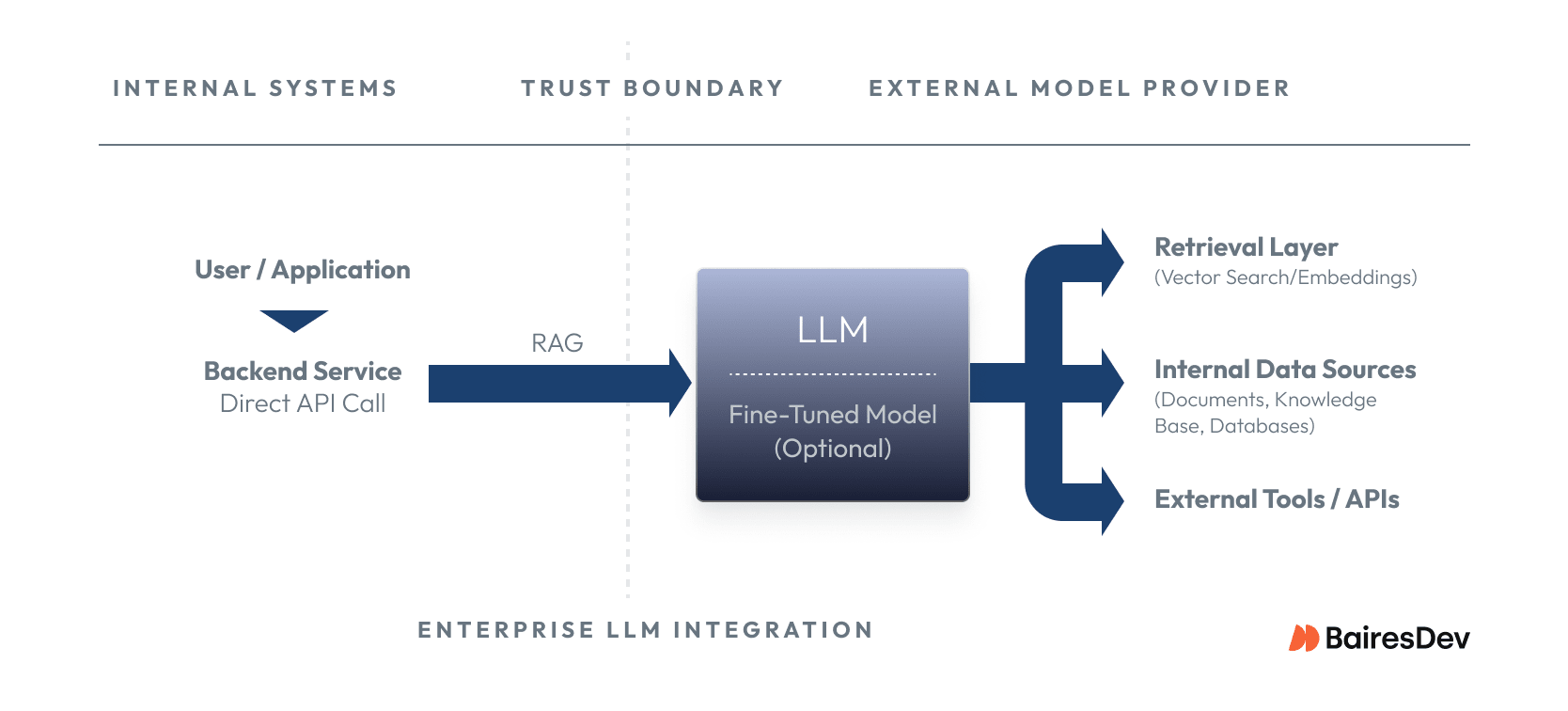
In real organizations, LLMs are almost never standalone systems. They’re embedded in products and internal workflows, and the integration pattern you choose does more to shape risk than the model brand itself.
The simplest pattern is a direct API call: send a prompt, get text back. But most production systems have moved past single-shot prompting. Modern integrations increasingly use agentic patterns, where the model orchestrates multi-step workflows, querying databases, searching documents, calling external tools, and verifying its own outputs before returning a result. You’re no longer managing a stateless call. You’re managing a workflow with branching logic, tool permissions, and failure modes at every step.
Retrieval augmented generation grounds model responses in real data. The system pulls relevant documents from internal sources and injects them into the prompt, improving relevance without retraining. This works, but it shifts complexity into retrieval quality, indexing, and permissions.
Not every task needs a large model. Teams are increasingly deploying small language models (SLMs) for narrow jobs like classification or routing. They’re cheaper, faster, and easier to keep on rails because their scope is deliberately limited.
In practice, production systems layer these patterns. An agent might use retrieval to ground its responses, hand off a subtask to an SLM, and run a verification pass before surfacing results. Leaders should think less about picking the “right” pattern and more about how these pieces interact under load.
Build Versus Buy Decisions for LLM Capability
One of the most common leadership questions is whether to rely on external APIs or self-hosted models. There is no universal answer, but the tradeoffs are clearer than they look at first. Teams that pretend otherwise end up arguing ideology instead of shipping software.
Managed APIs offer rapid iteration and solid baseline model performance. They fit experimentation and internal tools. If you need to prove value quickly, this is the shortest path. Insisting on full ownership at day one is a purity test that slows teams down for no good reason.
Self-hosted or open source models offer real control. You decide where data lives and how requests flow. This makes sense when regulatory pressure or deep platform integration outweigh convenience, but it also demands operational maturity that many teams overestimate. Be honest.
Key evaluation criteria usually come down to a small set of factors:
- Data sensitivity and retention requirements
- Expected request volume and cost at scale
- Latency tolerance for user-facing features
- Internal expertise available to operate ML infrastructure
Nearshore engineering teams often add value here by handling the unglamorous parts. The plumbing. The glue. They integrate models into existing platforms, build retrieval pipelines, and operate the surrounding systems. For most enterprises, that’s more impactful than trying to build an in-house research group, because the hard problems look less like novel AI and more like sustained platform work.
Using LLMs With Proprietary Data Responsibly
Tech leaders invariably ask if they should train an LLM on their own data. In most cases, the answer is no. At least not yet. Fine-tuning is often misunderstood as a way to make models factual or authoritative, and that misunderstanding drives risky decisions.
Fine-tuning changes how a model responds. It doesn’t change what the model knows. It works best for formatting or narrow task behavior. Retrieval is different. Retrieval lets the system reference current, auditable data sources at runtime. This is exactly why it matters so much in regulated environments.
A practical rule of thumb:
- Use retrieval when correctness and traceability matter
- Use fine-tuning when consistency of style or task execution matters
- Avoid full model training unless there is a clear research or scale-driven reason
Cost and Operational Trade-Offs
LLMs introduce different operational concerns than traditional services. Leaders need to think past per-request pricing and consider system-wide effects that only show up under load.
Model size improves response quality, but it raises infrastructure cost. Context length drives token usage, which also impacts spend. Throughput limits can choke peak traffic unless you plan for them early and test them once you have them.
Operationally, teams must plan to monitor output quality and handle prompt injection. Unlike deterministic services, success metrics are often qualitative and require human review loops. Pretending this behaves like a normal backend dependency is incredibly naïve.
Engineering leadership should treat LLM integrations as evolving systems, not static APIs, because the cost curve expands and contracts like an accordion as usage patterns change. Nickel-and-diming model calls without a holistic view is how budgets blow up while dashboards look fine.
Sensible Use Cases Versus High-Risk Deployments
Not every workflow benefits from LLM integration. Knowing where not to use the technology is part of competent leadership, not a lack of ambition.
Lower risk, high return use cases are:
- Internal copilots
- Support drafting tools
- Exploratory data analysis.
Higher risk scenarios include:
- Autonomous decision making
- External compliance communication
- Systems that trigger irreversible actions.
In these cases, strong guardrails and human approval steps are essential, and assuming you can “just monitor it in production” is the kind of thinking that MythBusters spent years disproving. A useful mental model is to ask whether an incorrect output would cause inconvenience or harm, because when harm is plausible, the system needs more controls. If you don’t have time to build them, the use case should wait.
LLM Capability vs Risk Matrix
| Use case | LLM suitability | Primary risks | Required guardrails |
| Internal copilot (engineering, ops, support) | High | Incorrect or incomplete answers | Clear “assistive only” framing, human judgment, access controls |
| Document summarization (tickets, meetings, reports) | High | Loss of nuance, subtle errors | Source visibility, optional human review for critical outputs |
| Content drafting (internal or marketing) | High | Tone drift, minor inaccuracies | Style constraints, review before publishing |
| Internal Q&A over company knowledge (with RAG) | Medium–High | Hallucinations when retrieval fails | Strong retrieval quality, citations, fallback behavior |
| Code assistance / refactoring suggestions | Medium | Subtle bugs, insecure patterns | Human review, static analysis, limited autonomy |
| Decision support (recommendations, analysis) | Medium | Overconfidence, misplaced trust | Explicit uncertainty, auditability, human approval |
| External-facing support bots | Medium | Misinformation, compliance exposure | Tight scope, scripted fallbacks, escalation paths |
| Compliance or legal communication | Low | Regulatory violations, liability | Human-in-the-loop, deterministic systems preferred |
| Autonomous actions (approvals, deployments, payments) | Very low | Irreversible harm | Avoid LLM autonomy; require deterministic controls |
How Nearshore Engineering Teams Support LLM Adoption
Successful LLM systems are rarely about the model alone. They depend on careful integration with existing platforms, data sources, and workflows, and anyone who frames adoption as a model-selection exercise is missing where the real work happens.
Senior nearshore engineers often contribute by designing retrieval pipelines, integrating identity and access controls, implementing observability, and hardening systems against misuse. This is not artificial intelligence research but platform engineering.
By focusing on reliability, cost control, and long-term maintainability, these teams help organizations move from prototypes to production without lighting money on fire chasing marginal model gains, because an LLM stack without solid systems work is scaffolding with no building behind it.
How to Think About LLMs in Your 18 to 24 Month Roadmap
For most mid-sized enterprises, the next two years should center on experimentation and standardization. LLMs are evolving fast. Lock in early assumptions, and you’ll stand a more-than-average chance of turning your team’s excitement into problems in the long-term.
A pragmatic roadmap includes piloting LLMs in internal tools because they’re low-risk with fast feedback cycles. Use them to standardize integration patterns like retrieval and prompt management. For now, defer full automation in high-stakes workflows until controls mature. In the meantime, regularly reassess vendors as their capabilities and pricing fluctuate.
Treat LLMs as a strategic capability with explicit boundaries. Teams that plan like Apollo 13 engineers, solving problems with what is actually on the spacecraf tend to survive. Those who wing it tend to discover fragility the hard way.




