

Key Points:
- Production reliability is now the real challenge. You can launch pilots quickly, but scaling remains a challenge.
- Agents only work in production when they’re tightly bounded, so don’t fall for the hype.
- Governance has to be built into the platform to avoid creating security and compliance gaps.
- RAG and evaluation discipline are becoming default enterprise patterns.
Over the past year, many organizations rushed to use AI tools across business processes. McKinsey reports that nearly 88% of orgs are regularly using generative AI in at least one business function, but most remain stuck in pilot mode, with only a minority successfully scaling AI across the enterprise.
Executives expected competitive advantage from generative AI and autonomous agent experiments. Adoption accelerated. Production reliability did not. Research on leading LLMs suggests that while capability improved, operational consistency continues to lag. According to npj Digital Medicine found hallucination rates of up to 27% on benchmarked factual medical queries.
What’s New?
While there’s still a lot of skepticism, we are clearly entering a new era of artificial intelligence in business.
If you’re still treating AI like a feature your teams can add to existing systems, you’re optimizing for speed today and fragmentation tomorrow. The focus is no longer just model development or deep learning breakthroughs. We already have mature models, and deep learning is no longer a niche field. Model capability is advancing rapidly, but differentiation is shifting away from raw model performance toward how effectively organizations operationalize, govern, and integrate these systems.
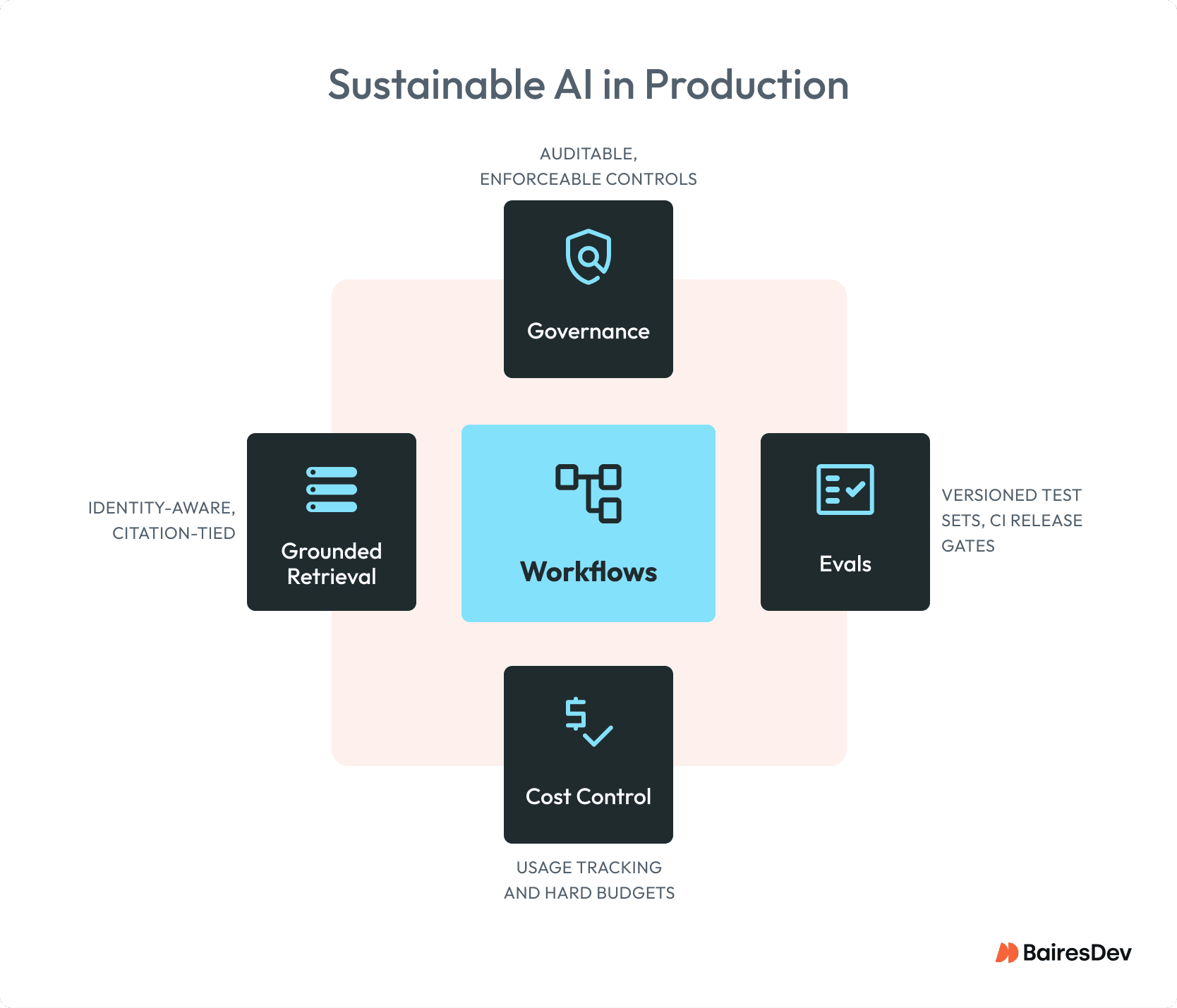
AI success now depends on three things: enforceable governance, disciplined evaluation, and infrastructure that makes oversight automatic.
Surface-level progress can be misleading. The advancements may look incremental on a trend cycle. However, on a platform roadmap, they’re structural.
Decision makers choose what can be standardized and piloted until the sharp edges smooth out: closed models, open models, or whatever OpenAI, Anthropic, and Google release next quarter. The real question is no longer model wins benchmarks, as a few percentiles usually won’t sway business users to a specific model. The question now is which capabilities can be governed and scaled across organizations without breaking high-stakes workflows.
Last year, most AI trends centered on generative AI capability and image generation. In 2026, the hard part isn’t building a demo and dazzling the public with eye candy, but operating AI in production, reliably and with bounded cost.
Even as model capability improves, performance remains inconsistent across tasks, a phenomenon described as the ‘jagged frontier,’ where models can outperform humans in some domains while failing in simple ones. This variability is a major driver of production risk.
Adopt Now, Pilot, or Watch
Consensus-chasing on the “best model” slows delivery without improving outcomes. If your team has a couple of meetings every time one of the leading labs announces an update, you’ll just end up with dozens of meetings and no decision.
So, focus on the basics. Production-ready patterns for 2026 fall into three buckets:
- Adopt now
- Pilot
- Watch
Adopt Now: Platform-Standardize
| Capability | Operational Risk | Minimum Guardrail |
| Agents become bounded workflows | Lateral movement, runaway actions, unclear ownership | Least-privilege access, step-level audit logs, hard cost and time budgets, approval for system-of-record mutations |
| Evaluations and monitoring become standard work | Silent regressions, post-release incidents | Automated evaluation sets, CI gates, and production monitors that detect regressions before users do |
| Retrieval-Augmented Generation (RAG) as default | Hallucinations, data overexposure, non-auditable answers | ACL-aware retrieval, citation enforcement, identity-linked logs |
| Risk frameworks and AI management systems | Inconsistent controls, blocked launches | AI system registry, risk tiers with default controls |
These are not speculative technology innovation bets. They’re becoming operational requirements as deployment expands across core systems.
Pilot: Bounded Product Bets
| Capability | Operational Risk | Minimum Guardrail |
| Multimodal generative AI in workflows | IP exposure, consent gaps in physical and digital assets | Provenance tracking, storage controls, operator review |
| Advanced agent orchestration patterns | Escalating blast radius across services | Narrow scopes, approval checkpoints, strict integration allowlists |
These pilots allow companies to explore complex tasks and multi-step operations without committing to enterprise-wide transformation prematurely.
Certain capabilities are moving fast in research labs and industry conversations. Production maturity hasn’t caught up, and that is a big caveat, along with compute costs.
Watch
| Capability | Operational Risk | Minimum Guardrail |
| Fully autonomous agents | Unbounded authority, irreproducible failures | Avoid until rollback paths and accountable ownership exist |
| Broad persistent model privileges | Systemic compromise, audit failure | Avoid until enforceable scoping is proven |
Many executives want autonomy, but few large organizations are prepared for its governance implications.
The Decision Lens for 2026-2027
An AI capability pulls its weight when it can be standardized as a platform service across teams.
It must:
- Repeat across business units
- Expose identity and permission control surfaces
- Demonstrate measurable output quality
- Provide cost transparency
- Support human-centered artificial intelligence
If you can’t put a capability behind a paved path with an owner, then you have an experiment rather than a strategy.
Agents Become Bounded Workflows
The gap between demo and deployment is now visible. In production environments, successful agent implementations increasingly resemble bounded workflows, where permissions, approvals, and observable state constrain autonomy..
Focus on agents that provide:
- Explicit inputs
- Scoped permissions
- Observable state
- Clear handoffs to humans
You’re dealing with orchestrated automation inside guardrails. The latter can be more difficult to solve than the automation itself.
Autonomous agent patterns without boundaries leak authority. Retries escalate cost. Prompt injection through logs or tickets creates unintended actions. In distributed environments, small permission mistakes scale quickly.
AI agents work best where business processes are procedural but fragmented across systems:
- Drafting pull requests in model development workflows
- Executing runbooks with approval gates
- Handling internal support tickets that answer questions with citations
The value comes from stitching systems together under constraint, not from autonomy.
Evaluations and Monitoring as Standard Work
Model behavior drifts for ordinary reasons such as prompt edits, retrieval tweaks, model swaps, or new releases. Without systematic evaluation, drift surfaces only after it impacts users.
Evaluations must function like CI plus SRE:
- A repeatable regression harness before deployment
- Production signals after deployment
Research from the Stanford Institute for Human-Centered Artificial Intelligence consistently shows variability in LLM performance across tasks and datasets. Outcomes depend on context, not marketing claims.
Minimum standard work:
- Versioned evaluation datasets per capability
- CI release gates for quality, latency, and cost
- Monitoring signals tied to reliability (citation hit rate, refusal rate, escalation rate)
- Drift indicators (topic mix, retrieval recall, tool-call error rate)
- Replayable traces for incident response
Treat production AI like distributed systems. Because they are.
Evaluation is shifting from offline validation to continuous, production-integrated systems, mirroring the evolution of testing in modern software engineering.
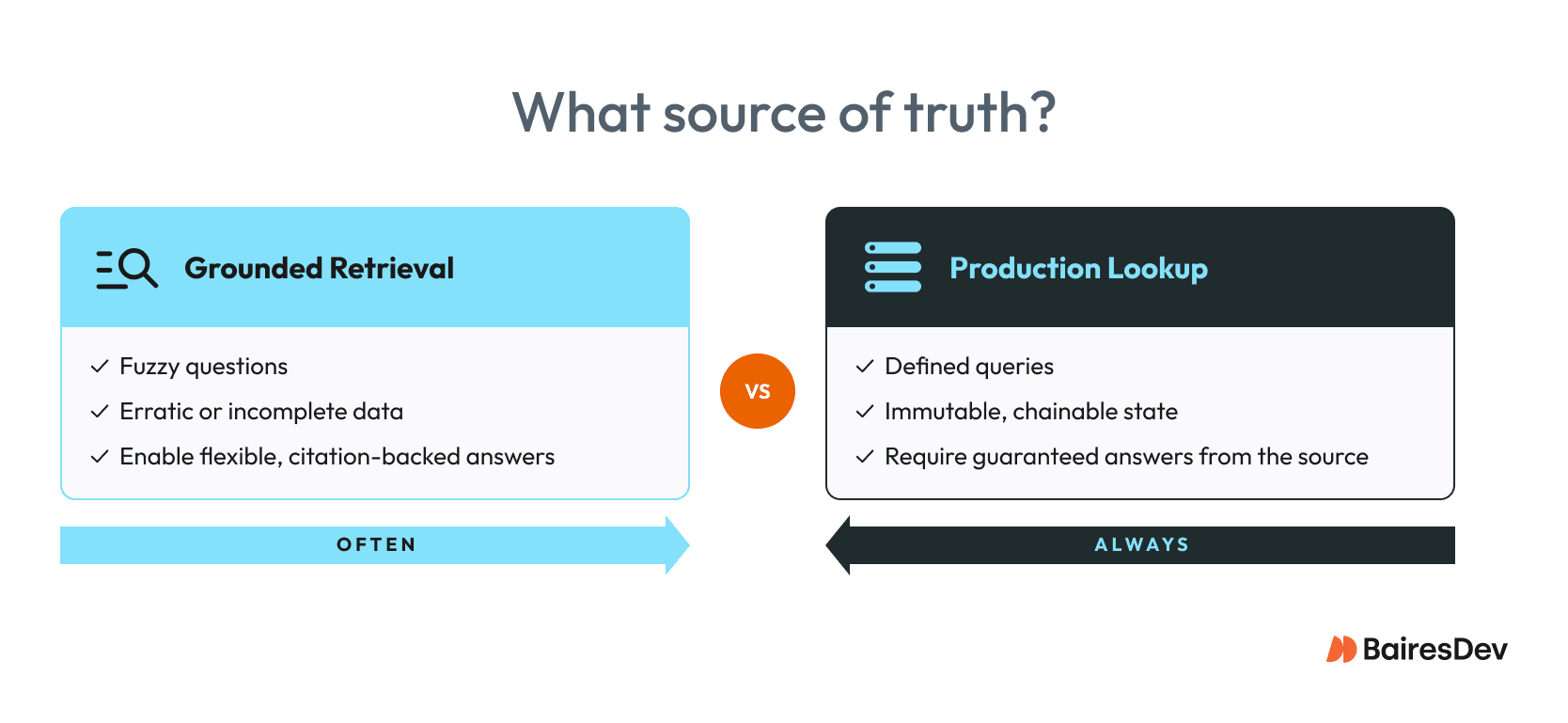
Retrieval-Augmented Generation as the Default Pattern
RAG reflects how mature organizations use generative AI safely. Success in RAG is no longer binary; it’s measured by RAGAS metrics to ensure the LLM isn’t hallucinating even with the right context.
In 2026, the evaluation infrastructure has become the limiting factor for RAG systems. Many pipelines perform well in demos but fail in production without systematic evaluation of retrieval quality and generation grounding. Metrics such as faithfulness, context precision, and answer relevance (included in RAGAS) are now considered baseline.
Knowledge stays in systems of record. Retrieval respects access controls. Answers require citation. This reduces hallucination risk, which remains a persistent issue in LLMs even with the latest models.
RAG’s appropriate when users need flexible answers from evolving knowledge. It’s wrong when correctness depends on transactional state.
Questions like:
- “Can I approve this refund?”
- “Is this customer over their limit right now?”
Those require deterministic services with explicit authorization, so generative responses won’t cut it. Mixing the two creates governance gaps that operators eventually discover the hard way.
Governance as an Engineering Problem, Not Paperwork
Many organizations now have dozens of AI initiatives running in parallel. Some are sanctioned. Others are shadow deployments created under delivery pressure.
An engineering leader should be able to answer:
- How many production deployments are live?
- Who owns them?
- What data do they access?
Too often, no one can.
Governance must move from policy documents to infrastructure.
Risk frameworks, AI system registries, and default control tiers enable consistent decision-making. They allow leadership to focus on strategy instead of containment.
Shadow deployments emerge when the governed path is slower than the unofficial one. The solution isn’t prohibition. It’s making the secure path the fastest path.
Efficiency Beats Raw Scale
Defaulting to the largest model is not a viable strategy. As adoption scales, costs start to mount. Latency and infrastructure bills become visible and sooner or later could become a problem. A recently publicized example involves Uber, which exhausted its 2026 AI budget just four months into the year due to rapid internal adoption. It highlights a broader pattern: AI costs scale nonlinearly with usage, especially when agentic workflows increase token consumption and tool calls.
Define model tiers:
- Small
- Medium
- Frontier
Route requests based on task criticality and expected outcomes. Enforce per-request budgets for tokens, tool calls, and wall-clock time.
Many companies have learned that larger models don’t guarantee better results in multi-step workflows. Efficiency is a competitive advantage.
Across the industry, a consistent pattern is emerging: AI capability is accelerating faster than organizations’ ability to govern, evaluate, and control it.
Multimodal Arrives With Sharp Edges
In the coming year, multimodal generative AI will expand across business workflows.
These capabilities extend artificial intelligence into the physical world through visual interpretation and more advanced content creation.
But multimodal systems ingest sensitive data:
- Faces
- Licensed assets
- Proprietary interfaces
Without provenance tracking and oversight, risk scales quickly. A support copilot that reads customer screenshots can accelerate triage. It can also ingest protected assets into your systems.
Guardrails must include:
- Provenance capture
- Storage controls
- Policy enforcement
- Human review for externally visible outputs
Human-centered artificial intelligence requires oversight, especially when outputs reach customers or partners.
Non-Negotiables for Enterprise AI Deployment
At minimum, every production AI capability should have:
- A named owner
- Versioned evaluation datasets
- Defined cost budgets and monitoring
- Identity-linked logging and auditability
- Rollback and containment paths
If one of these is missing, it’s not production-ready.
The Quiet Shift From Capability to Control
The past year was about experimentation. The coming year is about operational maturity. AI will continue to evolve, models will improve, research will accelerate, and tools will multiply.
But model capability is no longer the gating factor. Governance, evaluation discipline, cost control, and bounded workflows are.
The organizations that win in this era won’t chase every model benchmark. They will standardize what works, measure what matters, and contain what can fail.
The competitive advantage is no longer access to AI, but the ability to operationalize it through workflow redesign, governance, and disciplined evaluation.
Artificial intelligence is becoming infrastructure, and infrastructure rewards discipline.




