

Key Points
- Default to a modular monolith. Microservices earn their cost only when five specific organizational signals are present.
- The framework is deliberately conservative. Splitting too early costs weeks of rework. Waiting costs almost nothing if module boundaries are clean.
- The distributed monolith is the most common failure mode: all the complexity of distributed systems, none of the independence.
- The Citadel pattern offers a middle path: keep the monolith central, extract only the workloads that genuinely can’t run inside it.
Most engineering teams move to microservices too soon. In 2026, the right default is a modular monolith. Microservices justify their operational cost only when specific team topology, scaling, and data ownership signals are present.
Why You Need a Microservices Decision Framework
Microservices are individual services that handle a limited business function and manage their own data. They support separate deployments and offer several benefits, including independent scalability and full data control. However, microservice architecture also presents challenges, including managing multiple deployments, sharing data, and requiring advanced engineering expertise.
We provide a framework for determining which microservices use cases justify adopting a microservices architecture, and when your organization would benefit from doing so. The framework guides you through five key dimensions: team autonomy, deployment needs, scalability requirements, data ownership and separation, and organizational/operational maturity.
By systematically assessing each of these areas, you can make a pragmatic, evidence-based decision about whether microservices are justified in your specific context.
Architectural Spectrum
Each architectural style below is defined in order from least to most complex, with the failure pattern presented last.
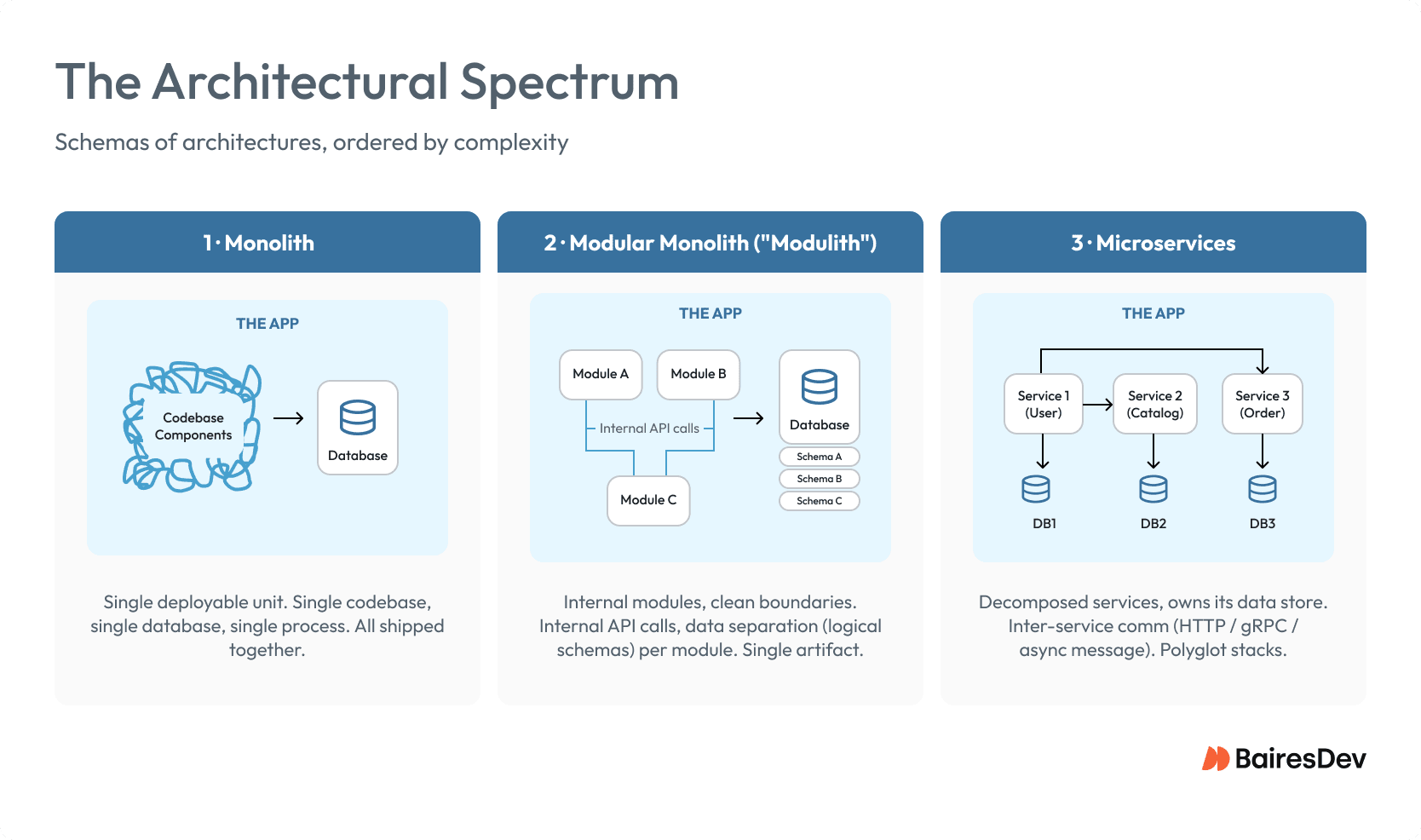
Monolith
A single deployable unit consisting of a single code base, with a single database. Components run within a single process, and are shipped together in a single release.
Modular Monolith (or “Modulith”)
A modular monolith, or “modulith,” is like a traditional monolith but divided into internal modules. Each module has its own tables and internal API, and cannot directly access other modules’ data. This setup keeps a single deployable unit, making it the simplest approach for building applications while still separating concerns for future changes.
Microservices
An application decomposed into multiple small services, each independently deployable. Each service operates a single business capability and is responsible for managing its own data store. Communication between services occurs via either HTTP, gRPC, or asynchronous messaging protocols, using message formats such as JSON for REST APIs or Protocol Buffers for gRPC.
Each service can be developed, deployed, and scaled independently of the others. Microservices evolved from earlier service-oriented architecture (SOA) concepts, but with stricter emphasis on independent deployment and each service owning its own database. Different microservices can use their own programming languages and the desired technology stack best suited to their specific function.
See James Lewis & Martin Fowler’s original 2014 article for the seminal description of this architectural style.
Distributed Monolith
A distributed monolith refers to services that appear to adopt a microservices architecture but, because they share databases, use tightly coupled communication, or require coordinated releases, cannot operate independently.
As a result, they combine the tight coupling of a monolithic architecture with the complexity of distributed systems without the benefits, and any change can affect the entire application.
The Default Architecture in 2026 is a Modular Monolith
For most engineering organizations building software applications in 2026, the optimal initial architecture is a modular monolith. This marks a shift from the previously accepted best practice of defaulting to a microservices architecture from 2015 through 2020. Evidence supports this guidance.
In 2015, Martin Fowler wrote in “Microservice Premium” that all distributed systems incur immediate operational overhead, which only pays off once an organization’s scale and complexity surpass certain thresholds. Before those levels, microservices hinder progress, waste resources, and demand senior engineering talent.
David Heinemeier Hansson (DHH) extends this idea in his writing on “The Majestic Monolith”. He believes well-designed single-codebases fit most applications throughout their lifecycle. He notes that many development teams were misled into thinking a microservices architecture was the default approach. Basecamp, for example, supports six platforms and operates with a modest engineering team, yet remains a (modular) monolithic application. DHH suggests that other organizations may also succeed with this simpler architectural style.
Therefore, instead of simply asking whether or not to use microservices, an engineering lead should ask themselves: Do I have the specific problems that microservices solve? Am I prepared to handle the additional operational cost introduced by microservices? Many existing monolith systems work well and do not need to be replaced.
When a Microservices Architecture is the Right Choice
You should justify a microservices-based split if at least one of the conditions listed below exists today, or will exist in the next 12 to 18 months.
“We may need this eventually” is not enough.
These are the microservices use cases where a microservices architecture delivers significant advantages over a monolith:
- Autonomy at scale: Conway’s Law asserts that a system’s architecture mirrors team structure. If your company consists of multiple teams, each managing distinct business domains and needing autonomous deployments, then microservices are appropriate. Without multiple structured teams, splitting services introduces unnecessary coordination costs, as changes to one service still require coordination with other teams.
- Independence from the entire organization regarding deployments: Independent deployments are essential when several teams must release new features on their own timelines, but schema changes, shared library updates, or refactors currently impede everyone. When this is a clear, ongoing pain point, microservices offer faster time-to-market for individual teams by removing cross-team blockers.
- Independent scalability without application-wide coordination: Certain checkout functions in an e-commerce application may require 10x or 100x more resources than catalog services. Uniform resource allocation wastes money. Segregating resource usage ensures that only the required resources power each specific service, cutting inefficiency.
- Ownership of data and tailored persistence: Different storage types suit different needs. For instance, a large-scale application may use Postgres as its main database, TigerBeetle as its financial ledger, Elasticsearch for search, Redis for session management, and ClickHouse for big data analytics. When persistence choices outweigh the need for consistency across domains, owning data at the service level matters.
This is one of the clearest cases microservices architecture solves well: letting each domain choose its own storage without forcing a single database on the entire application. The following are not valid reasons: “Microservices are modern”, “Netflix does it”, and “Our codebase is large.”
These are preferences or misplaced concerns masquerading as justifications.
“Microservices should not be the default choice.”
When a Microservices Architecture is the Wrong Choice
As Sam Newman, author of Building Microservices, warned at QCon London in 2020: “microservices should not be the default choice.” Newman, Fowler, and DHH have all independently arrived at the same conclusion: adopting a microservices architecture before it is justified can be expensive.
Teams That Are Too Small Cannot Sustain Operational Workloads
Each independent service requires on-call coverage, its own CI/CD pipeline, observability instrumentation, and incident response capacity. When every engineer already owns multiple microservices, a single departure can leave individual microservices without anyone who understands them.
Most functional engineering organizations don’t operate under that kind of fragility. The benefits of microservices only materialize when the organization can staff all the microservices in the system with dedicated ownership.
Operational Prerequisites Are Missing
Release pipelines are too weak, production visibility is limited, and ownership across the codebase is unclear. To implement microservices, companies need to already have operational maturity: API gateways, load balancing, distributed tracing, and container orchestration must be in place before fragmenting the system.
Microservices will not provide operational maturity on their own. Fragmenting a system makes every one of these gaps worse.
New Products with Unstable Domain Boundaries
You have no idea where your bounded contexts should reside. Defining domain boundaries early in complex applications will nearly guarantee that they will be drawn incorrectly. The cost of refactoring a boundary across network calls is typically an order of magnitude higher than refactoring within a single codebase. Starting application development with microservices on a brand-new product almost always leads to premature decomposition.
Most organizations in this situation simply need to fix the monolith. Improve release pipelines. Define ownership. Implement observability. Then re-evaluate the application architecture.
Distributed Monolith Red Flags
Distributed monoliths, services that can not be independently developed/deployed/scaled, have both the coupling of a monolith and the operational costs of microservices. Thus, they get the worst characteristics of both architectures (which is impressive).
Common Database or Shared Schema Ownership
Services read/write from/to the same tables. Changes to the schema now require coordination between every team that owns those tables. Deployment of a single service may fail another service, depending on the application’s interdependencies. This is probably the best indicator for a distributed monolith.
Release Requiring Coordination Across the Entire System
Deploying service A requires deploying services B & C in a specific sequence. Therefore, coordinated deployment across network boundaries results in an essentially monolithic application with augmented latency. At that point, you no longer have a microservices architecture; you have monolith systems connected by a network.
Synchronous Coupling Through Call Chains
A user request causes multiple services to make synchronous calls to each other. Failure at any point in the chain can bring down the entire system’s response for that request. In practice, you replaced reliable in-process function calls with fragile network calls, gaining no independence in return.
Transactions Spanning Many Services
A checkout process will touch multiple services and require an orchestrated rollback when any step fails. Since each service owns its own data, the ACID guarantees provided by the database do not apply across domains. This results in distributed transactions: each one must provide its own compensating actions to roll back failures using the Saga pattern, one of the more complex design patterns in distributed systems (a sequence of local transactions with complex logic for coordinating rollbacks). This forces a hard choice on every domain in the transaction: either accept that data across services will be temporarily out of sync (eventual consistency), or invest in increasingly complex data management logic that grows with every service added to the chain.
If your current architecture describes the situations above, the first thing you should do is almost always consolidate rather than split further. Consolidate tightly coupled services into a single service. Create real boundaries around genuinely independent domains. Decide what still needs to be distributed afterward.
A Decision Framework
Evaluate all the following dimensions of your application architecture as of today based on your current situation. The key dimensions in this framework are:
- Team autonomy: Do you have teams that can and need to work independently of each other?
- Deployment needs: Is there a need to deploy portions of the system without affecting others?
- Scalability requirements: Are there distinct scalability hotspots or requirements across different parts of your application?
- Data ownership and separation: Can different services own their data without requiring overlap or frequent sharing?
- Organizational and operational maturity: Does your organization have the infrastructure and processes (CI/CD, monitoring, incident response) necessary to manage multiple independent services?
Most of the time, teams fail to apply this framework because they evaluate their roadmap for the next few years as if it were their present.
| Dimension | Yes | Not Yet | No |
| Team topology | 5+ autonomous squads with clearly defined domain responsibility | 2-4 teams with overlapping domains | 1-2 teams or unclear responsibilities |
| Deployment independence | multiple teams unable to release every day due to coordinated releases | occasionally there is some blocking however it can be managed today | no heavy coordination costs |
| Scalability hot spots | there are distinct modules that have 10x+ different loads that waste money due to uniform scalability | loads vary however do not waste enough money to justify splitting | uniform scalability across modules |
| Data ownership | stores are aligned with domains and persistence is relevant and appropriate | domains are separated to some degree and there are shared DBs | all schema are shared, cross-domain query |
| Operational maturity | for each service there is continuous delivery (CI/CD) and distributed tracing, SRE (Site Reliability Engineering) and DevOps practices are established | basic APM (Application Performance Monitoring), linear CI/CD, on call practices are inconsistent | manual deploys, limited visibility into operations |
How to read your score:
- Mostly “yes”: Microservices are justified for the specific domains where you scored “yes”. Do not extract everything. Extract only the modules where the score applies and leave the rest in a monolith.
- Mostly “not yet”: Use a modular monolith with strictly bounded contexts. Make sure module boundaries are clear now so extraction will be possible later when one of the signals crosses from “not yet” to “yes”.
- Mostly “no”. Stay monolithic. Get your operational foundation in order before revisiting your architecture.
This decision framework is deliberately conservative. The cost of breaking off one service too early is weeks of refactoring. The cost of going microservices-first on a product with unstable domain boundaries is steep: wasted engineering cycles redrawing boundaries across network calls, and infrastructure overhead running multiple microservices before the business requirements justify them.
Drawing Service Boundaries
When the previous decision framework indicates that an extraction is justified, the next question is: where does the boundary belong?
Eric Evans (author of Domain-Driven Design) and many others agree: tie boundaries to business capabilities rather than technical layers.
Example: a “user service” which owns registration, profile, authentication, and session management is a coherent business capability built around related business features. A “database service” holding everyone’s data is a technical layer and, within a few months, will become a shared database by another name.
There is a very narrow exception worth mentioning. Some technical concerns operate in ways that differ dramatically from the rest of the application (a polling endpoint that gets hammered thousands of times per second, an inbound email gateway, a CPU-bound image processor). They may have their own process, even though they look more like technical layers than business capabilities. These belong in a different category (covered in the Citadel section below).
Outside of this exception, developers implement boundaries along domain lines, not technical ones.
A Service Decomposition Worksheet
For each candidate service, gather a cross-functional team, including engineering leads and relevant stakeholders, and answer the following four questions.
- Business capability: What single business outcome does this service own? If your answer requires “and” more than once, you are combining capabilities. Split further or redraw the boundary.
- Data ownership: What data does this service exclusively own, and what does that boundary protect? If another service needs to read or write this data, how would it do so? If services need to access data directly through a shared database, you’ve built a module that introduces extra network latency.
- Independent deployability: Can this service be deployed without coordinating with any other service? If not, what you drew was a module boundary with network calls on top.
- Failure isolation: If this service goes down, what else in the rest of the system still works? If your answer is “nothing,” this service serves as a core synchronous dependency. Isolation in name only. You grew a failure surface instead of reducing it.
This worksheet should be completed whenever you are considering splitting off a module or re-evaluating existing boundaries; revisit it as your system evolves or when team or product needs change. If any answer is ambiguous or unclear, the boundary is not yet ready for extraction.
Retrofitting bad boundaries after the fact is one of the most expensive mistakes in microservices adoption. Getting system design right at this stage saves months of rework later.
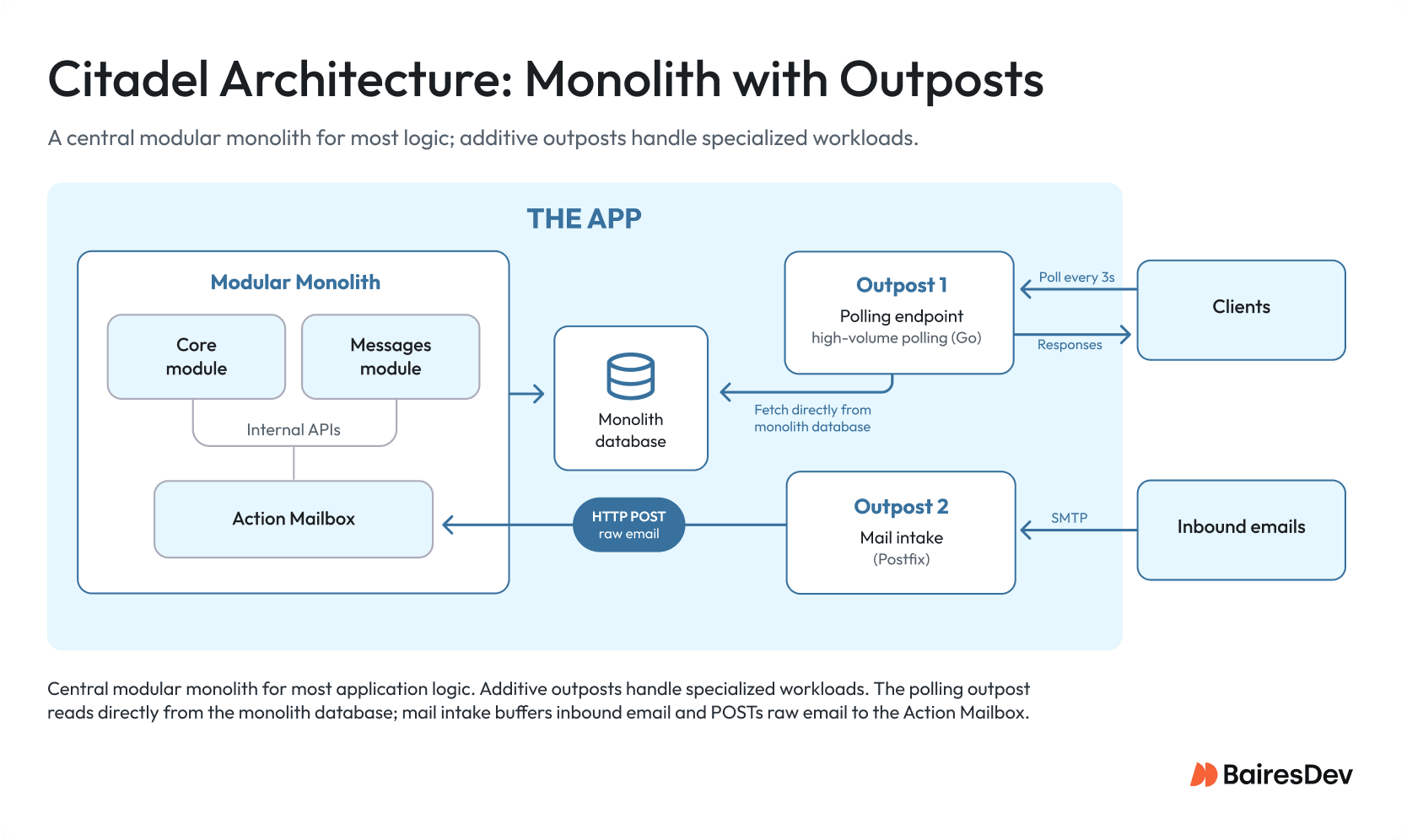
The Citadel Architecture: Monolith With Outposts
There is another option between the monolith and a fully distributed system: the Citadel, a term coined by DHH. Use your main monolithic structure for the majority of your applications’ logic. Create smaller, independent services, called “outposts,” for particular service workloads that cannot be integrated into your monolithic architecture.
The Basecamp Campfire example is a good illustration of this approach. Each time a client connected to Campfire, it polled its connection every 3 seconds, and it sent a message to the poll endpoint to scan for new messages. The vast majority of these polls would have no new messages. About 20 lines of Ruby code were needed to get the poll endpoint working. When you put all the polling logic for new messages into the full monolith (including authentication, database queries, and responses), it creates excessive, unnecessary load.
The development team moved the polling endpoint into its own outpost. Because the outpost had to handle a very high volume of requests, it was rewritten over the years in different programming languages optimized for high performance (C, C++, Go, Erlang). The rest of Basecamp remained a monolithic Rails application. HEY’s email processing uses a similar method. When emails arrive via SMTP, Postfix receives them, writes them to disk in case of failure, and then sends them to the Action Mailbox in the HEY app via HTTP.
A couple of items to note. First, outposts are where a true “technical layer” separation can occur, because the workload needs (performance, fault tolerance, availability) do not align with what the monolith supports. Second, outposts are additive. The monolith remains central; the outposts remain around it.
For organizations that do not meet the criteria for building microservice-based applications at full scale, the citadel may represent a better solution than either extreme. The citadel addresses real performance and scalability problems without imposing the operational burdens of distributed systems.
Case Study: Return Of The Monolith At Amazon’s Prime Video
In March 2023, Marcin Kolny shared his experience creating a monolith-based version of the Video Quality Analysis (VQA) streaming service, originally built on a distributed, serverless architecture. He stated that after doing so, both infrastructure costs fell by over 90% and VQA could scale to levels far greater than it could in the previous configuration. His story received considerable interest, covered by The New Stack among others, as it was posted from within Amazon, Prime Video being one of the world’s largest streaming platforms, and AWS leading the adoption of microservice-based architectures.
VQA analyzes thousands of concurrently streaming videos in real time for quality issues (such as block corruption, video freezing, and/or audio/video synchronization problems) and triggers a process to fix them. The service was designed from the start as a microservices-based architecture using AWS Lambda for computation, AWS Step Functions for orchestration, and S3 to transfer video frames between three separate components (media converter, defect detector, and orchestration).
At scale, a few major cost drivers emerged:
- Specifically, Step Function billing occurs per state transition, and VQA generates multiple such transitions per second of video processed.
- As a result, Kolny indicated that the service hit account-level scaling thresholds at approximately 5% of projected capacity.
- Additionally, S3 round-trips between components added cost and latency to the overall operation, which compounded as volume grew.
Kolny and his team consolidated all three functional areas into a single monolithic application running on EC2 and ECS cloud environments. Thus, intermediate data transferred between functions occurred in memory. Orchestration became simply calling internal functions. Thanks to the changes, infrastructure costs decreased by over 90%, delivering substantial cost savings, and VQA’s ability to scale was significantly increased over prior ceilings.
Again, this story isn’t intended to say that a monolithic architecture is “better” than a microservices architecture for everyone. However, the distributed architecture chosen solved problems that the workload didn’t really have (infinite horizontal scaling and independence across individual functions), while also making problems it did have substantially worse. High-throughput intermediates favor colocating processes.
Ultimately, the team chose a microservices architecture that didn’t fit the problem domain, and their bill told them so. Fowler’s Microservices Premium in action.
Begin With a Modular Monolith
In 2026, for most greenfield software development projects, building a new system from scratch begins with a modular monolith. One deployable, one database, one CI/CD pipeline. Each module has strict boundaries within the code base: it owns its data, exposes it only through an internal API, and never directly accesses another module’s data.
This buys you two things and one option.
- First operational advantage: there is one thing to deploy and debug.
- The second advantage is disciplined coding within the codebase, which lets development teams ship new features to their modules while preventing the codebase from growing into a large ball of mud.
If one of your dimensions grows and moves from “not yet” to “yes”, you will now have a clean separation path to lift the bounded module into its own service or outpost in weeks. Teams can then deploy new features for specific microservices without affecting the rest of the monolith.
Historically, a large monolithic application would take years to refactor; although GenAI-assisted refactoring may shorten the time frame nowadays, the cost and risk of doing so remain significantly larger than starting with clean module boundaries.
You will know when your organization has grown past the modular monolithic architecture and needs a microservices-based architecture. There will be some very clear indicators, including actual team synchronization costs, actual need to partition data, and actual scaling hotspots. Prior to these being present, the modular monolithic approach wins in areas that engineering leads really care about, including deployment speed, infrastructure costs, and the ability to change your mind without rewriting the entire application.
Don’t move to microservices because of market demands or trends. Move when the framework dimensions say you should, and when the benefits of microservices clearly outweigh the operational cost.
Keep asking the decomposition question(s). Will this module currently earn a “yes” based upon at least one aspect of the framework dimensions that warrant the additional complexity? If yes, break off that module. Only that module. And ask again.




