
Executive Summary: This article explores why AI features fail silently because engineering teams lack the testing discipline to catch probabilistic regressions. Evaluations — repeatable, versioned, scored against defined quality criteria — are the missing layer. Paired with observability and production monitoring, they prevent silent degradation without slowing delivery. Currently, evals are table stakes for any team shipping LLM features.
If you’ve shipped an AI feature, you’ve probably felt the uncomfortable gap between “it works on my laptop” and “it works in production.” The feature behaves differently tomorrow than it does today and your code didn’t change. A prompt tweak, a model upgrade, a retrieval adjustment, or a subtle shift in user inputs quietly degrades an experience your team already signed off on.
I’ve experienced this kind of issue firsthand. Imagine a support workflow using AI to summarize customer conversations and flag issue categories. Swap in a newer model, and on the surface, nothing looks wrong. The same thread gets a cleaner summary, except “billing dispute” is now “account support,” and the detail that actually mattered, that the customer was disputing a duplicate charge, didn’t make the cut. No crash, no alert, nothing in the logs. Routing degrades, reporting drifts, and agents respond to the wrong problem. That is exactly the kind of silent regression traditional QA tends to miss.
The fix isn’t more manual QA. It’s adopting a discipline that classic software engineering already understands, rooted in repeatable tests, versioned artifacts, and regression gates. For AI features, that discipline is evaluations and most teams building on LLMs still don’t have it.
This is a practical CTO-level view of how to build an evaluation-first workflow for AI features. One that respects nondeterminism, accelerates iteration, and prevents silent regressions.
The Core Challenge: AI Features Are Probabilistic Systems
Traditional testing assumes deterministic behavior where given input X, the function returns output Y. But LLM systems don’t behave like pure functions. Outputs can vary across runs, temperature settings, upstream providers, and model versions. That means exact match assertions rarely work.
Take a support ticket summarization feature. You run the same input three times and get different conciseness scores each time. Nothing in your code changed. Your quality policy needs to account for that variance, which means stop asking “is this output identical?” and start asking “does this output meet a quality bar?” From deterministic correctness to probabilistic quality.
Evaluations: The Unit Tests for AI Systems
An evaluation (eval) is a repeatable way to measure whether your system’s behavior is acceptable for a given input set. You run the same test set today, tomorrow, and after every change, and you compare results against a baseline.
Evals typically combine a few scoring approaches.
| Scoring Approach | Best For | Catches | Limitations |
| Rule-based checks | Compliance, safety, output formatting | PII leaks, banned terms, citation gaps | Can’t access quality or reasoning |
| Similarity checks | Constrained tasks with expected outputs | Semantic drift, coverage gaps | Struggles with open-ended or creative outputs |
| Gold standard scoring | Quality assessment, tone, accuracy | Reasoning errors, off-brief outputs | Requires defined criteria + LLM judge overhead |
| Task success checks | Agentic workflows, multi-step processes | Wrong tool calls, incomplete workflows | Doesn’t evaluate output quality, only completion |
Most production AI systems need more than one approach. A common starting point is pairing rule-based checks, such as, which are fast and cheap to run, with gold standard scoring for outputs that require quality judgment. Agentic workflows typically need task success checks layered on top of both.
When we started building evals, the tooling wasn’t the hard part. Defining good evaluation criteria was and that’s not unique to AI. Anyone who’s written acceptance criteria for complex software knows how hard it is to articulate what “good” means before you’ve seen a bad output.
The other friction point is organizational. Evals don’t fit neatly into how most teams think about QA. It requires AI/ML fluency that most QA functions don’t have yet, and getting teams to treat evals as part of the delivery process rather than an extra step is a real mind shift. Most organizations underestimate both.
Observability, Evaluations, and Versioning: The Core Tooling for Reliable AI Systems
Most engineering teams already have tooling standards for traditional software, like logging, CI/CD, or version control. These are the infrastructure that makes debugging and iteration possible. AI development needs an equivalent stack. There are three table stakes capabilities:
Tracing and observability: You need traces to answer which prompt executed, what context was provided, which model was used, and what output it produced. This is how you explain unexpected behavior after the fact. Agents may invoke multiple tools yet end up producing similar outputs, so optimizing the execution path also reduces latency and cost.
Evaluation workflows: You want to run evals over traces (what happened in production) and over controlled datasets (what should happen in ideal scenarios).
Prompt and artifact versioning: Prompts are production code. Treat prompts, retrieval configurations, judge gold standards, and eval datasets as first-class artifacts, which should be reviewed, versioned, and reproducible.
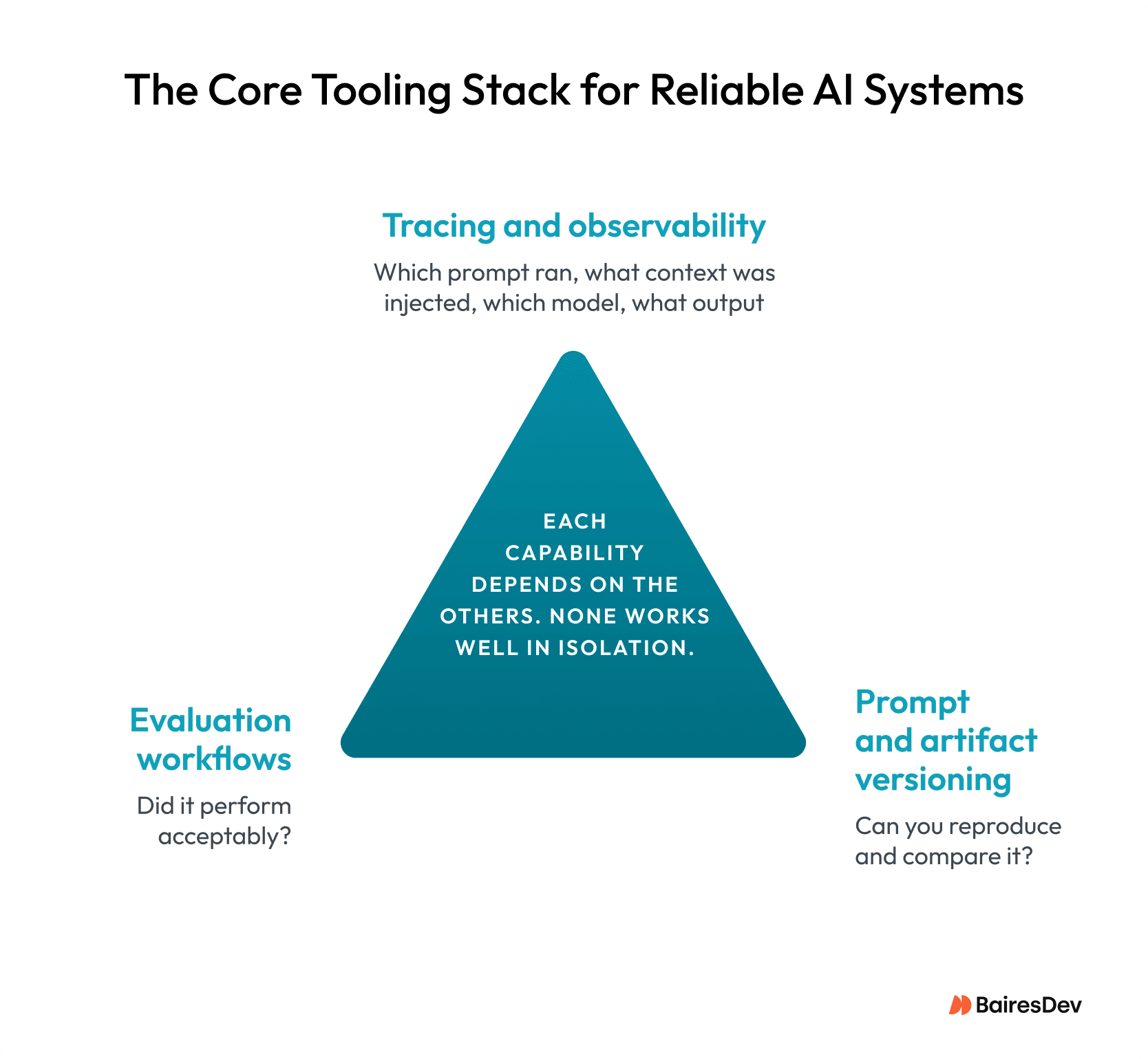
None of these three capabilities works well in isolation. Observability without evals gives you data but no verdict. Evals without versioning leave you unable to explain why a score changed. And versioning without observability means you’re testing blind. Together they form the foundation everything else in this article builds on.
Version Everything (Or You Can’t Debug Anything)
When an AI feature regresses, the root cause is almost always “a tiny change somewhere” and the challenge is that in an LLM system, “somewhere” covers a lot of ground. It’s not just your code. It’s the prompt template, the model and provider, the runtime parameters, the retrieval configuration, the context actually injected at inference time, and the eval gold standards used to validate it. Any one of these can shift behavior without triggering a conventional alert.
Most software engineers working with code review assistants have felt this firsthand. One of those assistants could start producing vague, unhelpful suggestions after a routine infrastructure update. The code didn’t change. The prompt didn’t change. But the chunking strategy in the retrieval config was quietly updated and the context being injected at inference time was no longer the right size for the task. Without versioned artifacts across the full execution context, that regression could take days to trace.
That’s why versioning in AI development is more than just about code. It’s about the entire execution context. When something breaks, you need to reconstruct exactly what ran. Without that, you’re not debugging; you’re guessing. Versioning gives you the receipts but it doesn’t solve the deeper challenge of evaluating a system that, by design, never produces exactly the same output twice.
Testing Nondeterministic AI Systems in Practice
A common anti-pattern is trying to force LLMs to behave like deterministic code. You can reduce variance, but you can’t eliminate it entirely in most real-world setups and building an eval strategy that assumes you can will keep failing you.
The approaches that work are all built on the same underlying logic: evaluate distributions, not individual outputs. In practice, that means a few things.
- Run each test case multiple times and score the spread, not a single result.
- Set pass rate thresholds rather than exact match requirements. Something like “90% of runs score 4/5 or higher” is a meaningful quality gate.
- Treat scores as noisy measurements with confidence intervals rather than precise point estimates.
- And for risky changes, canary evaluation lets you run a new version against a shadow slice of real traffic before full rollout.
In other words, you’re not testing one output. You’re testing a behavior profile.
If distributions replace exact outputs as your quality signal, you need a scoring mechanism that can actually assess them at scale and that’s where the LLM-as-judge pattern comes in.
Using LLMs as Judges for AI Evaluation
For many AI features, simple metrics don’t capture what users actually care about. Rubric based LLM as judge scoring can. The pattern is straightforward. You define 3–5 criteria with clear definitions, like helpfulness, correctness, safety, and formatting. You then provide the input and the system output, along with an optional reference answer, and ask a capable model to score the response against that rubric and return structured results.
The mechanism is easy to implement across most tools and frameworks. Getting value from this pattern comes down to discipline. Rubrics need to be specific enough that the evaluator is not improvising. The judge model, rubric, and prompt should all be versioned like any other production artifact. Human review should also be used periodically to calibrate the evaluator and catch scoring drift over time.
In practice, the judge models that hold up best in my experience tend to be frontier LLMs (GPT-4 and above, Gemini, Claude) for rubric-based scoring where reasoning quality matters. Lighter classification tasks can run on smaller models like Gemini Flash or GPT minis without meaningful quality loss. There’s also growing viability in open-source models for teams that need more control over the evaluation stack.
Production Monitoring: Evaluation Doesn’t Stop at Deploy
In production you want four things running continuously:
- Trace collection for live workflows
- Cohort analysis across customer segments and intents
- Drift monitoring on inputs and embeddings for retrieval-heavy systems
- Eval runs over sampled traffic
The goal is early detection, not post-mortem diagnosis. Most AI incidents appear gradually, as small degradations that compound over time rather than sudden breaks. Automated evals handle scale well, but there’s a category of judgment they can’t replace, and knowing where that line sits is part of building a system you can actually trust.
Where Human Review Still Matters in AI Evaluation
Automated evals are great at scale, but some categories of judgment consistently fall outside what they can assess. Brand voice and tone, nuanced safety calls, and ambiguous correctness where ground truth is genuinely fuzzy are among them. This is also the case for the discovery of failure modes your eval suite wasn’t designed to catch in the first place.
The practical model is automated evals for continuous regression detection, and targeted human review for high-impact changes, high-risk scenarios, and periodic calibration of the evals themselves. Neither replaces the other. The question is knowing which one the situation calls for.
The discipline is clear but getting there doesn’t require a big-bang rearchitecture. You may just need a pragmatic rollout.
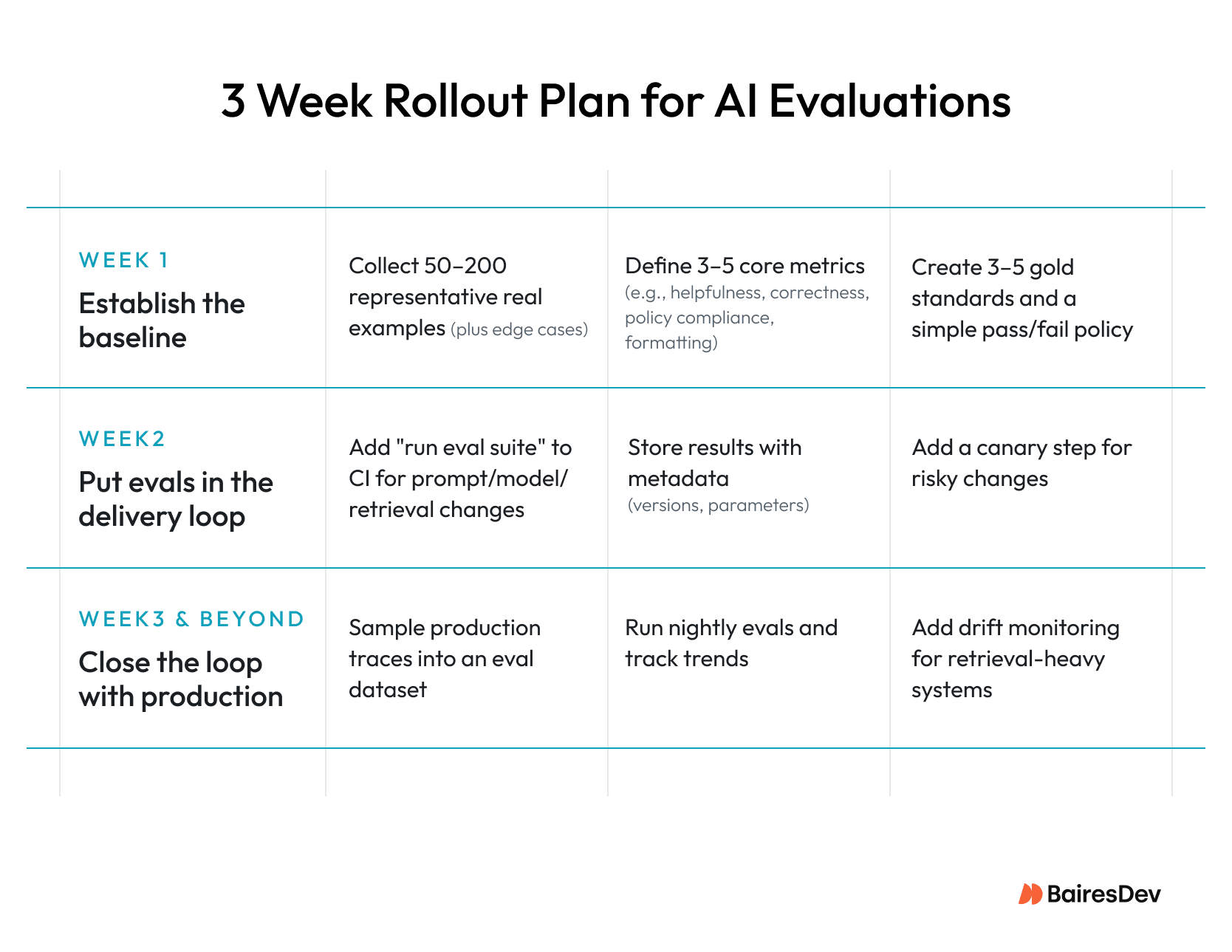
A Practical Rollout Plan for AI Evaluations
The rollout spans three weeks. Week one is about definition, assembling representative examples and establishing quality criteria. Week two moves evals into the delivery pipeline, so every prompt, model, or retrieval change is tested before it ships. Week three closes the loop with production monitoring, nightly eval runs, and drift detection.
Why Evaluation Discipline Will Define Reliable AI Products
Without evaluation discipline AI features degrade quietly, eroding user trust before metrics are impacted. If you treat evaluation as an organizational muscle, you’ll ensure AI features stay reliable as the underlying models and capabilities keep shifting. So, build an evaluation muscle: quality defined as a contract, changes versioned like code, regressions caught before customers find them, and monitoring that detects drift and decay.
This practice is no longer optional. It will be the difference between AI features that feel magical and AI features that feel unreliable.
Key Takeaways
- AI features fail silently — probabilistic outputs degrade in ways traditional QA is not designed to catch.
- Evaluations are the unit tests for AI systems: repeatable, versioned, and scored against defined quality criteria.
- The hardest part of building evals is not the tooling — it is defining criteria specific enough that the evaluator is not improvising.
- Observability, evaluation workflows, and artifact versioning only work as a system; none of the three delivers value in isolation.
- Automated evals handle scale; human review handles judgment — knowing which one the situation calls for is part of building a system you can trust.




