

Key Points
- Microservices are an organizational scaling model as much as a software architecture.
- More services do not reduce coordination. They just move it from code boundaries to runtime boundaries.
- Async messaging reduces runtime coupling, but it raises the bar for contracts, observability, and operational discipline.
- Microservices pay off only when team autonomy, release independence, and differentiated scaling matter enough to justify the added operating complexity.
One of the most persistent myths about microservices architecture is that more services create more agility. In practice, the opposite is often true: more services introduce more coordination surfaces.
Microservices do not deliver agility by default. They create the conditions for it, but only when you deliberately manage the coordination between them. That means independent deployment, controlled data flow across the system, and limiting how failures spread.
To understand why, start with what microservices architecture actually is, and what changes compared to a monolith.
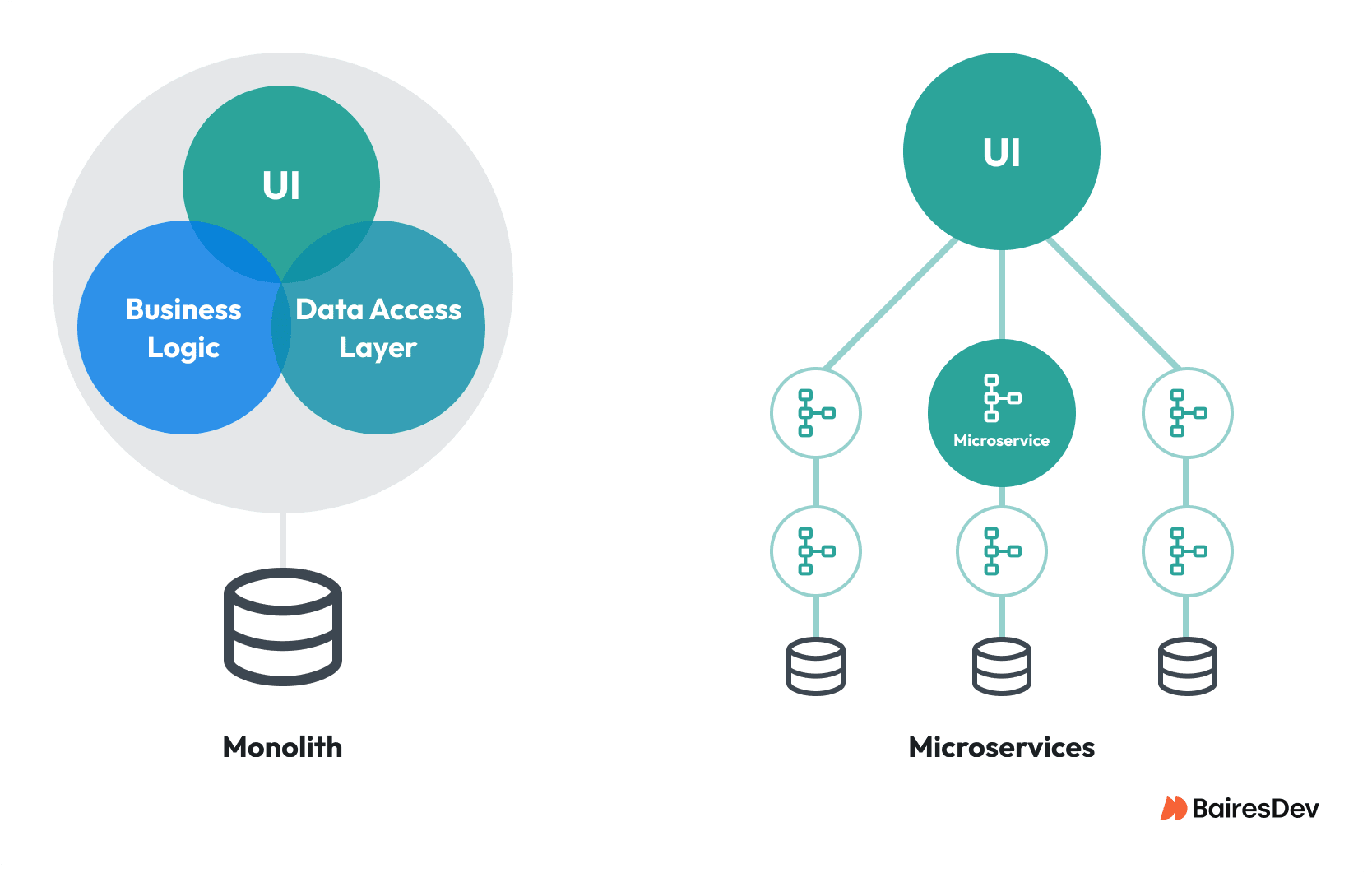
What Microservices Architecture Actually Is
Let’s frame the argument with a leadership-level definition:
A microservice is a team-owned, independently deployable runtime boundary that encapsulates a specific business capability, owns its persistence layer, and communicates with other services exclusively through APIs or events.
This definition highlights three aspects that determine whether services are cohesive units:
- Independence: The service can evolve and deploy without coordinating changes across the system.
- Data flow: The service controls its own data and exposes it through APIs or events, rather than sharing schemas.
- Failure blast radius: When a service fails, the impact is contained and communicated explicitly to other services.
Microservices architecture is not about the number and size of the software artifacts within a service. It’s about moving coordination from implicit (in-process) to explicit (over the network).
Microservices vs Monolithic Architecture
Consider a simple order workflow: Create an order, charge a payment, reserve inventory, and schedule shipping. Now assume the process fails at the final step, shipping.
Traditional Monolithic Applications
In a monolithic application, these steps typically execute within a single process and often within a single database transaction. If the shipping step fails, the entire operation can be rolled back.
This simplifies coordination and ensures consistency. The “coordination” is internal, such as at the database layer for transaction rollback. But it also means that changes to any part of the workflow require redeploying the entire monolith, and failure blast radius can bring the entire monolithic runtime down.
The Difference with Microservices Architecture
In a microservices architecture, the steps are handled by separate services, each within its own data and deployment lifecycle:
- Order
- Payment
- Inventory
- Shipping
There is no single transaction coordinating them. Instead, each service performs its work independently and communicates over the network.
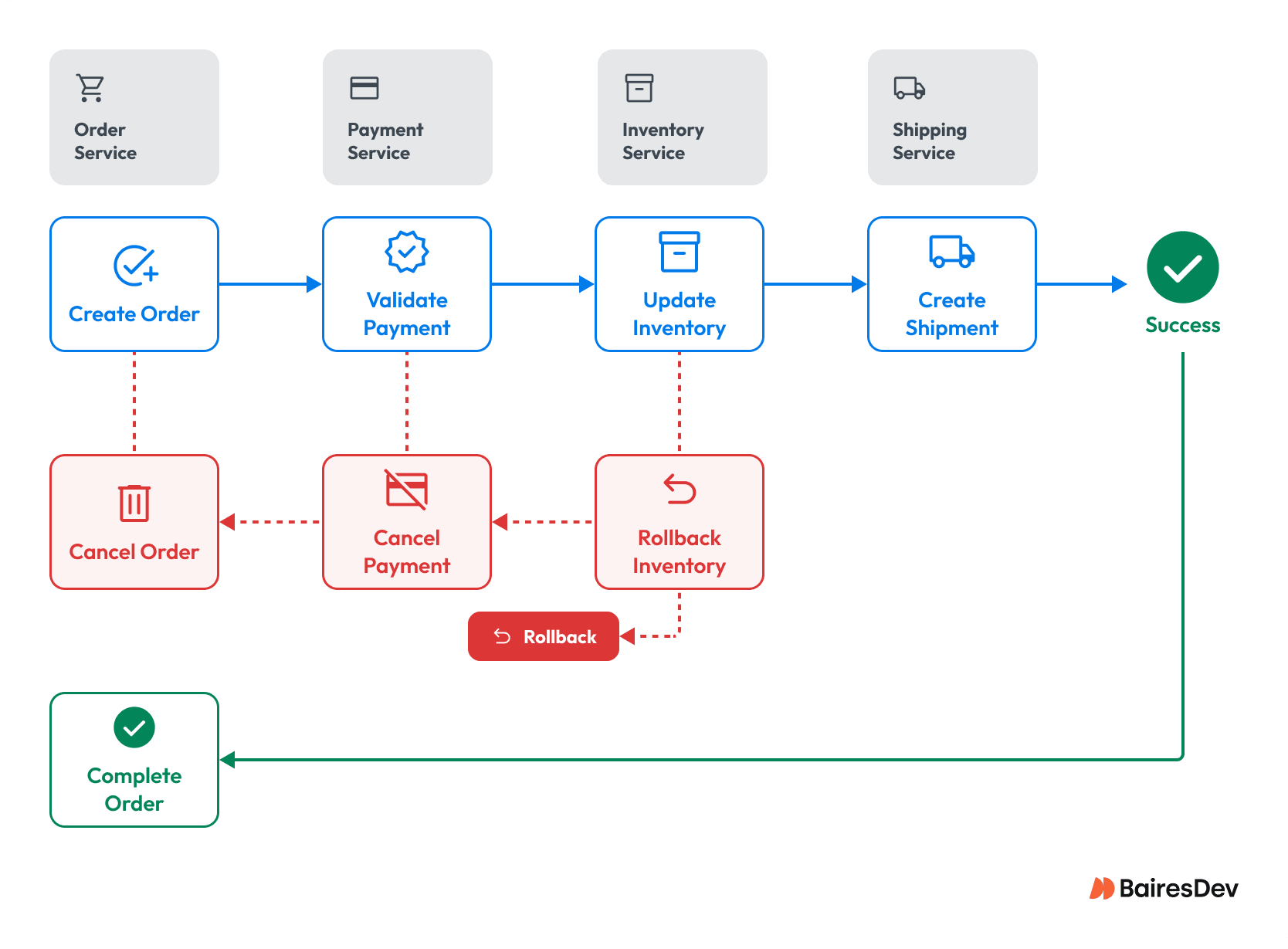
When the shipping step fails, there is no atomic, implicit rollback. Response to the shipping failure happens explicitly by event communication:
- Shipping service pushes the failure message to the other three services
- Inventory puts the item back to available status
- Payment refunds the money
- Order reports failure back to the consumer
This pattern is often referred to as a saga. It replaces atomic rollback with coordinated compensation. The result is greater flexibility and isolates failures to a smaller blast radius.
But it only works if the coordination gets distributed across the microservices. Distribution forces the coordination to be explicit. It must be designed intentionally.
The Core Components that Make Microservices Work
Microservices architecture moves the coordination out of the application and into the network. Once that happens, coordination becomes a system-level concern. The following components emerge as some of the necessary mechanisms that manage it.
In practice, this shifts architectural focus toward inter-service communication and API contracts. These disciplines are the first line of defense to maintain service independence and resilience.

API Gateway: Simplifying Clients, Centralizing Risk
Microservice independence means each service owns its business logic. Cross-cutting concerns like auth, routing, and rate limits do not belong inside individual services. They belong in a shared layer.
This leads naturally to the API gateway component. The API gateway governs who has access to the services inside, how to find them, and how many transactions they can manage. The API gateway simplifies what each microservice needs to implement by centralizing common infrastructure and letting the microservice focus on its unique job.
The API gateway also simplifies the clients that need to access the microservices. They only need to talk to the API gateway, and the API gateway takes care of call routing.
The gateway is itself a service that encapsulates cross-cutting concerns as its purpose in the ecosystem. Therefore, like any service, it requires disciplined boundaries.
Under time pressure, the API gateway becomes a tempting target for shared business logic. This is a critical mistake. Discipline misjudgments like this can lead to processing bottlenecks, deployment dependencies with other microservices, and centralized risk if the business logic in the API gateway is wrong.
API gateways work best when they contain the minimum code needed to address cross-cutting concerns. You’ll know if business logic has leaked into the API gateway when the services it orchestrates must be deployed with it.
Inter-Service Communication: Sync vs Async
Once services are split, the next challenge is getting them to work in concert. This leads to the microservices architecture component of inter-service communication:
| Sync | Service A calls Service B via REST | Pros: Simple
Cons: Creates call dependency chains. |
Taken to an extreme, dependency chains duplicate the monolith, but trade atomic transactions for latency and larger blast radius. |
| Async | Service A sends a message to Service B | Pros: Decouples services
Cons: Adds complexity |
Async requires more complexity, such as a defined message contract and message routing infrastructure. |
Each communication pattern has its place:
- When services are close transaction partners, then REST calls are often the best choice. An example would be services calling a proxy microservice that fronts interactions with an external SaaS endpoint. This is transactional by nature, so a REST call suffices.
- When services are indirectly related, then sending messages makes more sense. An example would be a set of services that need to audit data changes. Sending each audit event into a queue is lightweight, and a downstream consumer service processes the audit events.
Long synchronous call chains create instability. Overuse of messaging can obscure tight relationships that should be explicit. Both are forms of hidden coupling.
Well-Defined APIs: Sensible Interactions and Preventing Leakage
Services should be able to interact without knowing each other’s internal implementation details. They should also be independently deployable. If either of these conventions has been violated, the boundary layer has broken down.
API consumers should never depend upon these leakages:
- Details about schemas or data models.
- How the internal processing runs.
- Special API calling sequences or required delays between calls.
Services lose independence when these details leak. Deployment requires DevOps coordination, and poorly defined APIs reintroduce tight coupling in ways that make it harder to diagnose problems.
Service Discovery and Load Balancing in Dynamic Environments
Infrastructure becomes part of the coordination problem when services communicate over a network. Transaction partners can be load-balanced, instances can get swapped due to errors or scaling, and services can get relocated to an entirely different region.
Service discovery and load balancing are the components that solve coordination problems in the dynamic network environment.
- Service discovery: Lets a service’s current URL get resolved at runtime so that consumers don’t need explicit “how to call Service X” configurations.
- Load balancing: Services may need to run more instances when demand increases. In this case, service discovery will return the URL of the load balancer, and the load balancer routes to the best service instance.
Distributed systems rely on service discovery to keep services communicating, and on load balancers to make sure the workloads are distributed evenly. These components add infrastructure complexity, but remove hardcoded dependencies.
These components make service coordination explicit. The effectiveness of a microservices architecture depends on how well that coordination is designed and enforced.
Data Ownership and Consistency: Where Most Systems Break
Microservices architecture splits the monolithic database into service-aligned boundaries, each dedicated to a given service’s business capability. These data stores may live on shared infrastructure, but each service must retain exclusive control over its schema and data.
Why Each Service Owns Its Data
Problems arise when multiple services depend on the same database:
- Cross-service transactions become impractical: Each service controls its own transaction boundary. Coordinating rollback is problematic at best (see two-phase commits, next).
- Deployment crosses service boundaries. Schema changes for all dependent services to have coordinated release, defeating service independence. Ignoring this problem will cause mysterious failures and possibly database corruption.
A service’s data boundary must be treated with the same discipline as its API boundary. If services access each other’s data stores directly, independence is lost even though the codebases are separate.
What Happens to Consistency
It may be tempting to build distributed transactions, where services delay commits until all participants are ready. But in practice, this requires the services to:
- Wait on each other by holding locks
- Fail or succeed together
The result is system-wide coupling, increased latency, and reduced scalability.
Instead, microservices systems accept that data state becomes distributed truth. Eventual consistency emerges over time through coordination, not transactions.
Most systems adopt patterns such as sagas, where each service persists its own changes and failures are handled through compensating actions. This shifts consistency from a database concern to an application-level responsibility.
Related Patterns: Read Models, Event Sourcing, API Composition
With data boundaries, additional patterns help services interact more effectively:
- Read models (CQRS): Denormalized and/or aggregated views optimized for query access across services.
- Event sourcing: Recording state changes as a sequence of events for auditability and replay.
- API composition: Combining frequently-used service calls into a single interface for consumer simplicity (either locally in a service or globally in an API gateway).
These patterns build on the same premise: coordination is explicit, and services interact through well-defined contracts rather than shared state.
The Tradeoff
The benefits of microservices—independent deployment, scaling, and failure isolation—depend on strong data boundaries.
When those boundaries hold, services remain autonomous. When they break, coordination shifts back into a shared state, and the system regresses toward a distributed monolith.
Designing for Failures and Resilience
The benefits of microservices only hold if independence survives real-world operation, including deployments, incidents, and ongoing change. This is where many systems quietly regress.
Why Failures Propagate in Distributed Systems
Distributed systems introduce failure modes that don’t exist in monolithic applications:
- Latency: Network calls add variability, especially under load
- Partial failure: Dependencies may fail intermittently or degrade unpredictably
- Timeouts: Calls may never return, even when services are partially available
These conditions compound in synchronous call chains. A single failing dependency can stall upstream services and cascade across the system.
Core Resilience Patterns
To prevent failures from spreading, systems must actively limit how services depend on one another at runtime:
- Timeouts and retries: Bound how long services wait and retry failed calls with controlled policies (for example, exponential backoff)
- Circuit breakers: Stop calling failing services to prevent repeated load on degraded dependencies
- Bulkheads: Protect resources like threads, connections, or queues so one failure occurrence cannot exhaust the entire system.
These resilience patterns limit how far failures spread and how long they persist, allowing the system to recover without widespread disruption.
Preventing Cascading Failures
Resilience is not just about reacting to failure. Proactive design can also reduce its blast radius:
- Limit long synchronous chains: Long call chains increase latency and amplify failure
- Control retry behavior: Unbounded retries can overwhelm already degraded services
- Manage resource usage: Failure paths must release resources promptly to avoid system-wide exhaustion
Without these controls, distributed systems fail in ways monoliths do not: Through gradual degradation, unpredictable interactions, and cross-service impact that makes root cause analysis difficult.
A Note on Chaos Engineering
Some organizations validate resilience by intentionally injecting failures into the system. This practice reveals hidden dependencies and tests how services coordinate under stress.
In microservices, failure is not an edge case. It is a normal operating condition. Resilience depends on how well system design anticipates that reality.
Operating Microservices Without Losing Independence
The benefits of microservices only hold if independence survives in production. This includes deployment challenges, weathering incidents, and surviving ongoing development.
Deployment Independence is Fragile
If services must be deployed together, independence has already been compromised. This often points to unstable contracts, shared assumptions, or CI/CD pipelines that couple release processes.
Deployment independence is not automatic. It must be enforced through stable interfaces and decoupled build and release workflows.
Observability Is Not Optional
In distributed systems, coordination is only as reliable as it is visible. Understanding how requests move across services requires centralized logging, metrics, and distributed tracing.
As service count grows, debugging overhead increases rapidly. Without strong observability, failures become difficult to diagnose and slower to resolve.
Tooling Can Reintroduce Coupling
Tooling decisions—repository structure, CI/CD pipelines, and AI-assisted workflows—can improve developer productivity, but they do not define service boundaries. In microservices environments, these choices can just as easily introduce hidden coupling.
Consolidating repositories or tightly coupling build pipelines may simplify development workflows, but they can also force services to build, test, or deploy together. When that happens, coordination cost moves from runtime into the delivery process—and independent deployment becomes harder in practice.
The key question is not how code is organized, but whether services can evolve and be released independently without cross-team coordination.
At scale, microservices fail not in architecture diagrams, but in day-to-day operation when independence erodes.
Avoiding the Distributed Monolith
A distributed monolith is not defined by how services are packaged, but by how tightly they are coupled in practice. Systems often arrive here gradually—while still appearing, on the surface, to follow microservices patterns.

The most common failure modes are predictable:
- Shared databases: Multiple services depend on the same schema, forcing coordinated changes and breaking data ownership.
- Synchronous dependency chains: Services rely on long chains of REST calls, increasing latency and amplifying failures across the system.
- Coordinated deployments: Services must be released together to avoid breaking changes, eroding deployment independence.
- Leaky APIs: Consumers depend on internal details such as schemas, workflows, or timing assumptions, reintroducing hidden coupling.
These patterns reintroduce the very coordination costs microservices are meant to reduce. The system becomes harder to change, harder to scale, and more fragile under failure, but without the architectural simplicity of a monolith.
Avoiding this outcome requires discipline:
- Treat data boundaries as strictly as API boundaries
- Design APIs that prevent implementation leakage
- Limit synchronous dependencies where possible
- Enforce independent build and release processes
Microservices architecture succeeds when services are independent in practice, not just in design. When those boundaries erode, the system doesn’t become more flexible. It becomes a distributed monolith.
The Coordination Tradeoff
More services do not create more agility. They create more coordination surfaces.
Microservices architecture works when that coordination is made explicit and controlled, through clear boundaries, disciplined data ownership, and resilient communication patterns. It fails when those boundaries erode and coordination slips back into shared state, synchronous chains, or deployment dependencies.
The question is not whether to adopt microservices, but whether your system and your teams are prepared to manage the coordination they require.




