

Key Decisions Covered:
- When GraphQL’s flexible data retrieval justifies its governance overhead
- When REST APIs and HTTP-native caching are the defensible default
- The three failure modes that turn GraphQL adoptions into six-month recoveries
The Real Question Is Not Which Is Better
The GraphQL vs REST API debate is often framed as a technology competition. It is not. It’s more of an organizational than a technical choice.
REST APIs have powered the internet for well over two decades and remain the right choice for a large class of problems. GraphQL is a query language for APIs when clients need flexible and efficient access to complex data graphs across multiple surfaces. It was created in 2012 at Facebook and open-sourced in 2015 to solve a rather different and specific problem.
So what should your evaluation criteria focus on? Which approach reduces delivery friction without creating maintenance debt? The decision framework provided in this article maps directly to three factors: client diversity, data complexity, and operational capacity.
Two Different Mental Models
REST APIs and GraphQL represent fundamentally different philosophies about who controls the data contract.
REST APIs (Representational State Transfer) are resource-oriented. The REST architecture exposes multiple endpoints and standard HTTP methods (GET, POST, PUT, DELETE) map to CRUD operations.
The server defines what each endpoint returns. HTTP status codes carry semantic weight: 404 means the resource does not exist, 429 means you are being rate-limited, 500 means something broke on the server. Every layer of your infrastructure, such as CDNs, API gateways, and APM tools, understands these HTTP semantics natively.
That’s why RESTful APIs are the path of least resistance for every monitoring, caching, and security tool your team already runs.
GraphQL is an API query language that is client-driven. GraphQL servers are commonly exposed through a single HTTP endpoint (typically POST /graphql) where clients send query, mutation, or subscription operations.
The server responds with precisely that structure as JSON data. GitHub’s GraphQL API v4 describes it directly: clients “replace multiple REST requests with a single call to fetch the data you specify.”
This is the practical difference: REST APIs ask “Which endpoint gives me this resource?” GraphQL APIs ask, “What shape of data do I need?”
Data Retrieval as The Primary Decision Driver
The clearest case for GraphQL APIs is the over-fetching and under-fetching problem endemic to REST APIs at scale.
Over-fetching is fairly simple: GET /users/42 returns 30 fields. Your mobile client needs 4. Every unused field costs bandwidth, parse time, and memory.
Under-fetching is more expensive. Rendering a list of blog posts with author names and comment counts requires multiple REST API requests: GET /posts, then N calls to GET /users/{id} for each author. This is the N+1 problem: one initial fetch triggers a cascade of network requests. Three levels of nesting turn it exponential.
Sounds simple enough, but this is where GraphQL and REST diverge sharply.
GraphQL APIs resolve both in a single round-trip. Client requests define exactly what data to fetch – no waterfall, no redundant data fetching.
But here is a critical nuance: GraphQL solves client-side N+1 but introduces server-side N+1 if resolvers are not implemented correctly. Complex data querying amplifies this: each field resolver executes independently, so a list of 10 posts can trigger individual database queries per author.
Facebook’s DataLoader library solves this by batching resolver calls within a single execution tick. For resolver patterns that would otherwise create N+1 database access, batching tools such as DataLoader are effectively mandatory.
REST is simpler when your API serves predictable resources, your clients need roughly the same data, and standard HTTP caching is a major part of your performance strategy.
Caching is REST’s Structural Advantage
REST’s most significant production advantage is HTTP-native caching.
REST works naturally with standard HTTP caching because GET requests, URLs, and cache headers fit the model CDNs already understand. This means Cache-Control, ETag, and Last-Modified headers work with zero application code, making your life easier.
On the other hand, GraphQL APIs usually require more deliberate engineering for caching because many deployments use POST to a single endpoint, which makes HTTP caching less straightforward than REST. Apollo’s documentation acknowledges this directly: you cannot cache GraphQL results using HTTP caching as effectively as REST results.
The primary solution to this caching conundrum is persisted queries (also called trusted documents). Basically, they allow clients to pre-register queries during development, and the server stores a hash-to-query mapping. At runtime, clients send a hash ID, enabling GET requests with stable URLs that CDNs cache normally.
Persisted queries also block arbitrary query execution, which is good for security, but only works for first-party clients.
For client-side caching, Apollo Client and Relay normalize GraphQL responses by object identity. However, this is a schema design discipline, not a default.
Theory aside, what about real-world caching performance?
For public, unauthenticated, read-heavy endpoints (like product catalogs or static content APIs), REST GET requests can reach high CDN cache hit rates with zero application-layer work. GraphQL with persisted queries can reach comparable rates for first-party clients. However, without persisted queries or other deliberate caching strategies, GraphQL is usually much harder to cache effectively at the CDN layer.
Error Handling: Enter The Monitoring Blindspot
Error handling in REST APIs relies on infrastructure-native semantics. Each API request produces a status code: 500 triggers your PagerDuty alert, 429 tells your API gateway to throttle. Every observability tool understands these HTTP status codes.
GraphQL error handling works differently. Malformed or invalid GraphQL operations fail validation before execution, but many runtime errors are returned in the response body. In many GraphQL implementations, execution errors are returned in the response body, often alongside HTTP 200, which can create a monitoring blind spot if teams rely only on HTTP status codes.
Another difference is that GraphQL also supports partial success. A single query can return some data and some errors simultaneously. So, your frontend must handle three states: data only, errors only, and data-plus-errors. Bear in mind that React Error Boundaries, Apollo’s onError link, and retry logic often depend on HTTP-level failure signals, so teams need to add explicit handling for errors returned alongside data.
Any team adopting GraphQL must reconfigure alerting before go-live. Error handling in REST APIs uses HTTP 4xx/5xx rates, so APM setups that rely mainly on HTTP 4xx/5xx rates can miss many GraphQL execution failures unless teams add response-level monitoring.
Plan for it before launch.
GraphQL Handles Versioning Better
The versioning story for RESTful APIs is well-understood and painful. API backward compatibility requirements force breaking changes to ship as /v2, running in parallel with /v1 indefinitely. At scale, you are maintaining multiple REST API versions with separate documentation, testing, and client development overhead. It works, but it’s hardly elegant.
On the other hand, GraphQL APIs are designed to be versionless. Additive changes (e.g., adding fields, types, and optional arguments) are non-breaking by specification. The @deprecated directive marks fields for removal while keeping them functional. GitHub and Shopify both run versionless GraphQL APIs in production using this approach.
It still requires discipline and rigor. A schema registry with breaking-change detection before deployment is not optional at team scale. Apollo GraphOS, GraphQL Inspector, and Rover CLI all provide schema diff and breaking-change validation.
This is convenient, as teams that don’t want to pay for a managed platform have two solid open-source paths.
Security and Governance Overhead
For public APIs, the GraphQL and REST security profiles differ significantly: RESTful APIs are the lower-risk default. Third-party consumers get predictable access patterns via standard HTTP methods, HTTP auth, and no exposure from schema introspection.
GraphQL APIs introduce security complexity that must be explicitly engineered. For example, an API request containing deeply nested GraphQL queries can traverse the entire data graph and exhaust server resources. The GraphQL security specification defines the required controls: query depth limits, cost analysis, alias-count limits, and introspection controls.
Introspection also deserves attention, as disabling introspection is often necessary but insufficient. The primary bypass technique is field suggestion, where GraphQL servers return “Did you mean X?” responses in validation errors by default, exposing type and field names without introspection enabled.
Luckily, you can disable field suggestions in production (Apollo Server’s hideSchemaErrors option handles this). The effective security posture combines persisted queries, introspection control, field-level authorization in resolvers, and error message sanitization.
When to Run Both
The most common enterprise pattern for GraphQL and REST is aggregation, not replacement: GraphQL serves as the layer above existing REST APIs and existing API architectures.
The GraphQL and REST split is clean: internal microservices remain REST-based, and a GraphQL gateway or Backend for Frontend (BFF) sits in front, aggregating responses from multiple services into a unified graph. Client applications send GraphQL queries to this layer, and backend teams never touch client contracts directly. This can eliminate many client-side request waterfalls without requiring a full rewrite of the underlying REST services.
Apollo Federation extends this to distributed teams: individual subgraphs own a domain, and a central router composes them into a unified schema. Treat Federation as a separate adoption milestone, as the router is a separate infrastructure component. Schema composition can fail in ways that affect the entire graph, and the directive model has a real learning curve. Teams without a dedicated GraphQL platform engineer should not begin here.
This GraphQL and REST hybrid works when clients have divergent data needs and existing REST APIs are stable. In practice, this model works best when someone has clear ownership of the GraphQL gateway as an ongoing service.
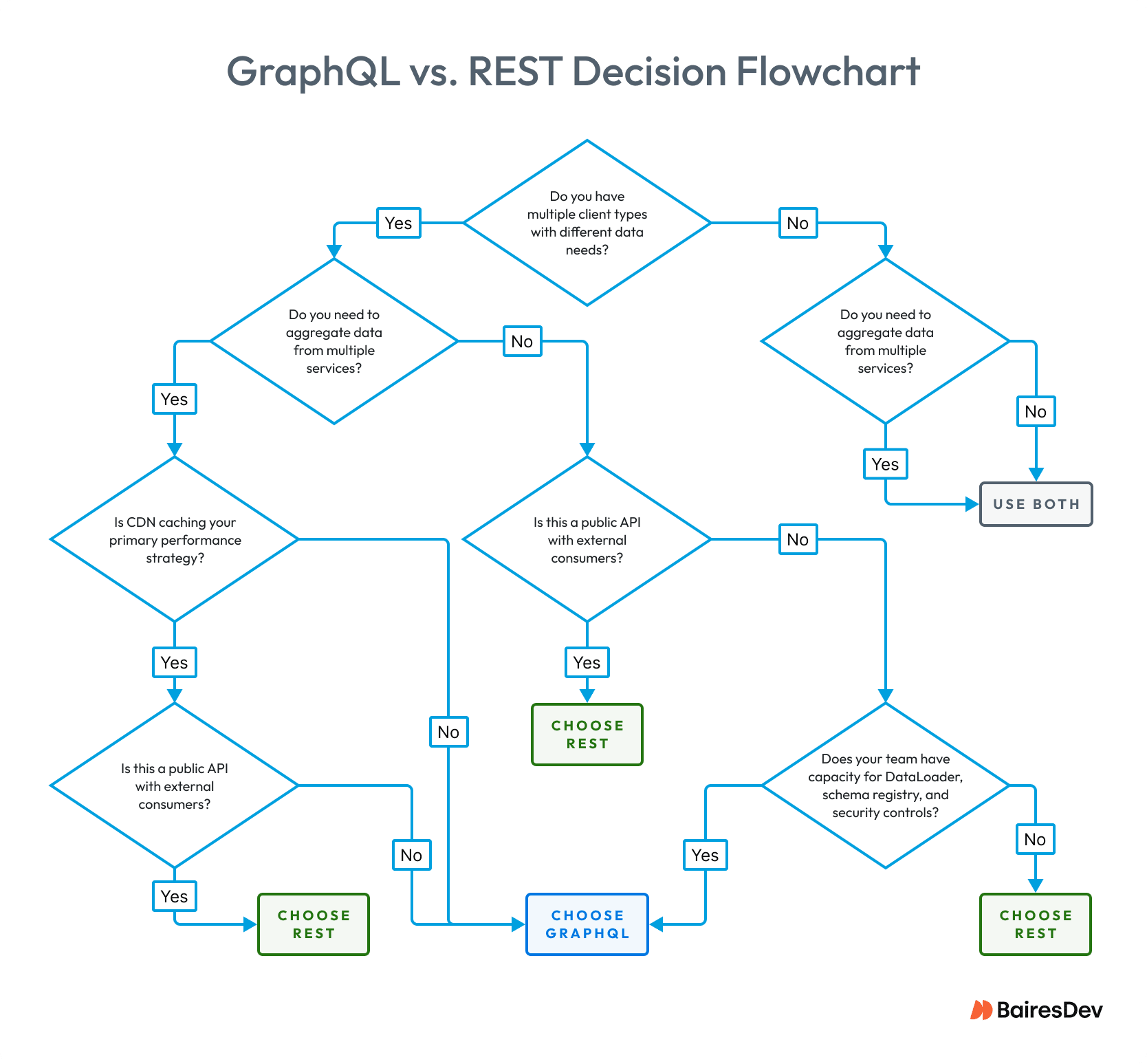
The Decision Framework
Common Traps Before You Choose
Before we proceed, let’s point out three failure modes that repeatedly derail GraphQL adoptions:
- Governance debt: ship without a schema registry, and one team’s schema change breaks another team’s clients. The solution? Add the registry before the first production deployment.
- Monitoring blindspot: alerting on HTTP error codes misses all GraphQL failures. You need to reconfigure APM tools to inspect response bodies before go-live.
- Server-side N+1 without DataLoader: skipping DataLoader ships a latency bomb that only surfaces under production load. Don’t cut corners or you’ll regret it in prod.
| What you’re deciding | Choose REST | Choose GraphQL |
| Who are my clients? | One or two client types, stable data needs | Multiple clients with different data shapes |
| How complex is my data? | Simple CRUD, few entity relationships | Complex graph with many interconnected entities |
| What is my caching strategy? | CDN edge caching is the primary performance lever | Client-side or persisted query caching is acceptable |
| Who consumes this API? | Public or third-party developers | Internal or first-party clients you control |
| How do I handle errors? | Standard HTTP semantics required across infrastructure | Team will reconfigure observability for body-level errors |
| How do I manage versions? | Versioned releases are acceptable | Schema evolution with explicit deprecation preferred |
| Does my team have capacity? | REST expertise, no additional tooling required | DataLoader, schema registry, and complexity controls already in place |
Cost and Talent
What about the cost? Both in terms of tooling and infrastructure, and the talent needed to put it all together?
The most obvious difference is that managed GraphQL platforms carry licensing costs, whereas REST does not. Apollo GraphOS, managed federation routers, and schema registry hosting add up at team scale. Factor this into your infrastructure budget before committing.
While by no means rare, GraphQL expertise is less common than REST in most engineering hiring markets. Adopting GraphQL before your team can upskill or hire additional people increases dependency on the engineers who set it up.
There are quite a few tradeoffs to consider, and as we pointed out in the intro, this is mostly an organizational decision, not a purely technical one.
Failure Mode Reference
| Failure Mode | Required Guardrail |
| REST: Version sprawl (/v1, /v2, /v3 in parallel) | Disciplined deprecation policy with sunset dates |
| REST: Over-fetching on mobile | Field projection, sparse fieldsets, or BFF layer |
| REST: Client-side N+1 waterfalls | Server-side batching or GraphQL aggregation layer |
| GraphQL: Server-side N+1 | DataLoader required for all database-touching resolvers |
| GraphQL: Unbounded queries | Depth limits and cost analysis enforced at the gateway |
| GraphQL: Silent errors | Body-level error monitoring; never rely on HTTP status alone |
| GraphQL: Schema drift | Schema registry with breaking-change detection before every deploy |
| GraphQL: Auth delegation failure | Field-level authorization in resolvers, not only at gateway |
Choose the Right Tool, Not the Trending One
GraphQL and REST APIs aren’t competing standards and GraphQL is not a REST replacement.
GraphQL APIs are a data access layer optimization for teams with real client diversity and complex data querying needs. REST APIs are the right default for the majority of API problems, especially public-facing ones. And no, REST APIs aren’t a legacy thing, at least not yet.
The teams that get this decision right ask two questions: does our client diversity actually require flexible GraphQL queries, and do we have the capacity to govern it? If the answer to both questions is affirmative, then the investment pays off. If not, well-designed REST APIs are likely to outperform a GraphQL layer that no one owns.




