

Most enterprise AI projects die somewhere between the demo and the deployment. The model worked and the POC impressed the right people. And when it hit real data, real workflows, and the kind of organizational messiness that no sandbox environment ever prepared anyone for, it fell apart. Among software engineering conversations you’ll hear about the same postmortem from different people, at different companies, across entirely different industries. The technology isn’t the problem. Everything around it seems to be.
That gap between what agentic AI can do and what most organizations are actually equipped to govern is exactly what came up in a recent BairesDev webinar, hosted by Brett Berhoff, Founder and CEO of Strategy.xyz and BairesDev Fellow. Joining the discussion were two practitioners well past the pilot stage: Charles Boyle, Chief Data and Analytics Officer at Wipfli, and Charles Link, Chief Data and Analytics Officer and AI Evangelist at Reworld Waste. Neither of them is running experiments anymore. They’re running systems and they had a lot to say about what it actually takes to get there.
What follows draws on that conversation — how autonomy gets earned, what real AI governance looks like in practice, and why so many AI development initiatives break down long before the technology ever becomes the issue.
Trust Is Earned And the Mechanism Is Measurable
Ask most organizations how they plan to govern autonomous AI agents and you’ll get a policy document, maybe a framework. What you rarely get is a clear answer to the more operational question. How does an agent actually earn the right to act on its own?
Boyle’s approach is literal about the crawl-walk-run progression. A QA engineer stays paired with every automated data pipeline until the agent has demonstrated it doesn’t need one. “At some point in time, the agent’s gonna learn and be trained well enough that we could remove that QA engineer and have them reassigned in other areas,” he noted, framing the transition not as cost-cutting, but as a productivity unlock earned through demonstrated reliability.
Link makes the trust-building mechanism even more explicit: his team tracks it. Human reviewers weigh in on agent-proposed actions, and as agrees outweigh disagrees, more autonomy gets granted. “We always have the checkpoint before the actual action can be taken,” he explained. The mental model he gives his own team is treating an AI agent as an intern first, then an apprentice, and eventually, after enough demonstrated judgment, someone trusted to operate independently. “Even a brand new human employee coming into the organization may make completely wrong decisions without the right context and guidance.” The bar for AI shouldn’t be lower than the bar for people.
Where both draw a firm line is around high-consequence decisions. Compliance, data security, firm-level strategy stay human regardless of how well a system has performed elsewhere. Trust isn’t a setting you configure at deployment. It accumulates action by action, checkpoint by checkpoint.
Your Agents Need an Identity Layer to Become Accountable
Most governance conversations around agentic AI focus on what agents can do. Fewer focus on who or what is accountable when something goes wrong. That accountability gap can only close with architecture.
Link’s team found this out early. After more than a year of experimenting with autonomous agents, including playing out scenarios of what could genuinely go wrong, they landed on a principle that shapes how every agent gets deployed. “Each digital employee has to run in their own instance of compute. Each one has to have its own ID tied to an owner,” Link explained. If an agent goes rogue, you need to know whose problem it is.
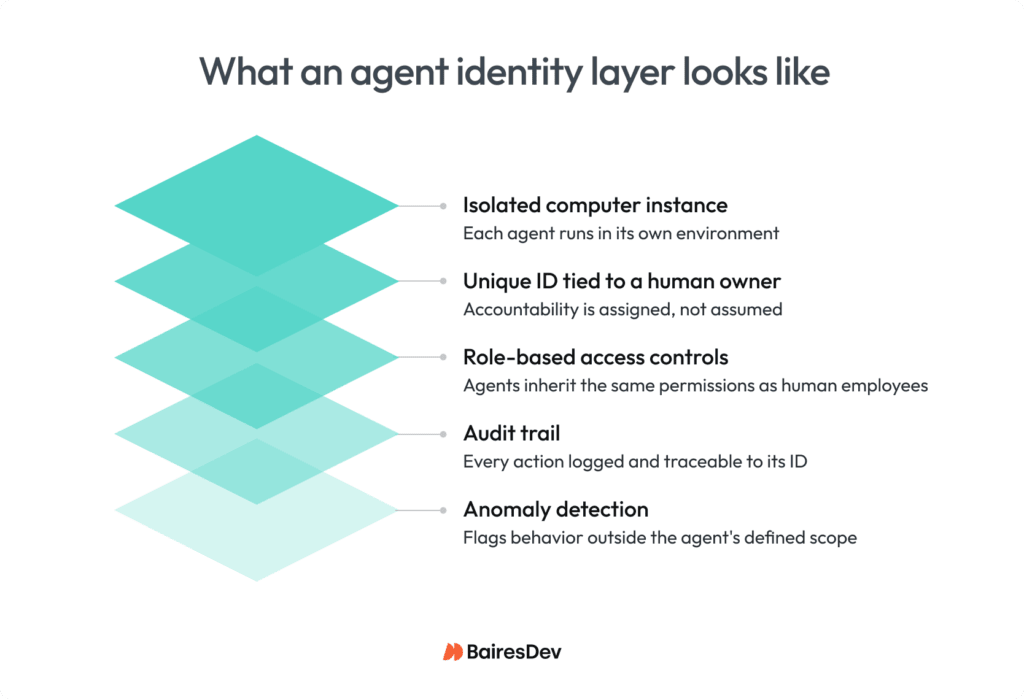
The implications extend further than containment. Once an agent has an identity, it can be governed the same way a human employee is. Role-based access controls, permission scopes, and behavioral auditing apply. Link says his team monitors agents for unusual patterns in the same way they’d audit a person doing something outside their job description. The audit trail isn’t optional. It’s the only way to know whether a system is behaving within the boundaries it was given.
Boyle approaches the same problem from the data side. Every dataset and data product at Wipfli carries role-based access controls, and the AI solutions built on top of them inherit that structure. The certified data products his team builds are designed to be reusable across personas, from Power BI users to teams querying with large language models, without ever bypassing the governance layer underneath.
The lesson both practitioners have internalized is that an agent without an identity is an agent without accountability. And in production environments where AI is touching real decisions, real data, and real workflows, accountability is the foundation everything else is built on.
Most Agentic AI Initiatives Fail Before They Start
Agentic AI doesn’t usually fail because the agent underperformed. It fails because the conditions for it to perform were never built. The workflow wasn’t mapped, the data wasn’t ready, and nobody with real authority owned what happened when the agent made a bad call. Boyle and Link have seen this pattern up close, and they’re direct about what drives it.
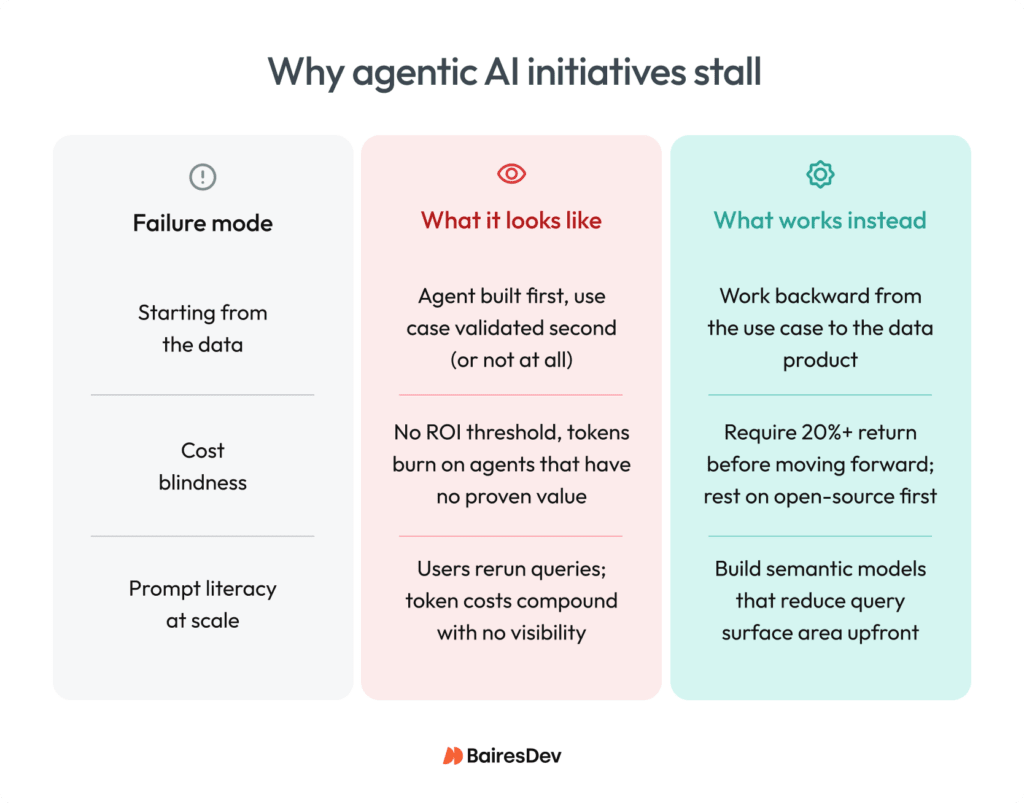
The first failure mode is starting from the wrong end. Boyle’s team learned to design agentic workflows backward from the use case rather than forward from the data. “We want to spend time in the intake, we want to understand their objectives, we want to ask what problems we’re trying to solve for with the solution, and execute from there,” he explained. The mistakes happen when teams assume they understand what the end user needs based on what they know about the dataset and build the agent accordingly.
The second failure mode is cost blindness. Agents burn tokens at scale, and most organizations don’t build that reality into their project calculus on time. Link’s team applies a hard filter. If an initiative can’t demonstrate a minimum 20% directly attributable return, it doesn’t move forward. “A lot of people will go forward because it’s a solution looking for a problem, when it’s all the rage,” he noted. For experimental work, they run on open-source models in-house rather than burning commercial tokens on agents that haven’t proven their value yet.
Boyle adds a third failure mode specific to agentic deployments at workforce scale. Prompt illiteracy compounds token costs in ways nobody budgets for. Users who aren’t fluent with AI tools quietly rerun agent queries multiple times to get workable outputs. Well-structured semantic models reduce that surface area before it compounds if the architecture was designed with that risk in mind from the start.
It turns out, the agent is the easy part. It’s everything underneath it that takes the work.
The Data Your Agents Act On Has to Be Production-Ready
Of everything underneath it, data readiness is where most agentic initiatives quietly break down because nobody asked whether the data was good enough for an agent to act on without a human catching the error down the line.
Link’s framing cuts through the usual data quality conversation: “Some lumber is good enough to be used for framing a house. Some lumber is good enough to be used for making a fine piece of furniture. But they’re not necessarily interchangeable.” An agent making operational decisions in a live workflow has a different data threshold than a dashboard or a lead scoring model and most organizations haven’t defined where that line sits.
What keeps data from reaching that threshold is usually a broken supply chain between the people producing it and the people consuming it. Link’s fix to this is to put both groups in the same room early, look at real samples, and ask whether what exists is sufficient for the specific problem the agent is being asked to solve. Agents end up acting on data nobody formally signed off on when that conversation never happens.
Boyle’s answer is infrastructure. His team builds mastered golden records that sit underneath every agentic development initiative, from dashboards to fully autonomous agents. “We want to make sure that there’s no data integrity or data quality concerns,” he noted, framing it not as compliance, but as the prerequisite for trust.
“If you’re just assembling it, scrubbing it, fixing it, and then trying your model, it’s not gonna scale until you’ve got the data problem solved,” Link said. Nothing built on top of it will change that.
Agentic Production Rewards Discipline
Boyle and Link aren’t dealing with better models than everyone else. They’re dealing with the same technology and getting different results because they built the conditions for it to work. Autonomy earned through checkpoints, not assumed. Agents treated as accountable team members, not black boxes. Data validated against the specific threshold an agent needs to act on it, not a generic quality standard. Use cases chosen because they solve a real problem, not because AI is having a moment.
This is the work that separates a demo from a production system and based on where most organizations still are, it’s the work that’s most worth doing.
Watch the full webinar to hear the complete conversation, or reach out to BairesDev to talk through what operationalizing agentic AI looks like for your organization.




