

Most enterprises now have access to the same AI infrastructure that was once exclusive to hyperscalers. The data platforms are powerful enough and the models are capable enough. During a live poll at a BairesDev webinar, 46% of attendees responded that their data platform’s primary role is still analytics and reporting. Zero percent selected machine learning and AI development. A decade of platform investment put AI-grade infrastructure within reach of most enterprises. The poll made visible what that access alone doesn’t solve.
That gap was the throughline of Building AI Apps on the Databricks Lakehouse, a webinar hosted by BairesDev Fellow Brett Berhoff, Founder and CEO of Strategy.xyz. Joining him were Jody Mulkey, Chief Technology Officer at First American, JT Hwang, Chief Technology Officer at GoodLeap, and Ayman El-Ghazali, Senior Solutions Architect at Databricks. Between them, the panel brought perspectives from regulated industries, large-scale IoT ecosystems, sustainable home financing, and enterprise platform architecture.
The conversation took the Databricks lakehouse as its starting point. Several panelists are active Databricks customers, and the webinar opened with a discussion of how enterprise data platforms are evolving beyond their original analytics and reporting role. But the panel moved quickly past the platform layer. The more urgent territory was everything organizations need to build around that infrastructure before AI applications can run in production. They discussed the readiness gaps most teams haven’t addressed, the foundational and architectural work that makes production sustainable, and where the real returns are waiting.
The Capability Gap Closed, but Most Engineering Teams Weren’t Built for What Came Next
Until recently, the capability to process raw data at scale and turn it into real-time operational decisions was concentrated in companies with hyperscaler-level engineering resources. JT Hwang put it plainly. For what he called “the other 99%,” that capability simply wasn’t available.
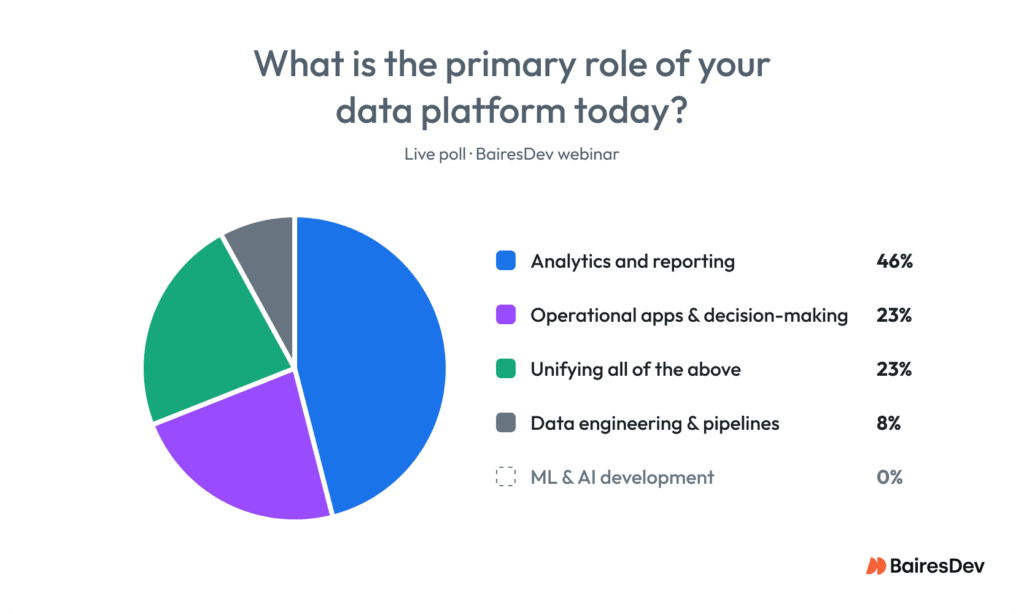
The webinar’s live audience reflected that gap. Nearly half said their data platform’s primary role is still analytics and reporting, and not a single respondent selected machine learning and AI development. Platforms like Databricks changed that. Enterprise-grade AI infrastructure is now accessible to organizations that never had the resources to build it from scratch. The bottleneck moved with it. Access to the platform is no longer the constraint. The defining factor for success is whether their teams are equipped to build on top of it.
Jody Mulkey sees this up close. He described how his 2,000-person technology team started building AI-driven applications about two and a half years ago, and how quickly it became clear that most software engineers in corporate IT have spent entire careers on deterministic, rules-driven systems. Building systems where outputs are probabilistic and non-repeatable requires a fundamentally different mindset, and that mindset doesn’t exist at scale in most engineering organizations.
First American’s answer was architectural. Rather than trying to retrain the full engineering team on non-deterministic design patterns, Mulkey’s team embedded those capabilities directly into the platform. Evaluation harnesses, experimentation frameworks, and guardrails are baked into the infrastructure so engineers who don’t yet have deep experience with AI can still build production-grade applications. “It just wasn’t scalable to teach all the humans,” Mulkey said. “We wanted to have a platform so that we could democratize this building of agents across the enterprise.”
The pattern tracks across the panel. The technology is ready, but the organizational muscle to operate it is still being built.
Before Agents Can Act, the Data and the Rules Have to Exist
Once an organization decides to move AI into production, the natural instinct is to start building, but the panel’s experience suggests the opposite. The work that matters most happens before an agent touches a workflow.
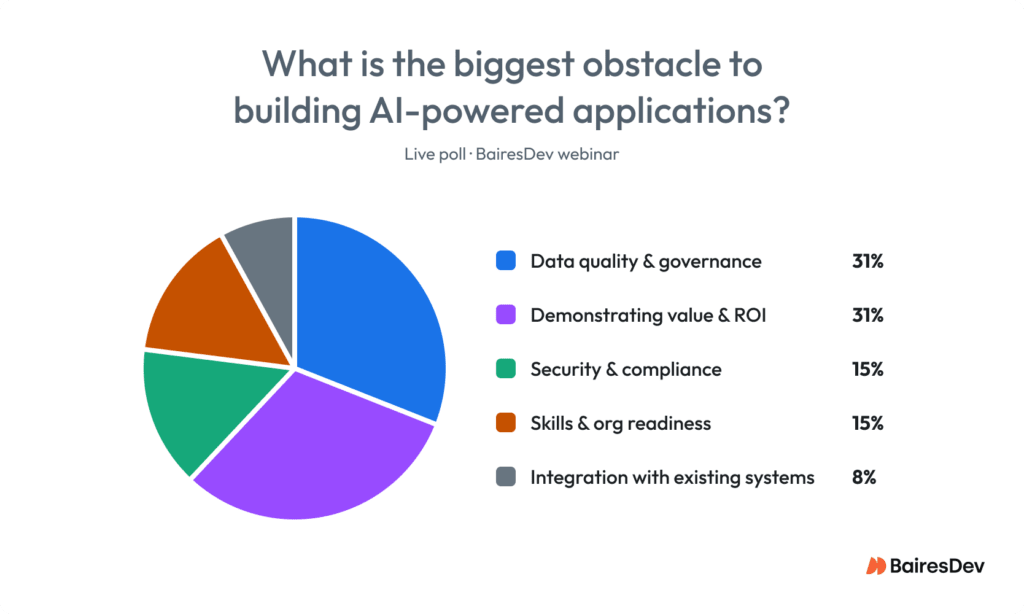
The audience named the same obstacles. Data quality and governance tied with demonstrating business value and ROI as the biggest obstacles to building AI-powered applications, each at 31%. The panelists spent most of their time on the first of those two.
JT Hwang grounded this with an example from GoodLeap. His company manages a fleet of home batteries. If you ask how many batteries they have you’ll get four different answers depending on what you mean. Are you talking about active versus inactive, remotely manageable versus not, controllable versus not? A human on the team would ask a clarifying question before responding, but an AI agent doesn’t quite have that instinct. “People have this natural-born common sense to go, oh, I want to understand why you’re asking so I can give you the right answer,” Hwang said. “AI doesn’t have that.”
Hwang described GoodLeap’s response as building a semantic layer underneath the AI. “One consistent definition for every business concept, domain by domain,” he said. Without it, agents interpret ambiguous data with full confidence and no awareness that alternative interpretations exist. The investment isn’t glamorous, but Hwang sees it as non-negotiable. Data feeds AI, and if the definitions underneath are inconsistent, everything downstream inherits that inconsistency.
Ayman El-Ghazali sees the same problem across a wider sample. As a Solutions Architect at Databricks, he’s worked with hundreds of customers, and the data quality gap shows up in patterns most teams don’t catch until production. “I’ve worked in places where they’re doing averages of averages for numbers,” he said. “That’s not an acceptable way to do mathematics on the base level.” The errors aren’t exotic — they’re mundane, and when agents inherit that data without a human catching the inconsistencies, the consequences scale with the automation.
Jody Mulkey framed the second prerequisite just as directly. First American operates in a heavily regulated industry. They own a bank and are regulated by the Federal Reserve Board, among other regulators. Mulkey’s team brought legal, compliance, and information security partners into the AI development process from the very beginning, before any building started. “You can’t add governance and compliance at the end. You have to start with it from the beginning,” she said.
JT Hwang reinforced the point from a different angle. Even before AI, he used to say that “the last 10% is 90% effort.” That rule still applies, and pilots don’t have to contend with it, which is part of why the jump to production catches teams off guard. Mulkey extended the logic by saying that missed requirements like compliance become exponentially more expensive to retrofit. Her approach is to get the team used to “running with 10-pound bricks in the backpack from the very beginning.” The weight is real, but it’s manageable if you start with it. Strap it on at mile eight and it stops the race.
Production Demands Architecture That Simplifies Governance
The panel discussed in depth the architectural decisions that separate teams sustaining AI in production from those still wrestling with governance after the build.
As agents take actions inside production systems, a practical governance question emerges. Who is accountable when an agent acts? That requires the agent to have some form of identity, and how that identity gets defined has major implications for complexity. Mulkey described a deliberate simplification. Rather than creating independent identities for AI agents, First American ties each agent’s permissions to the human who invokes it. “We’ve avoided this agent-as-its-own-identity problem,” he explained. “We basically leverage the identity of the human that’s invoking the agent as the set of entitlements. It dramatically simplifies things.” He acknowledged that independent agent identity will likely become necessary at some point, but the calculus right now is clear: “There’s a lot of value to be gained before we introduce that level of complexity.”
Hwang arrived at a similar principle from the data access side. At GoodLeap, the question is how to enforce attribute-based access control when agents are handling PII. “Not everyone, not every agent can have access to all the data,” he said. “This is a hard problem. It sounds really trivial, but it’s really, really hard when you’re dealing with PII.” His team found that prompt-level guardrails alone aren’t sufficient. “You can absolutely reduce the risk with the right prompts and the right things, but unless you cut it off at the data layer, you’re exposing yourself to a lot of risk.”
Controlling what agents can access is one side of the production equation. Knowing whether they’re making the right decisions over time is the other. Mulkey was direct about what makes production survivable when the ground shifts: “Evaluations will set you free.” He described a concrete case. First American built one of its early products on an OpenAI model that was later deprecated. The team had to revalidate the entire workflow on a new model. Because they had invested in strong evaluation harnesses early, the migration was manageable. Without them, a routine model change would have forced a near-rebuild.
That investment also shapes ongoing operations. Mulkey described the evaluation layer as the mechanism that gives his team continuous confidence that agents are making the right decisions given the right parameters, both at launch and over time, as models evolve and workflows expand.

Workflow Redesign Is Where the Real Value Lives
Once the foundations are in place, the next challenge is capturing the returns those foundations were built for. The panel converged on an insight that most organizations haven’t fully internalized yet.
Mulkey noted, “You can automate tasks, and you’ll get some value, but until you kind of rethink the process, you’re not really going to get the full value,” he said. “A person’s job is not one task, it’s not 10 tasks, it’s a collection of tasks.” Speeding up individual steps inside an existing workflow yields 20 to 40 percent productivity gains. Redesigning how the work moves yields multiples.
He pointed to a quality control operation at First American as proof. Fifteen people had been performing QC on client deliverables, covering about 37% of volume and prioritizing the pickiest clients. After reimagining the process around AI, five people now cover 100%. And in one product line, the team found where AI doesn’t miss, and this is where humans occasionally skip steps or lose focus. The AI applies the same scrutiny every time.
Hwang framed the same principle at a higher altitude. “A lot of our workflows are what they are because of human limitations,” he said. “If you remove that, you should change the way you do work.” He compared current efforts to integrate AI into existing processes to building a faster horse. The companies that succeed will be the ones that invent the car.
Mulkey saw the proof closest to home in her own engineering organization. The gains from AI-assisted coding were real but incremental. The teams seeing transformative results changed how product development works end to end: building specs and managing agents that write the code, rather than writing it themselves with AI suggestions alongside. “The ones that have evolved their workflow are the ones that get the most success,” she said. “The ones that are trying to shoehorn these new superpowers into their existing process are the ones that get marginal gains.”
The Platform Is Ready. Build the Conditions Around It.
None of the panelists focused on a technology bottleneck. The infrastructure is accessible, the models are capable, and the use cases are proven. What came through in every part of the conversation is that the harder, more consequential work sits around the platform. hat means getting data clean with unambiguous definitions, embedding governance before the first line of code, designing architecture that makes accountability simple, and being willing to redesign workflows instead of automating the old ones.
Watch the full webinar to hear the complete conversation, including audience Q&A on scaling AI in production and navigating organizational readiness. And if your engineering team is ready to move from pilot to production-grade AI, reach out to BairesDev to talk through what that looks like with the right talent and infrastructure in place.




