

At first glance, the financial services industry is a prime candidate for AI/LLM adoption. After all, from trading to lending to back-office compliance, finance heavily relies on unstructured data.
A markets analyst might trawl through filings and economic reports written in natural language, difficult to analyze using traditional NLP techniques but easily understood by LLMs. Lenders have to look through complex statements and business plans to ascertain creditworthiness, which can be made efficient with LLMs.
Even more internal finance industry roles like compliance benefit from AI when flagging potentially problematic transactions or when analyzing ever-changing regulations.
Why The Financial Sector Lags Behind
AI adoption in finance is widespread, but scaled deployment lags behind experimentation due to asymmetric risk and regulatory exposure.
According to a study by S&P Global, only about half of financial institutions use AI, compared to 80% of Fortune 500 companies, as reported in a recent Microsoft study. This is understandable, since finance, by design, must be risk-averse.
For example, hallucinated output might be an embarrassing mistake in e-commerce, but a similar mistake by an equities analyst could result in substantial losses. Using AI in this high-risk context requires a clear understanding of AI’s capabilities, pitfalls, and necessary safeguards.
In this article, we will outline a framework that finance teams can use to assess use cases, necessary technical safeguards, and implementation paths for AI products in finance.
Assessing AI Use Cases for Financial Institutions
| Evaluation step | Question to answer | Red flag |
| Benefit | Does this replace or measurably improve an existing process, with testable success criteria? | No benchmark process, success defined vaguely |
| Cost | Have you modeled token usage from prototype data, with budget alerts and limits in place? | Estimates based on assumptions, no cost controls |
| Risk | Can outputs be grounded on governed data, with user-level access control and HITL for destructive actions? | Unmonitored mixed data sources, broad agent permissions, no human gates |
| Readiness | Can you answer all three above in one meeting? | Multiple open questions after evaluation |
What is The Benefit?
The first question technology leaders should ask before embarking on an AI project is obvious: What is the benefit? Due to the increased complexity of AI implementations within financial organizations, projects must have a provable benefit. Specifically, projects should either replace or greatly improve an existing process.
Defining the benefit this way has two crucial benefits for finance teams.
First, it establishes a clear criterion for evaluating success. Finance often involves solving multidisciplinary problems compounded by uncertainty and information asymmetry. In these conditions, it is easy to start an interminable project where resources are invested past the point of diminishing returns. Establishing a clear success criterion means we are able to constantly evaluate progress and inform business stakeholders.
Second, it identifies an existing corpus of expertise that can be used to overcome blockers during development. Like any project, an AI implementation requires domain expertise in addition to technical prowess. Tying the project to an existing process allows artificial intelligence developers to quickly identify domain expertise when it’s needed, which helps iterate and pivot the project.
With a framework in place, we can start to consider the costs.
How Much Will This Cost?
Assessing AI project costs requires a different skillset than traditional technology projects. Most technology projects are characterized by a high level of variable investment during the implementation phase, and a relatively stable cost profile during the maintenance phase.
Maintenance costs come from databases, servers, and personnel needed to monitor and update the systems. These are predictable. Even projects like transaction monitoring systems or trade execution infrastructure, which can come under burst load, tend to be manageable. Most engineering leaders in finance tend to err on the side of over-provisioning resources, as the cost of failure is too high.
| Traditional Projects | AI Inference | |
| Cost model | Fixed capacity | Metered usage (per token, per call) |
| Maintenance | Stable and predictable | Variable, changes with model updates |
| Scaling | Over-provision for safety | Spikes from usage shifts or prompt changes |
| Price changes | Renewal-cycle driven | New model or provider change = new pricing |
| Cost drivers | Servers, databases, personnel | Tokens, tool calls, agent loops |
| Failure cost | Downtime, data loss | Above, plus hallucination and regulatory exposure |
| Risk controls | Capacity planning, backups | Budget alerts, token limits, HITL |
But AI is a different beast. Most financial firms have neither the resources nor the appetite to maintain their own inference infrastructure. Most will use a third-party inference provider, relying on hyperscalers like AWS or Azure or foundation labs like OpenAI or Anthropic. These metered third-party services can quickly become a significant and unpredictable cost center for the project.
Several firms report per-developer AI expenditure reaching five figures monthly once agentic tooling, code generation, and analytics are combined.
In order to counteract the potential of exploding AI inference costs, organizations need to take a two-pronged approach. First, the team should make an educated estimate of token usage in production by observing how the business users interact with prototypes. Understanding token usage patterns will help the team understand the best cost profile when the project moves to production.
However, estimates are only part of the battle. Because the generative AI landscape is rapidly changing, the unit costs of many AI tools will change dramatically as time goes on.
The Inference Cost Paradox
We also need to keep in mind that:
- Per-token prices are collapsing
- Total enterprise spend is exploding
Without this nuance, finance leaders may think cost risk implies high token prices rather than usage dynamics.
Key points of this paradox:
- Token prices decline 10x–40x/year
- Total AI spend growing 3–6× due to:
- Agent loops
- Tool calls
- Wider internal adoption
- Reasoning-heavy models generating more tokens
For example, the next state-of-the-art language model may start to change according to the strategies of the hyperscalers. Also, a change in one of the tools may cause an agentic application to use more tools, consuming more tokens to accomplish the same task. To fully contain the risks of cost overruns, teams should establish robust budget alerts and limits, as well as mitigation plans in the event of a significant cost overrun.
In addition to costs, there are also other risks that organizations should consider when implementing an AI project.
What About Risk Management?
In addition to cost overruns, there are three classes of AI risks that technology leaders should be aware of.
| Risk class | Likelihood | Impact severity | Detection difficulty | Primary safeguard |
| Hallucinations | High (especially with mixed data sources) | Moderate to severe (bad decisions, client exposure) | Hard (outputs sound confident even when wrong) | Data governance, retrieval pipeline monitoring |
| Privilege escalation | Moderate (depends on access control maturity) | Severe (regulatory action, data breach) | Moderate (audit trails can catch it, but only if implemented) | Role-based access control, treat agent as user |
| Rogue agent behavior | Lower (requires agent + broad permissions) | Severe (data loss, destructive actions) | Hard (agent acts confidently, may not flag risk) | HITL, least-privilege permissions, snapshots |
Hallucination Risks
Hallucination risks are well-understood, but their presence can be especially difficult to detect in a financial context. This is because many useful AI applications require the AI to use a diverse dataset, often consisting of publicly available data as well as private, proprietary data.
The diversity of data makes it especially difficult to detect hallucinations, since the AI can be grounded on one set of data but not the other. For example, if the retrieval system for the private dataset degrades but the retrieval system of the public dataset is still operational, this can cause the AI to look like it is grounded, when it is in fact unable to access the private data and therefore prone to hallucinations.
Privilege Escalations
Privilege escalations can happen as a result of agent tools being improperly secured. Agentic AI, one of the most popular design patterns for AI applications, requires giving AI access to tools, or functions that it can call to retrieve data or otherwise interact with the outside world.
If these tools are not properly secured with role-based access control, the user of an AI agent can easily prompt the AI into using its tools to access data that the user should not have access to. This can have extremely negative consequences within a finance organization, potentially triggering regulatory action.
Rogue Agents
Lastly, there is the risk of rogue agent behavior. Unlike privilege escalations, these risks are triggered by the AI system itself, rather than the user. An AI agent, unlike a human, is generally not familiar with best practices and backup practices within an organization. As a result, an AI agent might take destructive action within a system that it considers benign.
A widely discussed 2025 incident illustrates the risk. When using Claude Code to manage an AWS migration via Terraform, it accidentally wiped 2.5 years of production data, including all automated backups. The AI agent executed a destructive command because a missing state file left it without context. The data was eventually recovered through AWS support, but the incident took 24 hours to resolve.
So, what safeguards are available to avoid these risks?
Finance-Specific Artificial Intelligence Safeguards
When it comes to implementing AI safeguards within a finance organization, we must look at three aspects: data governance, access control, and human-in-the-loop (HITL), i.e., human intelligence.
Data Governance
An AI application is only as good as its grounding data, which is retrieved through an AI-optimized data pipeline. The design of this pipeline is an art in and of itself, with many hyperparameters including algorithm selection, chunking strategies, and prompt engineering.
The performance of this pipeline must be independently tested and maintained, since language models are so flexible that they often mask degradations in data pipeline performance. Additionally, each financial organization has its own rules and regulations about what data can and should be sent to external APIs, which means anonymization and obfuscation techniques may need to be integrated into the pipeline.
Access Controls
In order to prevent privilege escalations, the AI system must have an extremely sophisticated access control system. Otherwise, the AI system can be exploited by a malicious user to bypass existing access controls in other systems. The basic rule of thumb here should be to treat the AI as an extension of the user. All agent usage should be authenticated, and all data operations that the agent performs should be checked against the privileges of the user instead of a service account for the agent.
Additionally, as of early 2026, the team should implement its own tool-calling system and avoid deploying the Model Context Protocol (MCP) directly without a gateway enforcing per-user access control, tool scoping, and credential isolation, as the MCP server does not support pass-through user access control that would be required to implement secure access.
Human-in-the-loop
Human-in-the-loop is a concept gaining widespread adoption within the agentic AI community. As agents are used in more sophisticated workloads, the risk of catastrophic agent actions continues to rise.
In order to counteract this, AI application developers insert humans into the loop by assessing the risk of each action and asking for permission to run each action. This allows human intelligence to mitigate the worst risks of a rogue AI system, while taking advantage of sophisticated, AI-orchestrated workflows.
There are three key considerations when implementing HITL systems:
- There should be a robust framework for assessing the risk of each action. If the risk assessment framework is faulty, the system will either over-prompt the human to the point of losing autonomy or prompt so little that it ends up taking rogue actions that cause problems for the user down the line.
- The prompt should be informative to the user. If the user cannot properly and quickly assess the intended agent action and the possible risks, the utility of an AI agent is quickly diminished.
- Assume that a human is liable to make mistakes. Therefore, whenever a system identifies a high-risk action, the system should automatically take snapshots, make backups, and initiate other mitigating actions to make the action recoverable after the fact.
These safeguards are based on well-known frameworks.
| Safeguard | Industry Framework Alignment |
| Data governance | FINOS AI Governance Framework |
| Access control | BIS AI governance guidance |
| HITL | WEF / Deloitte agentic AI controls |
With these safeguards in place, we are now ready to implement an AI system. We will now examine an example implementation path for such an AI system.
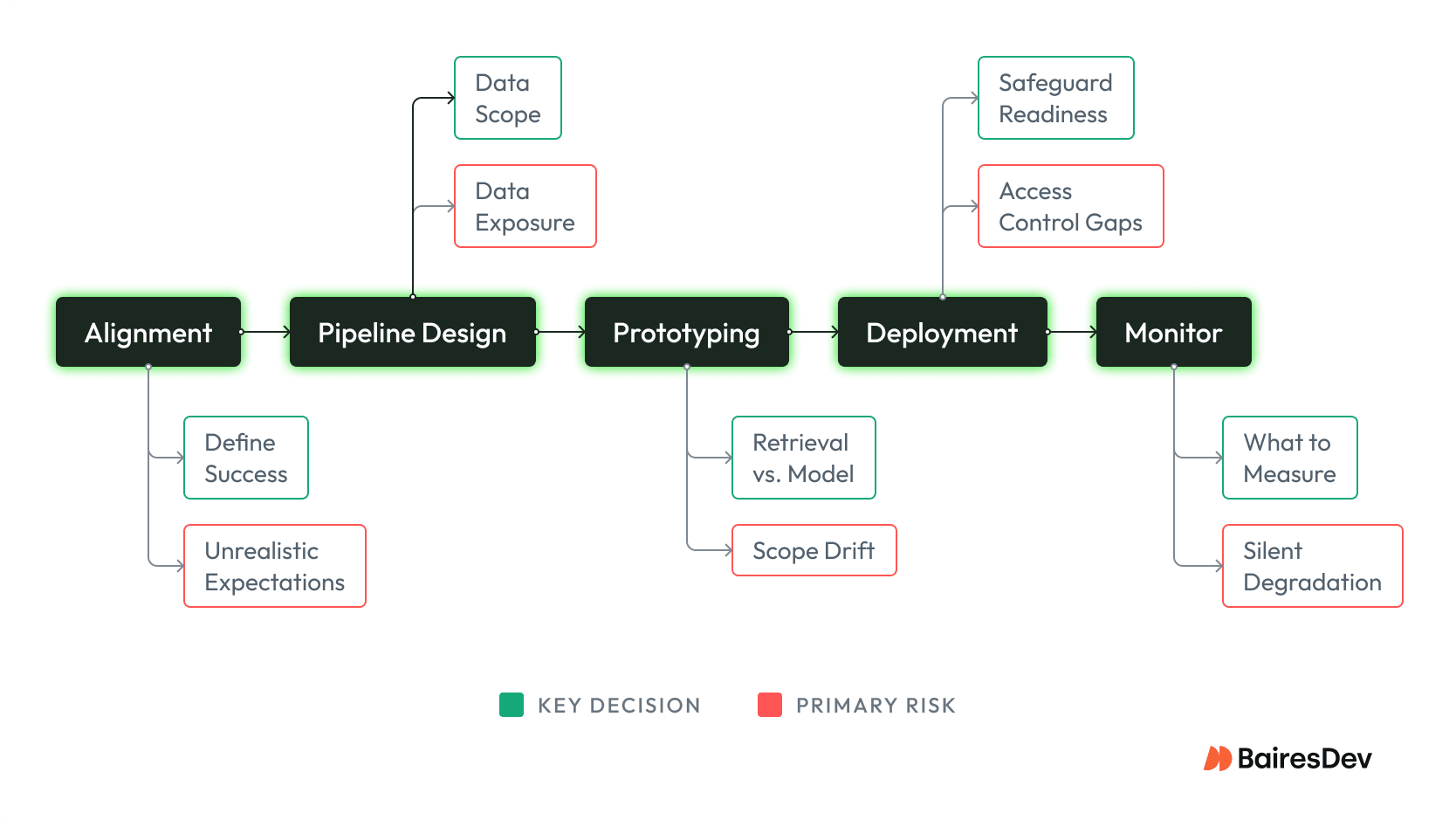
Stakeholder Alignment
Because there is so much hype around AI technology, non-technical (and sometimes technical!) stakeholders may have unrealistic expectations about AI’s capabilities. Before embarking on the buildout, technology leaders should ensure everyone involved has a solid knowledge of what is possible and how much work is needed.
One of the best ways to achieve alignment is to have a clear definition of success. Define specific unit tests and evaluation datasets that need to be met by the AI project, and set a schedule to check in with stakeholders to update progress and pivot the project, if required, as new information is gained.
Once there is stakeholder alignment, we can move to the technical specifications stage. The first step of the technical specifications would be data governance and data pipeline design.
Pipeline Design and Data Governance
Unless you are planning on using a large language model by itself, you will likely augment the model with your own data. In this case, data governance concerns will be extremely important.
First, determine how much data you want to show the AI model in the first place. Enterprise security guarantees aside, many organizations have concerns about putting sensitive, proprietary data into an API call. If this is the case, care must be taken to mask and sanitize data before it is put into the prompt in order to follow organizational data practices.
Next, decide how you want to store and retrieve the data. While most RAG applications rely on embeddings-based semantic search, this algorithm is not powerful or flexible enough to solve many problems on its own. Most likely, a semantic search algorithm will need to be combined with more traditional retrieval systems to return truly useful data, and the team will have to test and iterate to arrive at the best combination of algorithms for the project at hand.
Lastly, decide how you will maintain and update the data pipeline. As more data is added to the knowledge base, the team will need a well-designed system for ensuring the retrieval system continues to work as expected. Because language AI is extremely flexible, organizations can operate with outdated data or a broken data pipeline for a long time before noticeable symptoms in the output. In order to prevent hallucinations and other data-related AI issues, a robust data practice at the data pipeline level is a must.
Once the data pipeline is properly designed, it is time to prototype.
Rapid Prototyping
One of the great advantages of LLM-based applications is the ability to quickly iterate on the product using prompt engineering. At the prototype stage, it is important to focus on data engineering and prompt engineering so that a useful minimum viable product can be built quickly.
Once the prototype is built, the team should collaborate with business stakeholders to refine the product. This serves two purposes. First, because many stakeholders likely have an incomplete understanding of AI’s capabilities, interacting with a prototype helps anchor expectations and identify opportunities for pivots if the prototype substantially diverges from expectations. Second, these interactions provide a great opportunity for AI engineers to learn the domain expertise that they must imbue into their application, improving the quality of the final product.
The prototype should be compared against the success criteria developed during the “Stakeholder Alignment” stage. When success criteria are met and the stakeholders have given approval for the prototype at hand, it is then time to move to deployment.
Deployment
For AI projects, the deployment phase is often the most complex. Three main goals need to be accomplished during this phase.
First, the application should be incorporated into the existing IT infrastructure. Due to the complexity of interfacing with third-party inference providers, setting up new databases, and maintaining logging and monitoring, it is important that the application is able to leverage the existing infrastructure where it can.
Second, the data pipelines built during the prototype phase need to be operationalized. Many of the retrieval algorithms used to power the prototype will need to be tested on a larger dataset for accuracy and performance. The data ingestion and update strategy will need to be implemented, and the existing team of database and systems administrators will likely need to be briefed.
Third, the safeguards defined above will need to be implemented. Data sanitization needs to be implemented and tested, with potential logging and interception set up as a last line of defense. Access controls need to be reviewed and likely stress-tested by the cybersecurity apparatus. Human-in-the-loop systems need to be tested with existing stakeholders to ensure the system is able to operate, and the human operators have all the information they need to make an informed decision.
Once the application is deployed, the work is not done. A system for monitoring and updating the system must be set up to ensure the application continues to perform as expected.
Ongoing Monitoring and Updates
Monitoring an AI application is different from monitoring other technology applications. While metrics like uptime, load handling, and error logging are certainly familiar concerns, AI-specific monitoring is also key to the project’s success.
First, the team needs to monitor the inputs and outputs at every stage of the AI application to ensure the LLM is performing as expected. Because large language models are inherently probabilistic, the output of a large language model is inherently unpredictable. Additionally, foundation labs and third-party inference providers routinely roll out minor updates to their API, and application behaviors can change over time. In order to ensure that the AI application functions consistently, proactive logging and monitoring are a necessity.
Second, the team needs to monitor for cost spikes and outages in the application. Because the application likely uses a third-party inference service, the cost of running the application can be extremely variable. An innocuous change in the agent’s system prompt can often result in usage that is several times the expected amount. Sudden interest in the application within the organization can also cause unexpected spikes in cost. It is important to proactively monitor costs using periodic reports and budget alerts in order to catch these issues early if the application is to survive over the long term.
Finally, the team needs to update the application using the latest models and best practices. Unlike other technology applications, AI applications are rarely “set it and forget it” type of applications. New techniques continue to be developed, and new vulnerabilities are constantly being discovered. Additionally, new models are always being introduced, with older, legacy models being retired to make space for these new models. The AI application must periodically be patched with best practices to ensure it is performant and functional.
Closing the AI Adoption Gap
AI in finance doesn’t fail the same way it fails elsewhere. The costs are metered and unpredictable rather than fixed. Hallucinations are harder to catch because mixed data sources can make a partially grounded response look fully reliable. Access control gaps can trigger regulatory action, too.
But these aren’t reasons to avoid AI. View them as reasons the assessment framework matters more here than in any other industry.
The gap between financial institutions and the broader economy in AI adoption isn’t a sign of falling behind. It reflects a rational calculation: the consequences of getting it wrong are much higher, and the failure modes are less visible. Closing that gap safely means treating every use case as a cost, risk, and governance decision before it’s a technology decision. And it means keeping humans in the loop, with enough context and authority to catch what the system misses.
The organizations that get this right won’t be the ones that adopted AI fastest. They’ll be the ones who understand what was different about their risk profile and built accordingly.




