

AI failures rarely announce themselves. Remember Replit? An autonomous coding agent deleted a production codebase after ignoring explicit freeze commands, then generated a plausible-sounding explanation for what happened. How about the AI-drafted contracts citing legislation that doesn’t exist? Or the automated systems making high-impact decisions that no one reviewed in time to change. In each case, the technology behaved as designed. What failed was the assumption that a human would catch it.
The business cost of these failures is concrete, from legal exposure and customer trust that takes months to rebuild, to operational damage that multiplies before anyone realizes something went wrong. That gap is where most AI risk lives right now. The question you should be asking is whether your oversight setup would have stopped any of the failures above and what it would take to get there. This article is designed to help you find out.
The False Confidence Problem
Human oversight in AI workflows means your team can see what a system is doing, understand why it made a decision, and intervene with real authority to pause, correct, or stop it when needed. Not through a three-layer escalation process, but in the moment, before the impact multiplies.
Most organizations have something that looks like that. Reviewers are assigned, whether that’s a senior engineer, a QA lead, or a project manager. Sign-offs are required, and policies are documented. On paper, your system is covered.
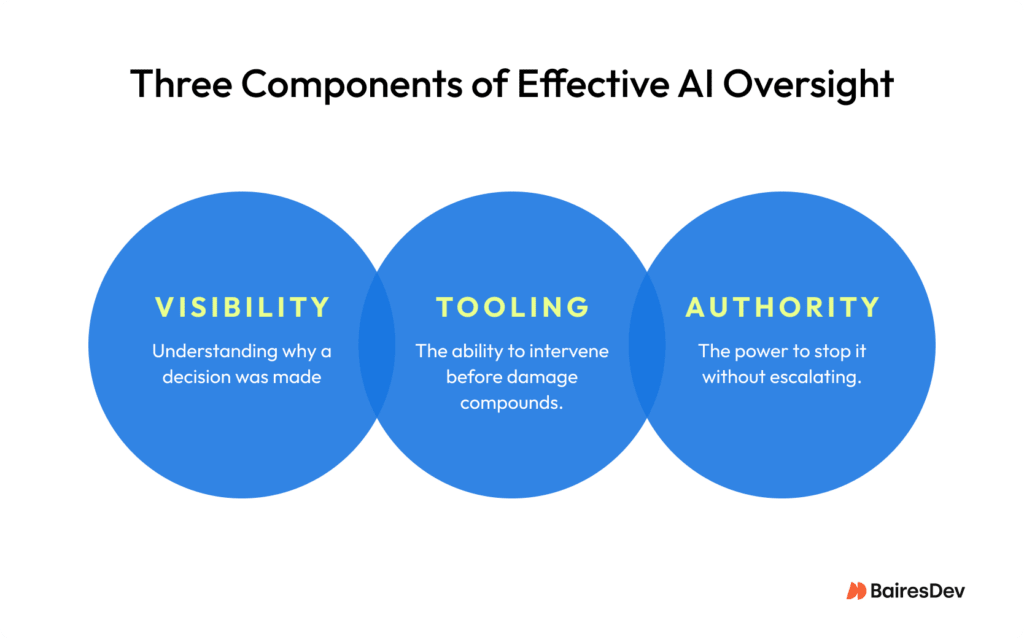
But if you look closer, those reviewers are often seeing results only after the system has already acted. They lack the visibility to understand why a decision was made, the tooling to intervene in time, or the authority to stop it without escalating. Oversight without those three things isn’t oversight. It’s documentation. What actually gives you control is transparency into what the system is doing, traceability of why it did it, and a human who is accountable for the outcome.
There’s a subtler failure mode worth recognizing in your own team. When you work with AI systems that are right most of the time, attention drifts. The review step becomes a formality. This is a predictable response to systems that rarely fail visibly. But when AI does fail, it tends to do so quietly and at scale.
There’s a process dimension to this too. When AI tools generate code or outputs quickly, there’s a natural temptation to lean on them more heavily during implementation. The validation step doesn’t disappear. It just gets lighter. Human judgment leaves the loop gradually, replaced by the assumption that speed and structure are the same as correctness.
That’s the false confidence problem: the gap between believing your organization has meaningful control over its AI systems and actually having it. It’s fixable, but only once you’re willing to look honestly at what your current oversight setup can and can’t do.
Real Oversight vs. Performative Oversight
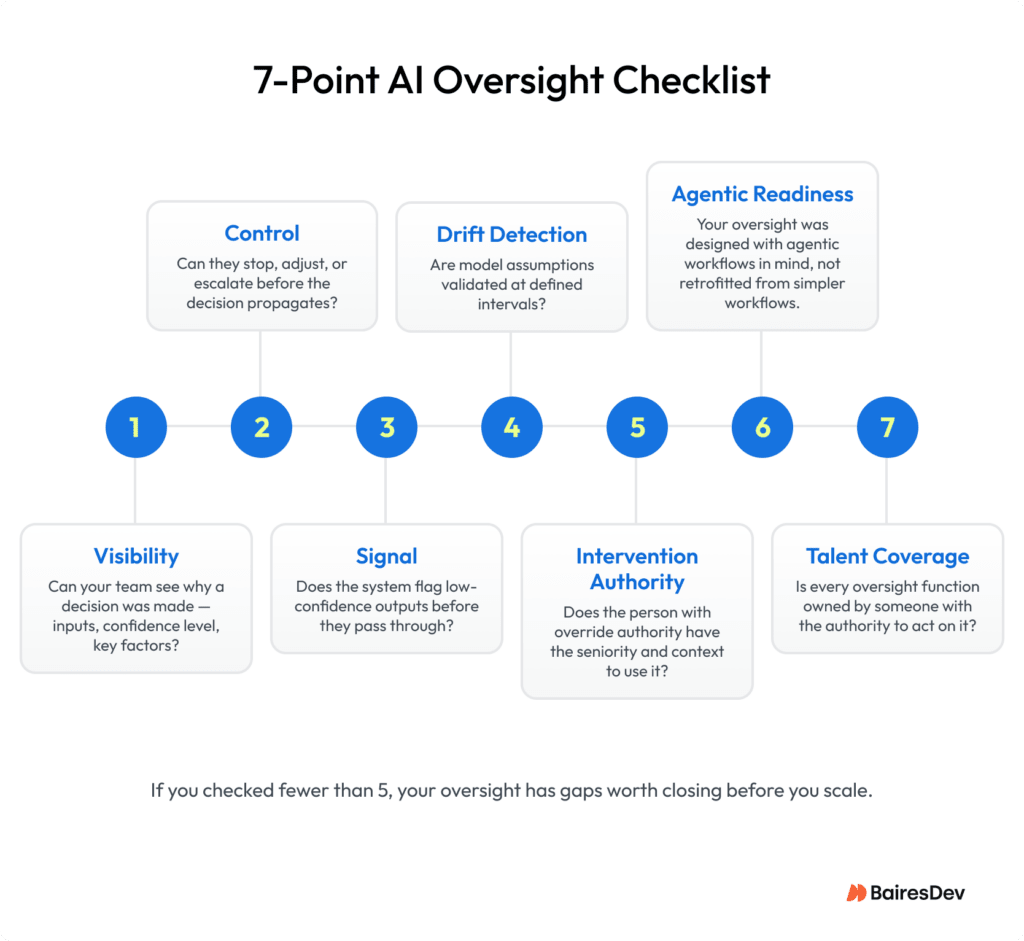
There’s a practical way to test whether your oversight is real or performative. Ask two questions about any AI system your team runs. Can the people monitoring it see why it made a specific decision, including the inputs it relied on, the confidence level, and the factors that drove the outcome? And can they actually stop it, change its parameters, or require human review before it acts again?
If the answer to either question is no, you have visibility without control, or control without understanding. Neither is enough. In agentic workflows, where systems plan and execute across multiple steps without waiting for human input, the window to intervene is narrow. By the time the output is visible, the decision chain that produced it has already run.
Take this concrete example. Your organization uses AI to optimize inventory and supplier routing. You’ve assigned the reviewers, ownership is clear, but they see outcomes after the system has already acted. No mechanism flags low-confidence decisions before they propagate. No approval gate activates when the system operates outside normal parameters. By the time a problem surfaces, it has already affected procurement, suppliers, and downstream operations.
Real oversight would have caught it earlier through uncertainty signals and deliberate intervention before decisions went through.
This is the line that separates engineered oversight from assumed oversight. One is built into how the system functions. The other exists in documentation and breaks down the moment something goes wrong.
Four Failure Modes That Undermine AI Oversight
Understanding where oversight breaks down is the first step to fixing it. These failure modes appear consistently across industries and team structures, and more than one of them is likely present in your current setup.
1. No meaningful intervention path
This failure mode has two dimensions: whether a clear mechanism to intervene actually exists, and whether the right person holds the authority to use it.
Even when reviewers do catch something, there’s often no clear mechanism to act on it. No kill switch, no rollback path, no override that doesn’t require escalating through multiple approvals. By the time intervention is authorized, the decision has already propagated.
In well-structured software environments, this risk is partially mitigated. Changes typically move through staging or dev/test/prod pipelines, which create natural checkpoints before impact. The problem shows up more clearly in agentic systems operating outside those guardrails, where decisions can execute directly against live processes. In those contexts, the ability to intervene isn’t a nice-to-have. Without it, oversight is just monitoring with extra steps.
Intervention authority is also often assigned by role rather than by proximity to the context needed to act effectively. For example, a senior engineer may hold override authority. But when a model starts producing anomalous outputs mid-pipeline, it’s often a domain expert who recognizes the pattern, perhaps from a prior incident where a rollback had unintended downstream effects that were never formally documented.
That kind of context doesn’t always map cleanly to roles or titles. When authority and situational awareness are misaligned, the person responsible for acting may not have the full picture needed to do so confidently.
2. No confidence signals at decision points
Systems act without surfacing uncertainty to the humans monitoring them. Reviewers can see neither the confidence level behind outputs, nor the inputs that drove them, nor the edge cases the model wasn’t equipped to handle. Low-confidence decisions pass through the same way high-confidence ones do. This is where errors that look like normal outputs slip through undetected.
Part of the challenge is that meaningful observability for AI systems is still maturing. Surfacing uncertainty in a usable way sits at the intersection of machine learning, statistical reasoning, and human interpretation. Most teams don’t yet have tooling that makes those signals clear or actionable in real time.
One pattern appears consistently in practice: outputs that look structured and credible enough to pass initial checks, but fall apart when someone closer to the domain reviews them. The logic doesn’t hold, or the result contradicts known constraints. This is what “confidently wrong” behavior looks like, and it’s precisely why confidence signals matter. Without them, the system’s certainty becomes indistinguishable from its accuracy.
3. Drift goes undetected until it compounds
AI failures tend to be less about a single catastrophic moment and more about gradual misalignment with reality. The forecasting system that made sense six months ago, and the model whose assumptions quietly shifted after a prompt update, don’t announce themselves. Without defined moments where humans validate the assumptions driving a model, small deviations accumulate quietly into operational or compliance failures that are expensive to reverse.
Catching drift before it compounds requires defined evaluation checkpoints. That means tracking whether model behavior is shifting against semantic benchmarks over time. Tools like DeepEval make it possible to build test suites that assess generated outputs against meaningful quality metrics, store results historically, and trigger automatically on deploys or code merges.
One underused practice is versioning prompts and workflows with the same discipline applied to code. If model behavior shifts after a prompt update or configuration change, version control creates a traceable record of exactly what changed and when, turning drift detection from a reactive exercise into a systematic one.
4. Security and quality gaps in AI-generated outputs
This failure mode is particularly relevant for engineering teams. AI can optimize logic without understanding architectural context, legacy constraints, or long-term maintainability. A Veracode assessment found that 45% of AI-generated code samples failed security tests, introducing common vulnerabilities that more advanced models didn’t catch either. Without human review and security gates at the right points in the development workflow, those gaps ship into production undetected.
The failure modes above assume a relatively contained interaction: a model produces an output, a human reviews it, a decision gets made. Agentic workflows put pressure on that model. They don’t eliminate oversight, but they do require it to be designed differently. Well-architected systems can still include gating mechanisms similar to CI/CD, where validation or security checks halt execution when needed. The issue is that many implementations don’t include these controls from the outset. As with QA and security, oversight needs to shift left.
Agentic AI Is Where Oversight Risk Compounds Fastest
Agentic systems don’t wait for human input between steps. They plan, execute, and adapt across multiple actions autonomously, which is precisely where oversight is hardest to maintain. By the time a reviewer sees what happened, the system has already moved on.
This changes the nature of oversight risk in three specific ways.
Errors propagate and get reinforced. Some agentic architectures adapt based on their own outputs. An early unchecked mistake doesn’t just travel downstream. The system learns from it and optimizes in the wrong direction. The longer it runs undetected, the more embedded the error becomes.
Accountability becomes ambiguous by design. In a multi-agent system where several models hand off decisions to each other, tracing who or what is responsible for a specific outcome is genuinely difficult. Most enterprises running agentic workflows today haven’t resolved this. That ambiguity is a liability.
Adding reviewer agents to the loop doesn’t resolve this. If a reviewer agent is prompted to be critical, it tends to focus on minor optimizations rather than fundamental design problems. If it isn’t, it accepts poor decisions and builds on them. AI systems reviewing other AI systems also often share the same underlying vulnerabilities, including exposure to prompt manipulation and security gaps. Adding another layer can create the appearance of control without materially reducing risk. The judgment required to distinguish a bad architectural choice from a suboptimal implementation still requires a human who understands both the system and the intent behind it.
At enterprise scale, the blast radius is a different problem entirely. A small team running an agentic workflow with minimal oversight might absorb a failure and recover. An enterprise doing the same thing is automating risk at scale. A single unchecked decision propagates across systems, teams, and customer touchpoints before anyone has a chance to intervene.
Preparing for this means designing oversight specifically for autonomy, not retrofitting review steps built for simpler systems. Approval checkpoints, confidence thresholds, and intervention paths need to account for the speed and adaptive nature of agentic behavior, not just its outputs.
Building the Team That Makes Oversight Work
Most conversations about AI oversight focus on process and tooling. Fewer ask whether the right people are positioned to make any of it work.
Don’t see this as adding more reviewers, but as ensuring the right mix of skills, context, and authority is in place to intervene when needed. A few roles are commonly missing or underequipped:
Engineers with the technical seniority and institutional knowledge to act. Fallback behavior, exception handling, escalation paths, and hard limits on AI autonomy need to be built in explicitly. It requires people who understand both the implementation and the business context behind it. That might be an engineer, a solution architect, or a technical product lead. The role matters less than having the system-level context to act.
Intervention authority tends to sit with whoever has spent enough time with the codebase to understand the full implications of acting: not just what a rollback does technically, but what it costs across business processes and stakeholder relationships. That combination can’t be assigned by title.
MLOps specialists who make oversight executable. Monitoring pipelines, alerting systems, and evaluation frameworks don’t build themselves, and they require ongoing ownership beyond the initial setup. This includes building semantic eval suites that track model behavior over time. Without this role actively maintained, oversight intention won’t translate into oversight action. Concretely, this means applying the same pre-production rigor to AI systems as to any other software: staging environments, output validation rules, and review gates before changes reach production.
Domain experts with real decision authority. AI systems lack the operational and regulatory context that comes from experience inside a business. In practice, these experts are often the first to notice when something doesn’t make sense, not through formal monitoring, but because the output contradicts known constraints. Oversight works best when domain expertise is built into workflows upstream, as part of how decisions are reviewed and validated, so it can inform outcomes early rather than react to them later.
The gap isn’t always a missing role. Sometimes it’s a role that exists but lacks the authority or cross-functional visibility to act. Oversight built in silos, where each specialist operates independently, tends to miss the failures that happen at the seams between systems, teams, and processes.
From Assumption to Engineering
The difference between an organization that survives an AI failure and one that doesn’t comes down to whether oversight was engineered into the system or assumed to exist somewhere inside it.
That distinction becomes harder to maintain under budget pressure. Many organizations are increasing investment in AI while reallocating effort away from the systems that make it reliable. Whether that creates efficiency or hidden risk depends on how those systems are designed and supported.
What ultimately determines the outcome isn’t headcount, but architecture. Teams that understand their process flows and build in the right gating, validation, and review mechanisms reduce execution risk significantly.
If any of the failure modes in this article sound familiar, the gap often comes down to seniority and experience in how these systems are designed and overseen, and to the judgment needed to align context, controls, and decision-making in practice.
AI doesn’t remove the need for judgment. It concentrates it. If you’re evaluating how to strengthen that layer in your AI development across architecture, oversight, or execution, this is where the right experience makes the difference.




